
DALL·E 3 is a text-to-image AI model you can use with ChatGPT. In this post, we will compare DALL·E 3 with Stable Diffusion XL to see what each model excels at.
Table of Contents
DALL·E 3
What is DALL·E 3?
DALL·E 3 is a text-to-image generative AI that turns text descriptions into images. The training and model architecture is described in the paper “Improving Image Generation with Better Captions” by James Betker and coworkers.
The major improvement in DALL·E 3 is the ability to generate images that follow the prompt closely. The authors found that the current text-to-image models do not follow prompts well because the captions of the training images are noisy. By using highly descriptive captions generated by a captioning model, they were able to improve the prompt-following ability of DALL·E 3 significantly.
Note that DALL·E 3 has other undisclosed improvements over the previous version. So, better performance does not all come from better captioning in training.
How to use DALL·E 3?
You will need to subscribe to ChatGPT Plus to use DALL·E 3.
Follow these steps to use DALLE3:
- Open ChatGPT.
- Tell ChatGPT to “Create an image with….”. Type a description of the image. ChatGPT will revise and expand your description and display the images generated with DALL·E 3.
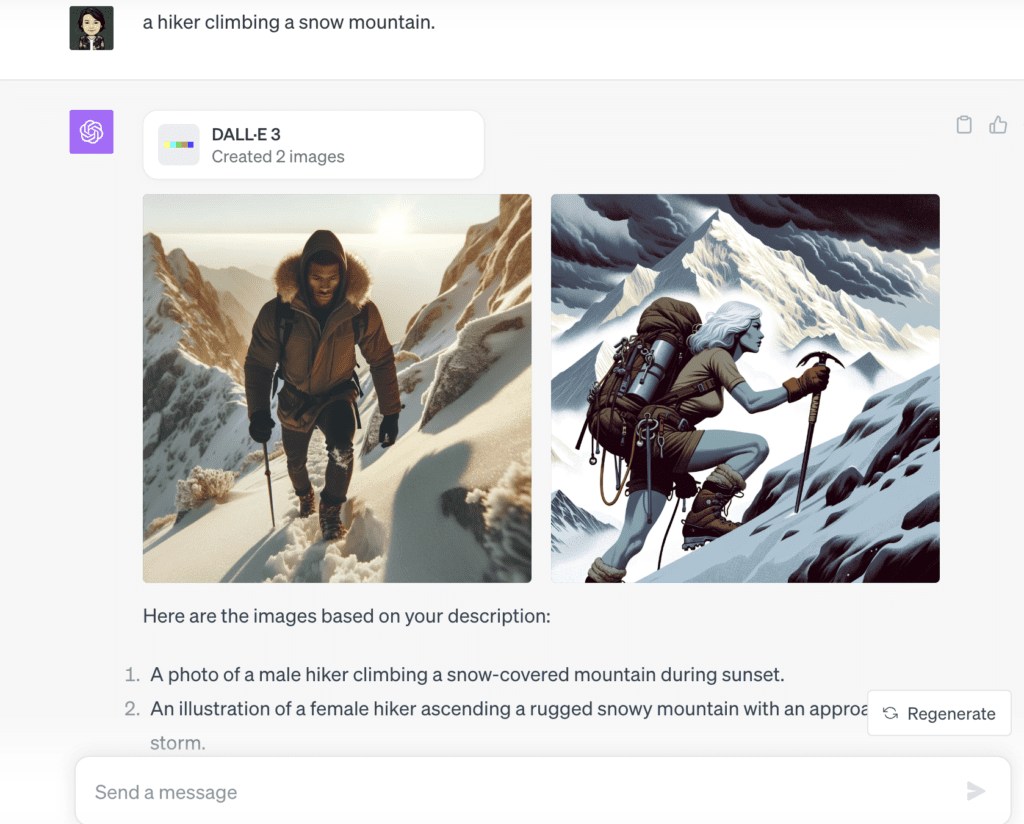
You then interactively tell ChatGPT which one you want to continue to modify. You can’t revise the prompt directly. ChatGPT acts as a middleman between you and DALLE 3. In addition to the prompt, you can ask ChatGPT to change the image’s aspect ratio.
Stable Diffusion
What is Stable Diffusion?
Similar to DALL·E 3, Stable Diffusion is a text-to-image generative AI model. It is a latent diffusion model in which image synthesis occurs in a smaller latent space. It has the advantage of being smaller and can be run on a personal computer.
How to use Stable Diffusion?
There are many options to use Stable Diffusion. For a free local option, you can use AUTOMATIC1111 Stable Diffusion WebUI. You can use this software on Windows, Mac, or Google Colab.
Check out the Quick Start Guide if you are new to Stable Diffusion. Check out the AUTOMATIC1111 Guide if you are new to AUTOMATIC1111.
DALL·E 3 vs Stable Diffusion XL
We will compare DALL·E 3 and Stable Diffusion XL 1.0 in this section.
Prompt following
The main improvement in DALL·E 3 is its prompt-following ability. In my testing, DALL·E 3 generates images that match the prompt much closer, by a wide margin. This agrees with the research article.
Test 1: Double helix
An aerial perspective of a vast forest landscape that forms a DNA double helix pattern, with rivers and clearings symbolizing its features.


