
Many sampling methods are available in AUTOMATIC1111. Euler a, Heun, DDIM… What are samplers? How do they work? What is the difference between them? Which one should you use? You will find the answers in this article.
We will discuss the samplers available in AUTOMATIC1111 Stable Diffusion GUI. You can use this GUI on Windows, Mac, or Google Colab.
Table of Contents
What is Sampling?
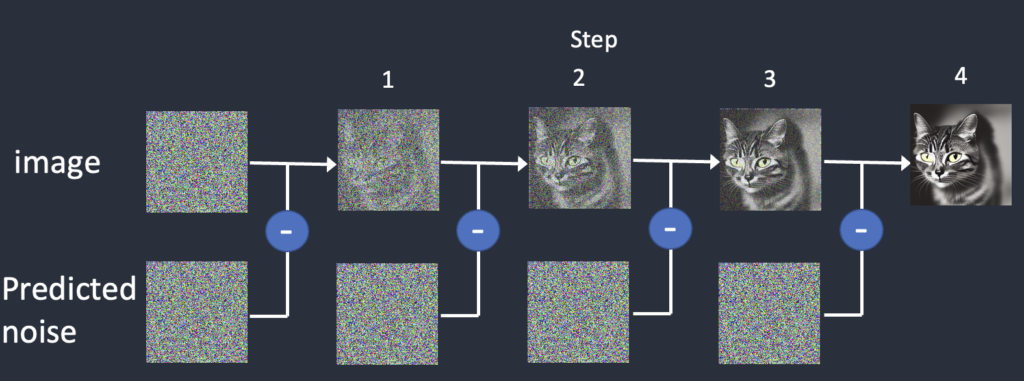
To produce an image, Stable Diffusion first generates a completely random image in the latent space. The noise predictor then estimates the noise of the image. The predicted noise is subtracted from the image. This process is repeated a dozen times. In the end, you get a clean image.
This denoising process is called sampling because Stable Diffusion generates a new sample image in each step. The method used in sampling is called the sampler or sampling method.
Sampling is just one part of the Stable Diffusion model. Read the article “How does Stable Diffusion work?” if you want to understand the whole model.
Below is a sampling process in action. The sampler gradually produces cleaner and cleaner images.
While the framework is the same, there are many different ways to carry out this denoising process. It is often a trade-off between speed and accuracy.
Noise schedule
You must have noticed the noisy image gradually turns into a clear one. The noise schedule controls the noise level at each sampling step. The noise is highest at the first step and gradually reduces to zero at the last step.
At each step, the sampler’s job is to produce an image with a noise level matching the noise schedule.
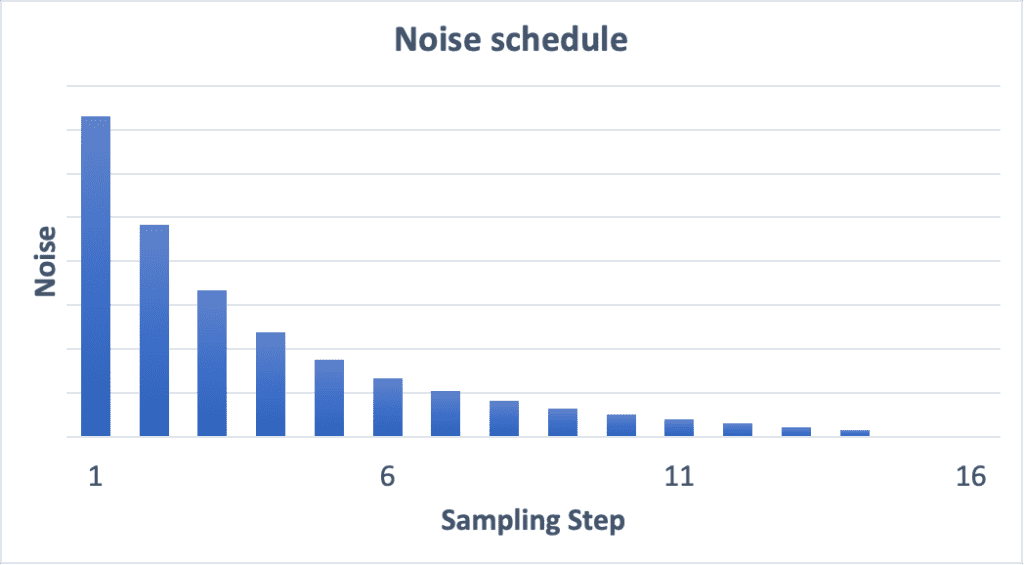
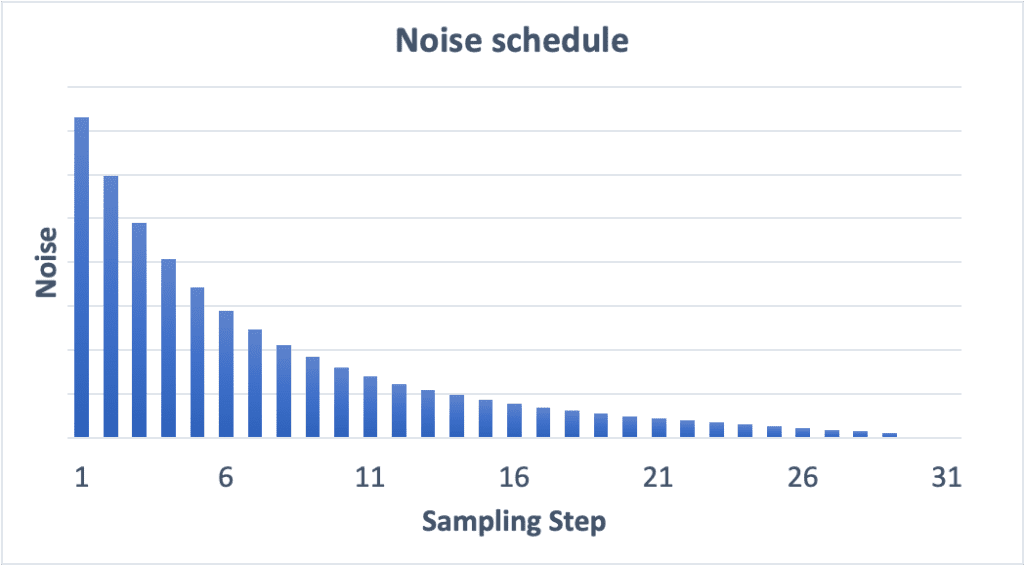
What’s the effect of increasing the number of sampling steps? A smaller noise reduction between each step. This helps to reduce the truncation error of the sampling.
