
Text-to-image (txt2img) refers to generating an image from text input using an AI model. There are many txt2img AI available. You can use txt2img settings to control the image generation.
In this post, you will learn
- How does a txt2img model work.
- How to use txt2img AI.
- Stable Diffusion txt2img settings.
- Other popular txt2img models.
Table of Contents
How does a text-to-image model work?
A txt2img model is a neural network that inputs a natural language text and produces an image that matches the text. In Stable Diffusion and other AI image models, the text input is called the prompt and the negative prompt.
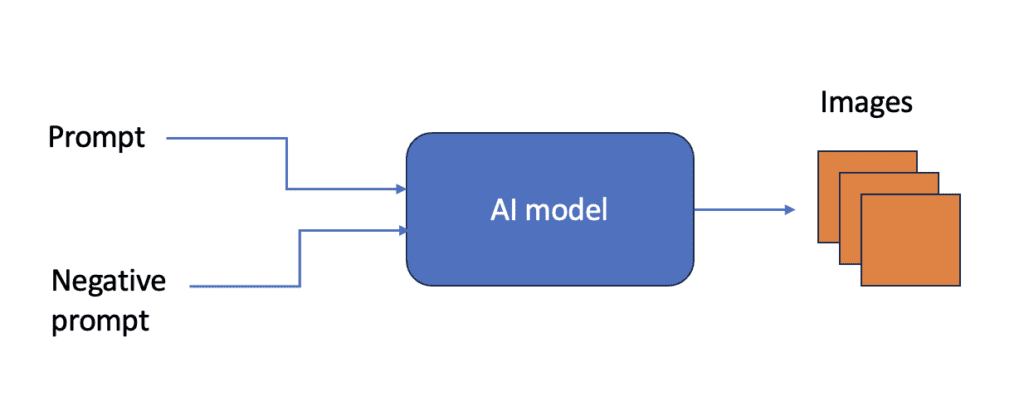
The txt2img AI can produce multiple images from the same prompt and negative prompt because of probabilistic outputs. After all, many images can match the prompt.
How to use text-to-image
Text-to-image is the most basic function of AI image generators, including Stable Diffusion.
In AUTOMATIC1111 Stable Diffusion WebUI, you use text-to-image on the txt2img page.
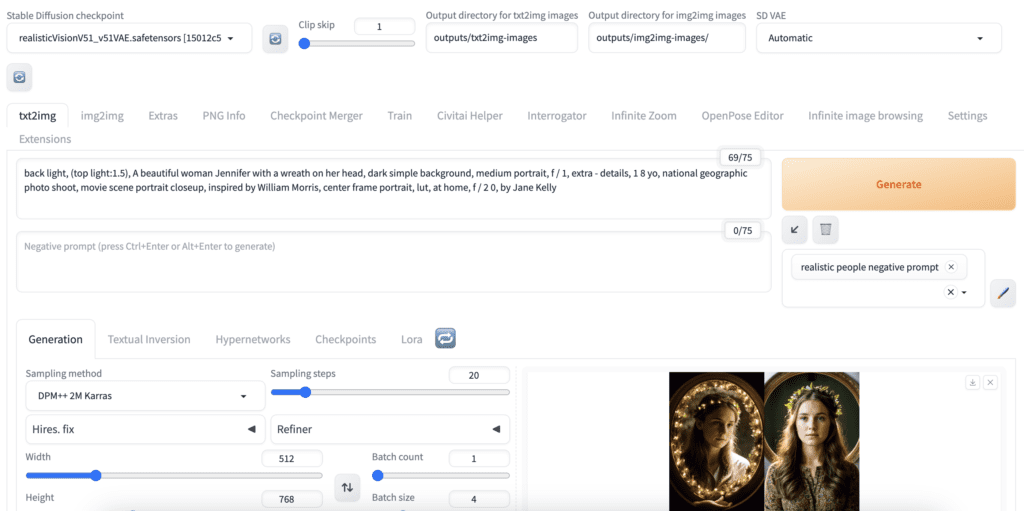
Stable Diffusion text-to-image settings explained
For Stable Diffusion, the following settings affect the outcome of txt2img.
- Checkpoint model: The Stable Diffusion model significantly affects the style. For example, use a photorealistic model like Realistic Vision to generate realistic people.
2. Prompt: The text input that describes what you want to see in the image.
3. Negative prompt: The text input that describes what you DON’T want to see.
4. Image Size: The image size should match the Checkpoint model. The size of the VAE is 512×512 for the v1 models and 1024×1024 for the SDXL model.
| Aspect ratio | v1 models | SDXL models |
|---|---|---|
| 1:1 | 512×512 | 1024×1024 |
| 3:2 | 768×512 | 1216×832 |
| 16:9 | 910×512 | 1344×768 |
5. Sampling Method: The method for denoising an image in the diffusion process. You don’t need to change it if you are just starting out.
6. Sampling steps: The number of steps to discretize the denoising processing. A higher value makes the denoising process more accurate, and hence higher quality. Set it to at least 20.
7. CFG scale: The Classifier-Free Guidance scale controls how closely the prompt should be followed.
1 – Mostly ignore your prompt.
3 – Be more creative.
7 – A good balance between following the prompt and freedom.
15 – Adhere more to prompt.
30 – Strictly follow the prompt.
You may see a color issue if it is set to high.
How are txt2img models trained?
Training data and method is as important as the AI model architecture. Modern txt2img models are all trained with a massive dataset of image and caption pairs. By learning the correlation between the images and captions, the AI model learned to produce images that match a prompt.
Text-to-image AI models
Stable Diffusion is not the only txt2img model, although it is certainly among the well-known ones. You will learn a few important txt2img models in this section.
DALL·E
OpenAI’s DALL·E is one of the first txt2img models that received widespread public attention. Although its image generation may look primitive by today’s standards, it was a huge breakthrough in 2021 when it was released. For the first time, we could generate an image with a natural language description.