Stable Diffusion XL doesn’t display a double helix pattern. The double helix pattern begins to appear when the keyword weight of “DNA double helix pattern” is increased to 1.2, but the blending is subpar.

Test 2: Nuclear war
A photo of a young boy and girl holding hands, witnessing the aftermath of an atomic bomb detonation from an elevated vantage point.


Both images are faithful to the prompt, but I would rate DALL·E 3 more accurate because the couple stands at an elevated viewpoint which is what the prompt specifies, and the atomic bomb is closer to the public’s imagination.
Text rendering
Although Stable Diffusion XL represents a quantum leap in rendering text, it performs worse than DALL·E 3, in my opinion.
Test 1: Billboard
An illustration of a vibrant billboard sign emphasizing the message “Stable Diffusion XL is better than DALLE 3” with radiant light beams.


Test 2: Hiking sign
A female hiker triumphantly reaching the summit with a wooden sign reading “Get High”.


Stable Diffusion XL is doing better with short phrases. This shouldn’t be a surprise for anyone. But I would still rate DALLE 3 better.
Styles
Stable Diffusion has an advantage in rendering a variety of styles. It generates realistic photos better than DALLE 3 out of the box, not to mention you can use community-developed models fine-tuned for realistic images.


Even if the Stable Diffusion base model does not perform, you can likely find a fine-tuned model to render the style you want.
Here’s another comparison for an impressionist painting style.


Inpainting and outpainting
Inpainting regenerates a small part of the image while keeping everything else the same. Outpainting extends the image while keeping the original image.
As of writing, DALLE 3 is not capable of both. For example, asking DALLE 3 to outpaint an image changes it completely. Stable Diffusion can do both and is clearly the winner here.