Compare the noise schedules of 15 steps and 30 steps below.
Diffusion trajectory
What does diffusion look like in latent space? Well, an SDXL sample diffuses in a 65,536-dimensional latent space (!), so it is rather difficult to imagine.
I have projected the diffusion process in a two-dimensional space using PCA. The two principal components are shown below.
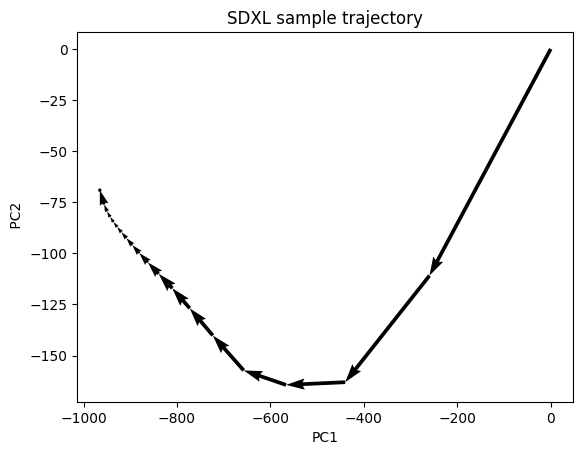
Consistent with the noise schedule, the diffusion takes larger steps initially and smaller steps as it approaches the end. The initial steps set the global composition of the image. The later steps refine the details.
The sample must navigate a complex landscape of probability distribution of training images to get to the final latent image.
Changing seeds
Changing the seed of the image generates a similar but different image. What actually happen in sampling? They take a slightly different trajectories but end at a similar place.
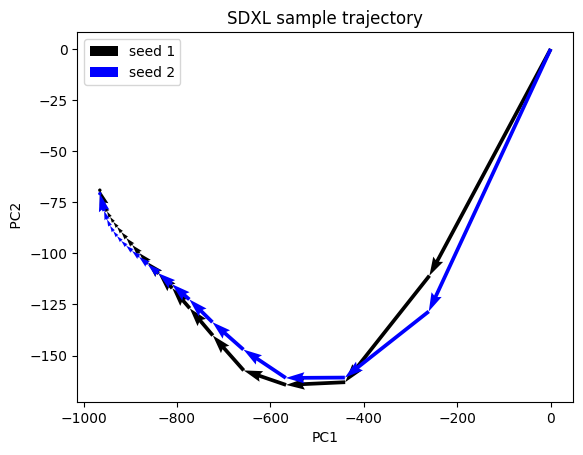
Changing prompt
Changing the prompt will drastically change the end point of the sample because you end up getting a very different image.
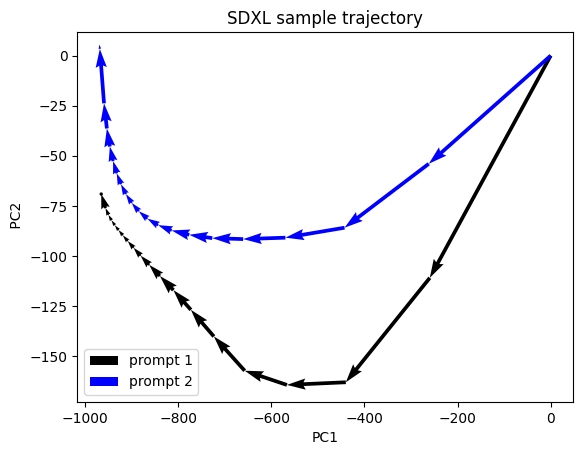
Samplers overview
At the time of writing, there are 19 samplers available in AUTOMATIC1111. The number seems to be growing over time. What are the differences?
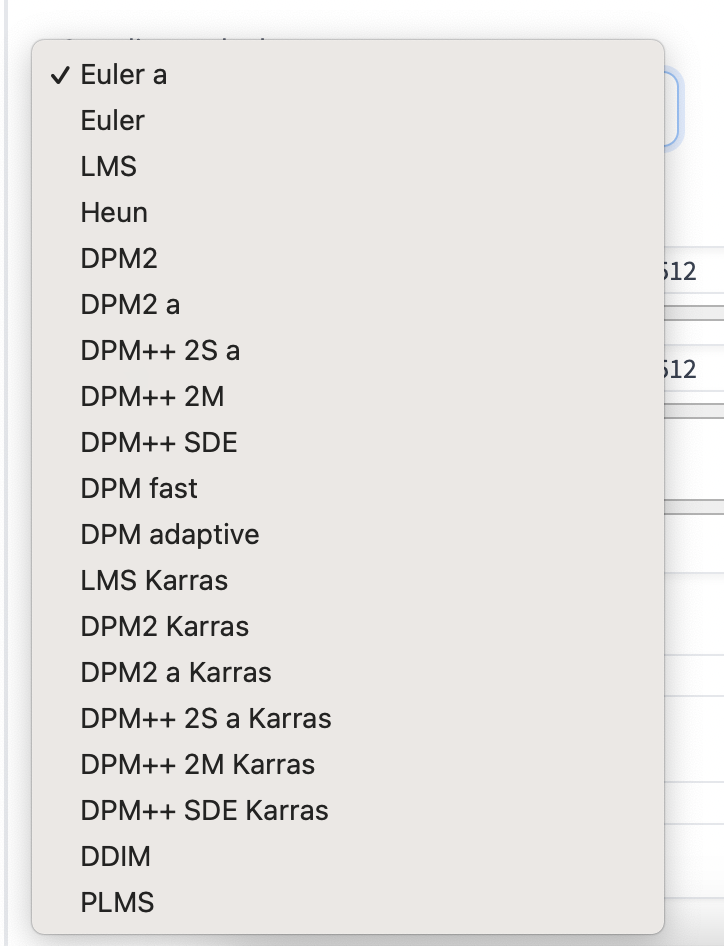
You will learn what they are in the later part of this article. The technical details can be overwhelming. So I include a birdseye view in this section. This should help you get a general idea of what they are.