DALL·E shares the same model architecture as GPT-3, OpenAI’s celebrated large language model. A caption-image pair is encoded as tokens, with tokens presenting the caption followed by that of the image. Given the caption tokens, the GPT-3 model completes the image tokens, which are then decoded back to an image.
While sharing the same name, DALL·E 2 is a vastly different model. It is much smaller than DALL·E 1 and is a diffusion model like Stable Diffusion. It is a two-stage model: The first model generates the image embedding from the prompt. The second diffusion model generates the image conditioned with the image embedding.
DALL·E 3 is an improvement over DALL·E 2, promising to deliver more accurate images that match the prompt. The most exciting feature is integration with ChatGPT, which promises using natural languages to refine an image.
Imagen
The Imagen text-to-image model developed by Google is a neutral network diffusion model that generates photorealistic images. The model architecture and benchmark are published in the article Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding by Chitwan Saharia and coworkers.

The main design choices of this model are:
- Use a frozen language model to encode text.
- Use a U-Net structure to control the diffusion process.
- Use classifier-free guidance for conditioning.
You are right if you think these all sound very similar to Stable Diffusion. They have very similar architectures but with one exception.
Stable Diffusion

The Stable Diffusion txt2img model is the most popular open-source text-to-image model. While Imagen delivers superior performance, it requires high-power computers to run because the diffusion process is in the pixel space.
The main innovation of Stable Diffusion is to encode the image to latent space using a variational autoencoder (VAE) and perform the diffusion in the latent space. Because the latent space is smaller, Stable Diffusion runs much faster than Imagen and DALLE 2. In fact, it’s been popular because it can be run on a personal computer.
Midjourney

Midjourney is a proprietary txt2img model that its parent company provides as an image generation service. Not much has been disclosed about the model’s architecture. See comparison between Stable Diffusion and Midjourney.