Prompting
You cannot directly control the prompt for DALLE 3. You tell ChatGPT what you want to draw, and it edits the prompt for you. This is both good and bad. It is good for beginners because it delegates prompt engineering to ChatGPT. It is bad for expert users because it takes away the ability to fine-tune the prompt.
ControlNet
Stable Diffusion hasn’t been the same since the invention of ControlNet. Thanks to ControlNet, you can steal a pose, a composition, and colors. Of course, none of them are available with DALLE 3.
Conclusion
To sum up, DALLE 3 generates images that follow prompts much better than Stable Diffusion. This also applies to text rendering. It integrates with ChatGPT to improve your prompt before rendering. These translate to a high chance of getting a usable image the first time you try.
The downside of DALLE 3, at least for now, is the inability to further dial in an image. It doesn’t support inpainting, outpainting, and ControlNet. Being a single model, the possible styles are more limited than Stable Diffusion.
DALLE 3 excels at ease of use. I found it practical. Compared to Stable Diffusion and MidJourney, I can count on it to generate the image I need in the shortest time. On the other hand, Stable Diffusion is for artistic creation and fun, with the ability to refine every aspect of the image until it is perfect.
The ChatGPT middleman makes it challenging for expert users to fine-tune the image because they cannot modify the prompt directly. This limitation likely arises from liability concerns. ChatGPT incorporates an additional safety filter to eliminate any inappropriate content from the prompt. As a result, users cannot use the AI model with complete freedom.
Perhaps the biggest divide is in the business model: DALLE 3 is a close, proprietary service. Stable Diffusion is an open-source, downloadable model. The power of Stable Diffusion lies in thousands of users spending millions of hours building tools for it and fine-tuning it.
Governments and big corporations around the world are keen on regulating open-source AI models prematurely. The effort will likely stifle open-source developments that have led to thousands of custom models on Civitai and amazing tools like ControlNet.
Improving Stable Diffusion
From the success of DALLE 3, a quick improvement is to fine-tune the Stable Diffusion XL model with highly accurate captions. This will significantly improve the out-of-box performance of Stable Diffusion, making it more useful as a text-to-image generator.
Once the improved base model is trained, we can generate highly accurate images in various styles with Loras or fine-tuned models.
Using Stable Diffusion and DALL·E 3 together
Of course, Stable Diffusion and DALLE 3 are not mutually exclusive. We can use them together in their strengths.
Inpainting
You can first generate an image in DALLE 3 and use Stable Diffusion for inpainting. This compensates for DALLE 3’s inability to inpaint.
Reference images for ControlNet
If you have trouble generating an image with Stable Diffusion, you can try DALLE 3. Then use the image as a reference for ControlNet Canny, for example, to steal the composition.
Thank you for the article.
I have been playing with Dalle3 and SD for 2 months now and found that it’s super hard to have SD generate photos filled with funny/weird/creative elements.
Seems like SD in general is good at generating images that are more like portraits with reasonable subject matter and nothing too crazy.
For instance, let’s take this prompt:
“super realistic photo of monkeys with aliens from space with umbrellas dancing on the beach”
Dalle3: https://ibb.co/dtqtkyJ
SDXL V1.0:
https://sdbooth2-production.s3.amazonaws.com/wmfstdqkynfvjcum13a0abgh23x6
https://sdbooth2-production.s3.amazonaws.com/7z6w28c9pwel8hoopp46d27a1zcw
Another example prompt:
super realistic photo of one beautiful young blonde girl dancing with aliens in times square
Dalle3: https://ibb.co/wRJVPkW
SDXL V1.0:
https://sdbooth2-production.s3.amazonaws.com/4heomfbcu8t7wkkrw37uqw9cqaq3
https://sdbooth2-production.s3.amazonaws.com/njer3z6sqb7sgevmapi8m5kj1z2h
Why is it that SD has a much harder time generating an image with complex subject matter? Is it possible to train SD to create Lora style that can solve this? or do I need to go beyond this and create a unique AI base model?
Dalle3’s major advancement is prompt-following. It is currently unmatched by any AI generators. We should be able to finetune SD to achieve the same with highly accurate captions.
Are you sure thats the prompt it took, like in the article or what you will call it, it is explained that chatgpt does the heavy lifting.
When i saw your prompt i actually expected pretty much what you were getting from SDXL.
But if you see what chatgpt changed your prompt into you would be surprised.
I’d choose Dalle3 in the morning, afternoon, evening and night. I have a clipdrop account and the results I’m getting from SD is simply unusable for me. And no, I’m not gonna install it on a GPU and do the fancy refining procedures. I need a refined, usable image out of the package. I don’t need frustration.
Thanks andrew, while with dalle-e 3 we just give it a word and it does the heavy lidting from promting to generation,
Do you have any prompts that we can give chat gpt to create image prompts.
in short how can we use chat gpt to build amazing image prompts to use on sdxl thanks.
Not quite you what you ask. If Dalle3 generates an image, you can always use it as an image prompt to SD. Or do you mean something else?
Much needed comparison, I think dalle3 is just amazing 10x better then previous version. I thinks sdxl still lacks when it comes to text being in the image we created business banners and its messing up the text. Did you tested it, we tried it with just raw sdxl version, and some on leonardos sdxl versions.
Yes, what you described about sdxl matches my testing. I tested with the sdxl base model. I don’t think leonardos sdxl would be any different.
Even better than controlnet is the newer IP Adapter. This does highly effective style transfer (visual not textual prompting). ComfyUI also adds layers of additional power over the simpler Automatic1111 UI.
Yes, there are some amazing comfyui workflows using ip adapter. We can also use it on controlnet: https://stable-diffusion-art.com/image-prompt/
We started using stable diffusion xl, at the moment it’s ruining the hands or legs part, the picture looks like pixalated, did you find this in your test.
mine looks ok. do you use the correct resolution 1024×1024
You are a great writer. Information is conveyed so clearly, objectively, and comprehensively. Thank you, Andrew!
Thank you for reading!
“You cannot directly control the prompt for DALLE 3 …”
Dall-E 3 can also be accessed via Bing Image Creator.
I hope you know that you can access dall-e 3 for free through bing image creator
Good to know!
And when you use it through being you bypass chat GPT redoing your prompts
Hi, Andrew. I noticed that DALL-E tends to generate the same kind of woman: with hard cheeks and with lip procedures. The model is probably fed with images that represent a “modern” beauty standard. This is poor and limited in terms of creativity. SDXL is much more diverse in this aspect, especially using models. But SDXL models tend to produce deformed images when you use img2img, maybe for the lack of references for that specific pose.
Hi! This likely comes from OpenAI’s clip model. SD 1.5 uses it and have the same behavior of the default aesthetic. SDXL moved away from it partially and has paid more attention to the diversity. In both models, you can override the default with another stereotype keywords, European, 15th century, etc.