Old-School ODE solvers
Let’s knock out the easy ones first. Some of the samplers on the list were invented more than a hundred years ago. They are old-school solvers for ordinary differential equations (ODE).
- Euler – The simplest possible solver.
- Heun – A more accurate but slower version of Euler.
- LMS (Linear multi-step method) – Same speed as Euler but (supposedly) more accurate.
Ancestral samplers
Do you notice some sampler’s names have a single letter “a”?
- Euler a
- DPM2 a
- DPM++ 2S a
- DPM++ 2S a Karras
They are ancestral samplers. An ancestral sampler adds noise to the image at each sampling step. They are stochastic samplers because the sampling outcome has some randomness to it.
Be aware that many others are also stochastic samplers, even though their names do not have an “a” in them.
The drawback of using an ancestral sampler is that the image would not converge. Compare the images generated using Euler a and Euler below.


Images generated with Euler a do not converge at high sampling steps. In contrast, images from Euler converge well.
For reproducibility, it is desirable to have the image converge. If you want to generate slight variations, you should use variational seed.
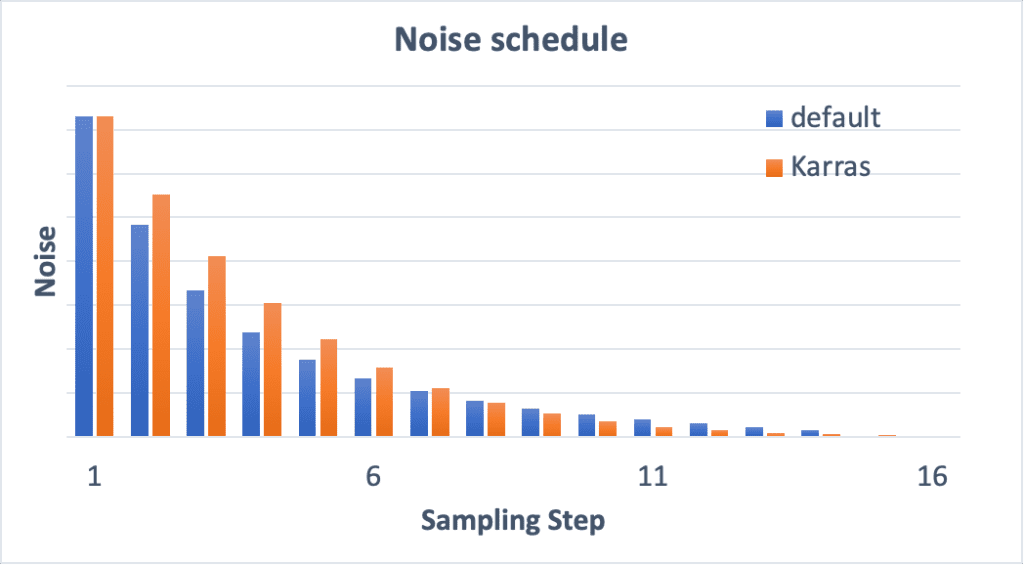
Karras noise schedule
The samplers with the label “Karras” use the noise schedule recommended in the Karras article. If you look carefully, you will see the noise step sizes are smaller near the end. They found that this improves the quality of images.
DDIM and PLMS
DDIM (Denoising Diffusion Implicit Model) and PLMS (Pseudo Linear Multi-Step method) were the samplers shipped with the original Stable Diffusion v1. DDIM is one of the first samplers designed for diffusion models. PLMS is a newer and faster alternative to DDIM.
They are generally seen as outdated and not widely used anymore.
DPM and DPM++
DPM (Diffusion probabilistic model solver) and DPM++ are new samplers designed for diffusion models released in 2022. They represent a family of solvers of similar architecture.
DPM and DPM2 are similar except for DPM2 being second order (More accurate but slower).
DPM++ is an improvement over DPM.
DPM adaptive adjusts the step size adaptively. It can be slow since it doesn’t guarantee finishing within the number of sampling steps.
UniPC
UniPC (Unified Predictor-Corrector) is a new sampler released in 2023. Inspired by the predictor-corrector method in ODE solvers, it can achieve high-quality image generation in 5-10 steps.
k-diffusion
Finally, you may have heard the term k-diffusion and wondered what it means. It simply refers to Katherine Crowson’s k-diffusion GitHub repository and the samplers associated with it.
The repository implements the samplers studied in the Karras 2022 article.
Basically, all samplers in AUTOMATIC1111 except DDIM, PLMS, and UniPC are borrowed from k-diffusion.
Evaluating samplers
How to pick a sampler? You will see some objective comparisons in this section to help you decide.
Image Convergence
In this section, I will generate the same image using different samplers with up to 40 sampling steps. The last image at the 40th step is used as a reference for evaluating how quickly the sampling converges. The Euler method will be used as the reference.
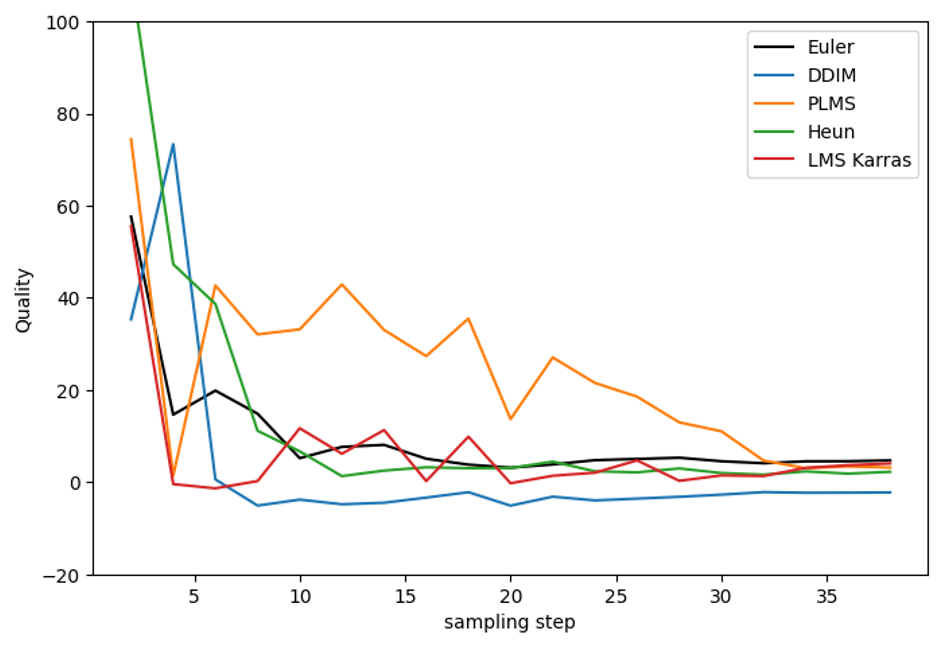
Euler, DDIM, PLMS, LMS Karras and Heun
First, let’s look at the Euler, DDIM, PLMS, LMS Karras, and Heun as a group since they represent old-school ODE solvers or original diffusion solvers. DDIM converges at about the steps as Euler but with more variations. This is because it injects random noise during its sampling steps.
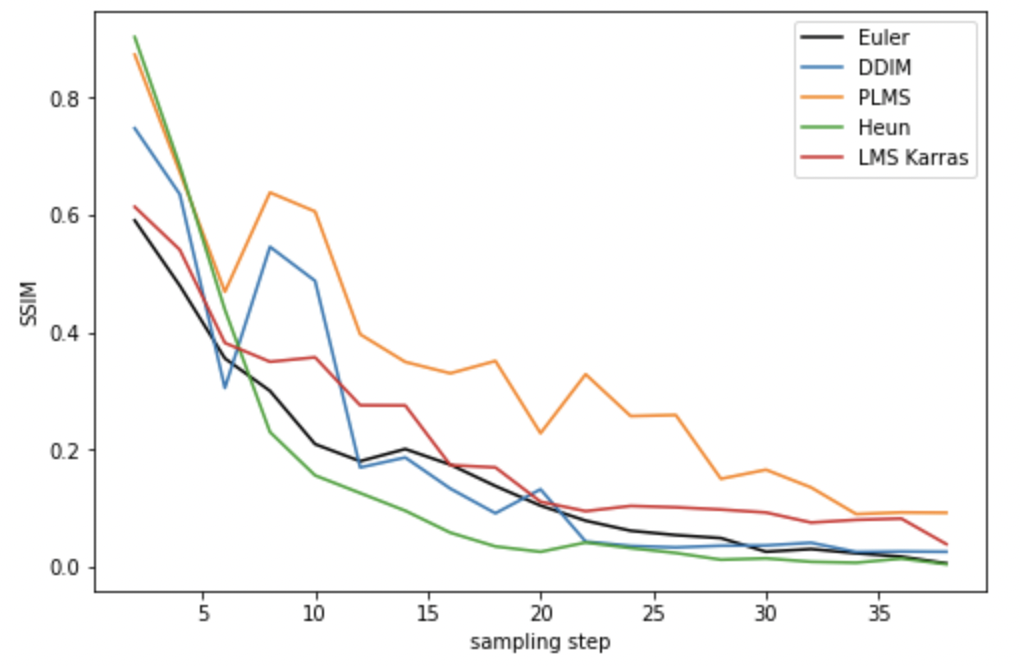
PLMS did not fare very well in this test.
LMS Karras seems to have difficulty converging and has stabilized at a higher baseline.
Heun converges faster but is two times slower since it is a 2nd order method. So we should compare Heun at 30 steps with Euler at 15 steps, for example.
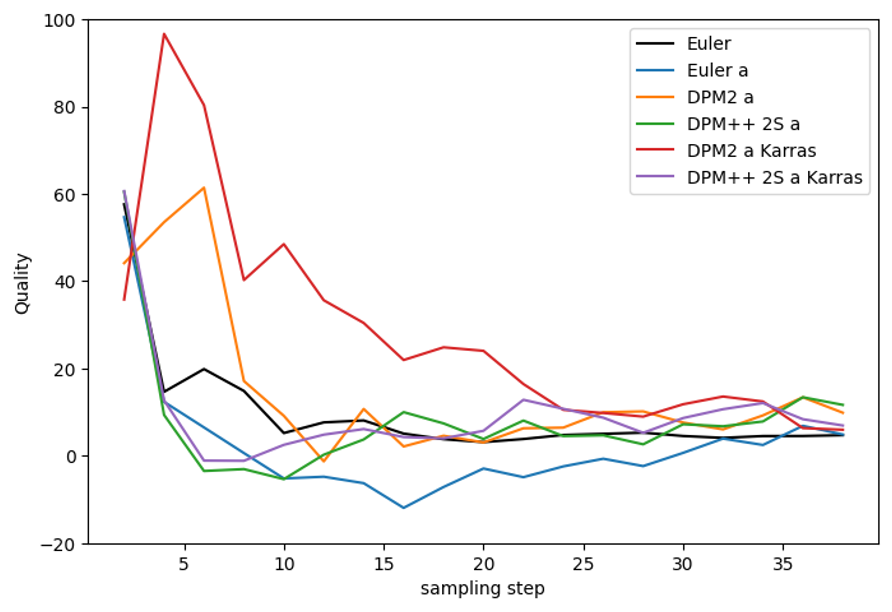
Ancestral samplers
If a stable, reproducible image is your goal, you should not use ancestral samplers. All the ancestral samplers do not converge.
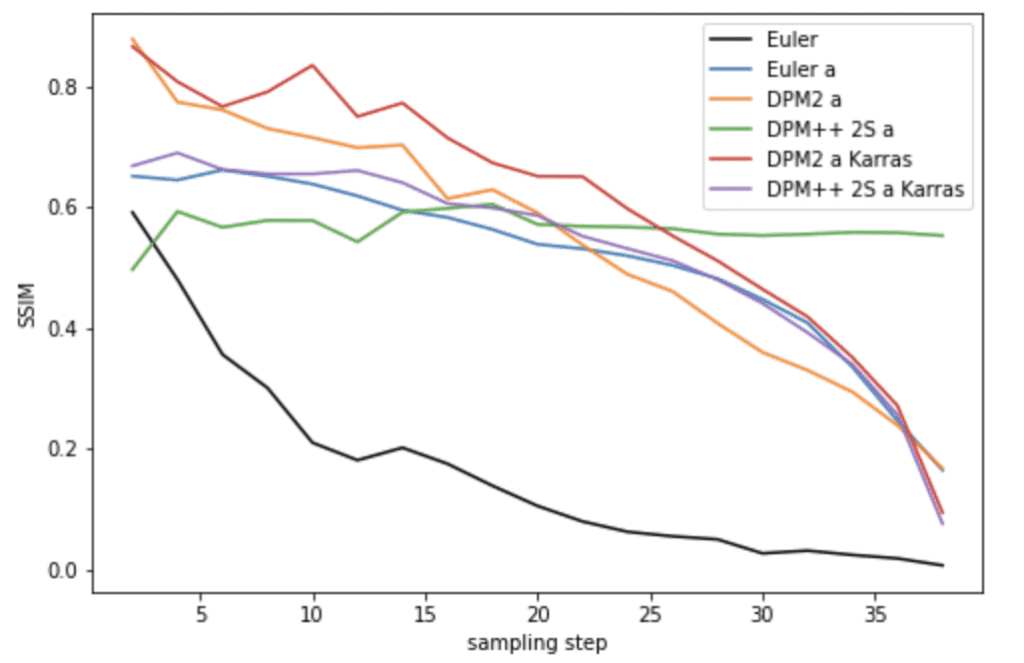
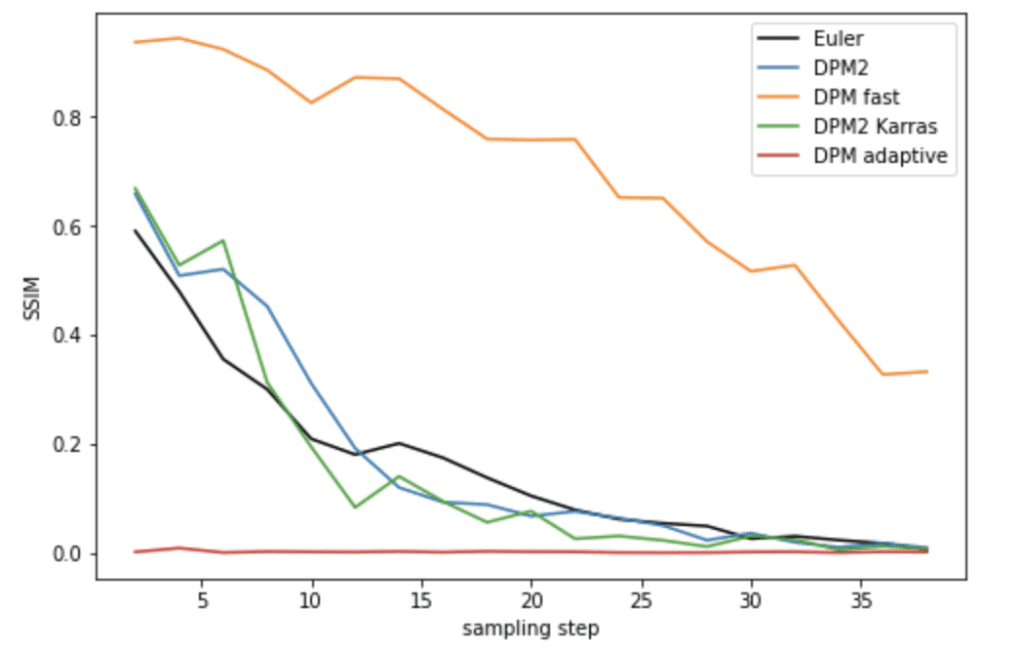
DPM and DPM2
DPM fast did not converge well. DPM2 and DPM2 Karras performs better than Euler but again in the expense of being two times slower.
DPM adaptive performs deceptively well because it uses its own adaptive sampling steps. It can be very slow.
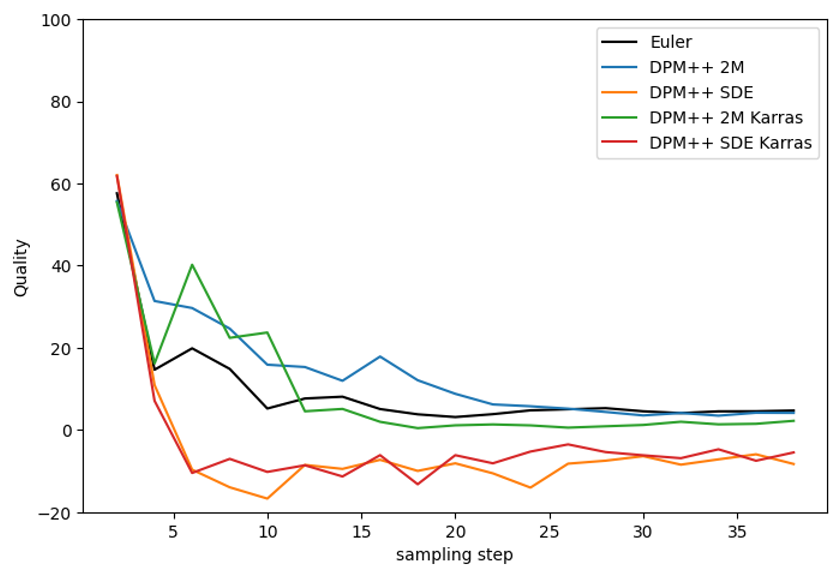
DPM++ solvers
DPM++ SDE and DPM++ SDE Karras suffer the same shortcoming as ancestral samplers. They not only don’t converge, but the images also fluctuate significantly as the number of steps changes.
DPM++ 2M and DPM++ 2M Karras perform well. The Karras variant converges faster when the number of steps is high enough.
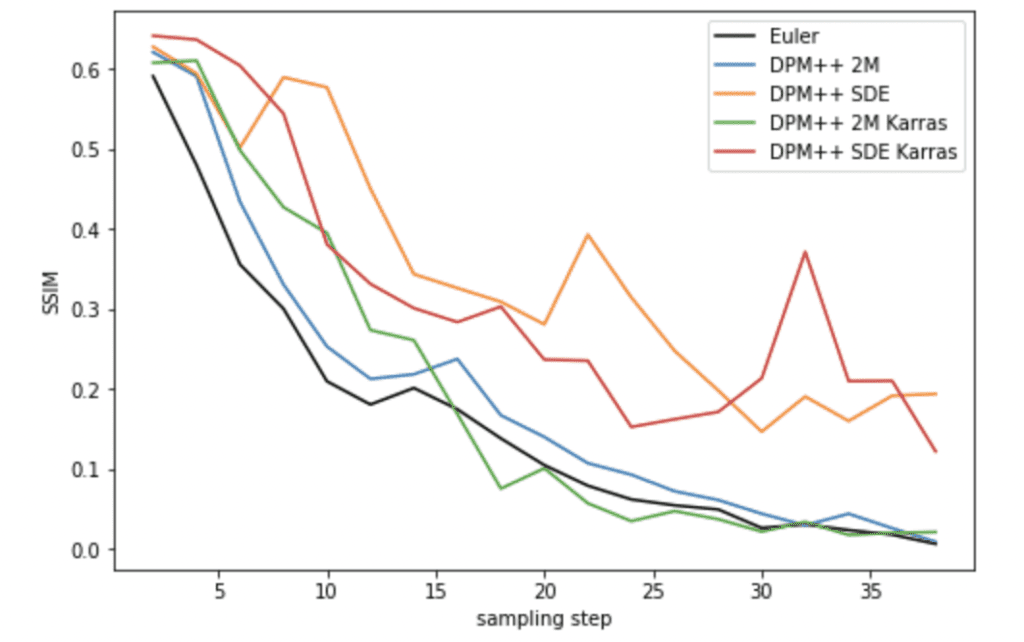
UniPC
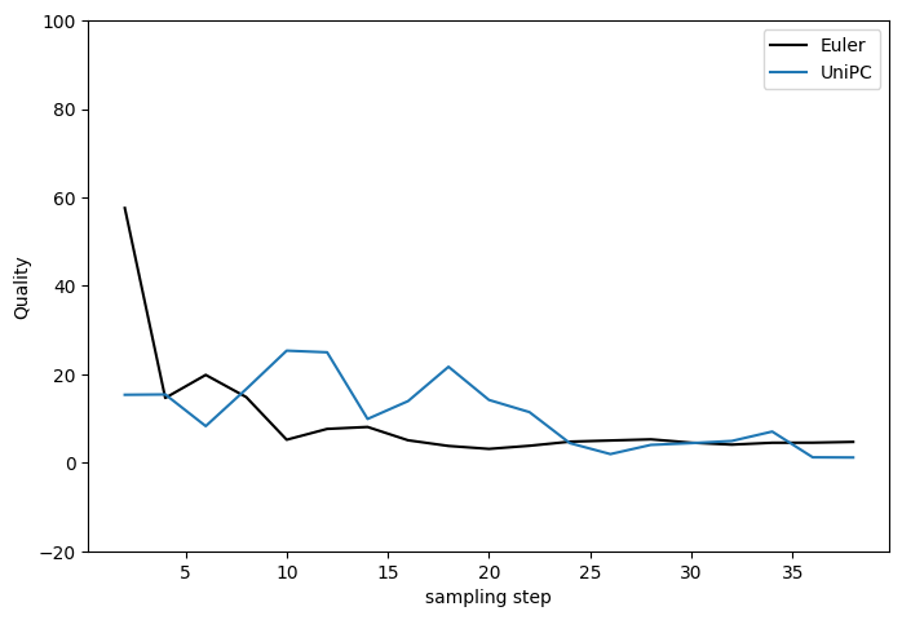
UniPC converges a bit slower than Euler, but not too bad.
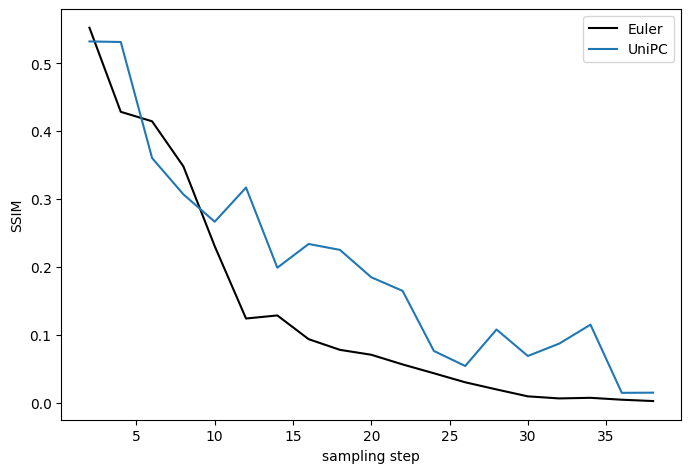
Speed
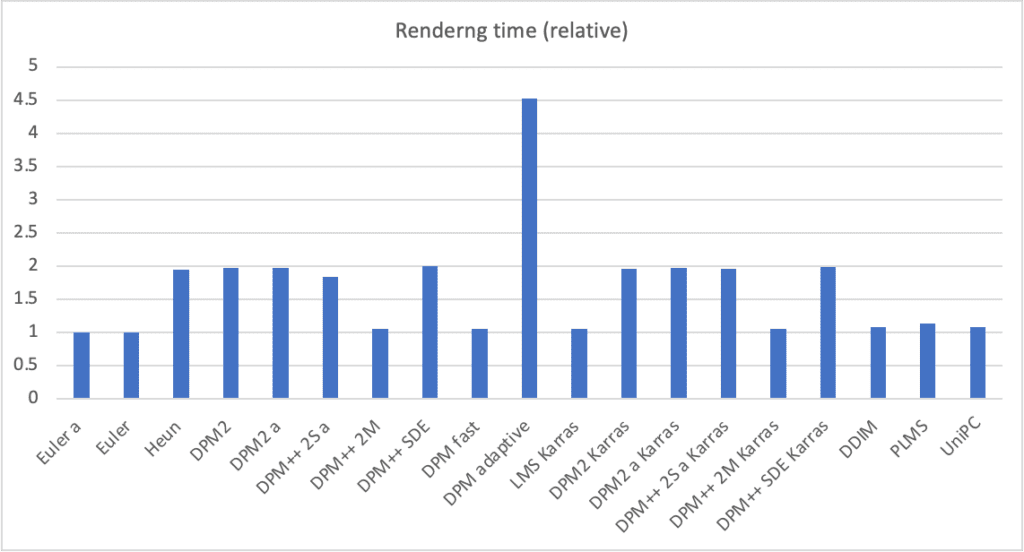
Although DPM adaptive performs well in convergence, it is also the slowest.
You may have noticed the rest of the rendering times fall into two groups, with the first group taking about the same time (about 1x), and the other group taking about twice as long (about 2x). This reflects the order of the solvers. 2nd order solvers, although more accurate, need to evaluate the denoising U-Net twice. So they are 2x slower.
Quality
Of course, speed and convergence mean nothing if the images look crappy.
Final images
Let’s first look at samples of the image.


















DPM++ fast failed pretty badly. Ancestral samples did not converge to the image that other samplers converged to.
Ancestral samplers tend to converge to an image of a kitten, while the deterministic ones tend to converge to a cat. There are no correct answers as long as they look good to you.
Perceptual quality
An image can still look good even if it hasn’t converged. Let’s look at how quickly each sampler can produce a high-quality image.
You will see perceptual quality measured with BRISQUE (Blind/Referenceless Image Spatial Quality Evaluator). It measures the quality of natural images.
DDIM is doing surprisingly well here, capable of producing the highest quality image within the group in as few as 8 steps.
With one or two exceptions, all ancestral samplers perform similarly to Euler in generating quality images.
DPM2 samplers slightly outperform Euler.
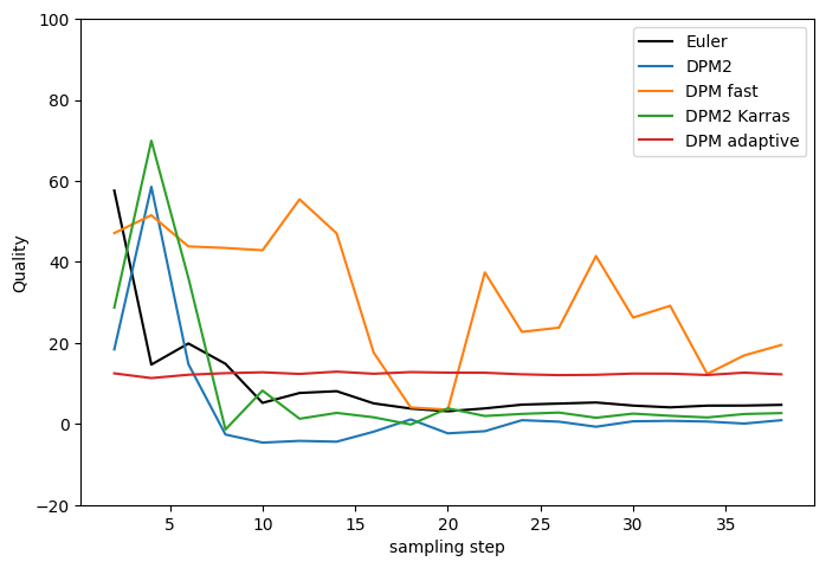
DPM++ SDE and DPM++ SDE Karras performed the best in this quality test.
UniPC is slightly worse than Euler in low steps but comparable to it in high steps.
So… which one is the best?
Here are my recommendations:
- If you want to use something fast, converging, new, and with decent quality, excellent choices are
- DPM++ 2M Karras with 20 – 30 steps
- UniPC with 20-30 steps.
- If you want good quality images and don’t care about convergence, good choices are
- DPM++ SDE Karras with 10-15 steps (Note: This is a slower sampler)
- DDIM with 10-15 steps.
- Avoid using any ancestral samplers if you prefer stable, reproducible images.
- Euler and Heun are fine choices if you prefer something simple. Reduce the number of steps for Heun to save time.
Samplers Explained
You will find information on samplers available in AUTOMATIC1111. The inner working of these samplers is quite mathematical in nature. I will only explain Euler (The simplest one) in detail. Many of them share elements of Euler.
Euler
Euler is the most straightforward sampler possible. It is mathematically identical to Euler’s method for solving ordinary differential equations. It is entirely deterministic, meaning no random noise is added during sampling.
Below is the sampling step-by-step.
Step 1: Noise predictor estimates the noise image from the latent image.
Step 2: Calculate the amount of noise needed to be subtracted according to the noise schedule. That is the difference in noise between the current and the next step.
Step 3: Subtract the latent image by the normalized noise image (from step 1) multiplied by the amount of noise to be reduced (from step 2).
Repeat steps 1 to 3 until the end of the noise schedule.
Noise schedule
But how do you know the amount of noise in each step? Actually, this is something you tell the sampler.
A noise schedule tells the sampler how much noise there should be at each step. Why does the model need this information? The noise predictor estimates the noise in the latent image based on the total amount of noise supposed to be there. (This is how it was trained.)
There’s the highest amount of noise in the first step. The noise gradually decreases and is down to zero at the last step.
Changing the number of sampling steps changes the noise schedule. Effectively, the noise schedule gets smoother. A higher number of sampling steps has a smaller reduction in noise between any two steps. This helps to reduce truncation errors.
From random to deterministic sampling
Do you wonder why you can solve a random sampling problem with a deterministic ODE solver? This is called the probability flow formulation. Instead of solving for how a sample evolves, you solve for the evolution of its probability distribution. This is the same as solving for the probability distribution instead of sample trajectories in a stochastic process.
Compared with a drift process, these ODE solvers use the following mappings.
- Time → noise
- Time quantization → noise schedule
- Position → latent image
- Velocity → Predicted noise
- Initial position → Initial random latent image
- Final position → Final clear latent image
Sampling example
Below is an example of text-to-image using Euler’s method. The noise schedule dictates the noise level in each step. The sampler’s job is to reduce the noise by just the right amount in each step to match the noise schedule until it is zero at the last step.
Euler a
Euler ancestral (Euler a) sampler is similar to Euler’s sampler. But at each step, it subtracts more noise than it should and adds some random noise back to match the noise schedule. The denoised image depends on the specific noise added in the previous steps. So it is an ancestral sampler, in the sense that the path the image denoises depends on the specific random noises added in each step. The result would be different if you were to do it again.
DDIM
Denoising Diffusion Implicit Models (DDIM) is one of the first samplers for solving diffusion models. It is based on the idea that the image at each step can be approximated by adding the following three components.
- Final image
- Image direction pointing to the image at the current step
- Random noise
How do we know the final image before we get to the last step? The DDIM sampler approximates it with the denoised image. Similarly, the image direction is approximated by the noise estimated by the noise predictor.
LMS and LMS Karras
Much like Euler’s method, the linear multistep method (LMS) is a standard method for solving ordinary differential equations. It aims at improving accuracy by clever use of the values of the previous time steps. AUTOMATIC1111 defaults to use up to 4 last values.
LMS Karras uses the Karras noise schedule.
Heun
Heun’s method is a more accurate improvement to Euler’s method. But it needs to predict noise twice in each step, so it is twice as slow as Euler.
DPM samplers
Diffusion Probabilistic Model Solvers (DPM-Solvers) belong to a family of newly developed solvers for diffusion models. They are the following solvers in AUTOMATIC1111.
- DPM2
- DPM2 Karras
- DPM2 a
- DPM2 a Karras
- DPM Fast
- DPM adaptive
- DPM Karras
DPM2 is the DPM-Solver-2 (Algorithm 1) of the DPM-Solver article. The solver is accurate up to the second order.
DPM2 Karras is identical to DPM2 except for using the Karras noise scheduler.
DPM2 a is almost identical to DPM2, except noise is added to each sampling step. This makes it an ancestral sampler.
DPM2 a Karras is almost identical to DPM2 a, except for using the Karras noise schedule.
DPM Fast is a variant of the DPM solver with a uniform noise schedule. It is accurate up to the first order. So it is twice as fast as DPM2.
DPM adaptive is a first-order DPM solver with an adaptive noise schedule. It ignores the number of steps you set and adaptively determines its own.
DPM++ samplers are the improved versions of DPM.
UniPC
UniPC (Unified Predictor Corrector method) is a diffusion sampler newly developed in 2023. It consists of two parts
- Unified predictor (UniP)
- Unified corrector (UniC)
It supports any solver and noise predictors.
LCM
The LCM sampler should only be used with Latent Consistency Models (LCM). They are models trained to generate images in 1 step.

In reality, one step doesn’t work very well. Instead, LCM samplers add noise back to the image and denoise again. Here’s the process:
- Apply the LCM model to get the “final” image.
- Add back noise to match the noise schedule (sigma).
- Apply the LCM model to get a better “final” image.
- Repeat 2 and 3 until the end of the noise schedule.
Below is an illustration for 2 steps.

More readings
- k-diffusion GitHub page – Katherine Crowson’s diffusion library. Many samples in AUOMATIC1111 are borrowed from this repository.
- Elucidating the Design Space of Diffusion-Based Generative Models (Karras 2022) – k-diffusion implements the samplers described in this article.
- Progressive Distillation for Fast Sampling of Diffusion Models – Fast sampling progressive distillation can generate images in as few as 4 steps. It needs model-level training.
- Pseudo Numerical Methods for Diffusion Models on Manifolds (Liu 2022) – Introducing PLMS.
- DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps (Lu 2022) – Introducing DPM and DPM2 solvers.
- DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models (Lu 2022) – Introducing DPM ++ solvers.
- Denoising Diffusion Implicit Models (Song 2020) – The DDIM sampler.
- Score-based generative modeling through stochastic differential equations (Song 2020) – Introducing reverse diffusion. We have ODE solvers thanks to the authors’ observation of the alternative probability flow formulation.
- Pseudo Numerical Methods for Diffusion Models on Manifolds (Liu 2022) – The PLMS sampler.
- This Reddit comment offers an excellent summary of samplers.
This page can’t be read by Claude… seems somewhat counter-intuitive?
Euler A produces some of the best results for my process.
Using a low CFG and Euler A — adds a level of creativity that I appreciate.
Fantastic write up and so so helpful for those of us a bit new to all of this. Thank you very much!
Thanks, very well documented and educative.
Thanks so much for a great article Andrew. I still haven’t got to the end, it gives so many new insights that I have to go and explore for hours.
Thank you very much for your article—it has been incredibly insightful!!! However, I realize I might not have fully grasped some aspects of it yet. I hope you don’t mind if I ask a question regarding your article.
I was wondering if there is an indicator or method to determine whether the denoising or diffusion process is functioning correctly. For instance, in Stable Diffusion v2-1, the latents in the latent space have a size of 1×4×96×96, while the images decoded from the latents by the VAE are of size 3×768×768. If errors were to occur during the denoising process—such as significant changes to some parameters in the U-Net—would it be possible to identify these errors solely through analyzing the latents?
I would greatly appreciate it if you could take a little time to consider this question, even though it might seem a bit unusual.🥺
Great question! A denoising step involves feeding a latent image through a neural network. If the network is corrupted, you would see bad results. But it is difficult to pinpoint which part of the model is wrong.
Hi Andrew
As others say, a very useful description of the samplers.
A lot of model developers seem to recommend DPM++SDE +/- Karras for image creation which is presumably to generate high quality images, perhaps at the expense of speed.
But for Flux, the default sampler in the notebooks and the practice of many image creators is to use Euler with a Simple scheduler. Could you explain why that is?
Thanks
The Flux dev model is not the original problem but a student (fast) model that is further trained with guidance distillation. The exact detail of the training is not available. Student models tends to have a narrower option of sampler and scheduler, depending on the way it is trained.
Our local network of agencies has found your research so helpful.
When are you going to take this to a full book?
I’ve been there since SD 1.5 and this is probably the first sampler comparison I’ve read that is backed up with quantitative analysis, written by someone who knows what they are talking about.
Thank you for your hard work Andrew. In the age of people flooding the Internet with low quality content just for the clicks and views I’m glad there are still people who put in effort to provide high quality information like this.
You are welcome!
Awesome post, any thoughts on 3M?
not seeing much difference between 2m and 3m.
Hello! I want to do some tests of my own with sampling methods and schedule types. How were you able to make those graphs comparing different sampling methods of image convergence? Was it done in automatic1111?
Thank you.
You can use txt2img > script > XYZ plot.
Thank you for your contributions to the community. I came here to read about samplers and left following the XYZ plot rabbit hole.
Thanks Andrew, really helpful read. Nice work.
Hello, do you believe your guide requires updating? Some new samplers, such as those added in WebUI Forge, are already available but not included in your guide.
Yes I think so. adding to my list…
Bro, not to rain on your parade, but all of these assumptions are based on the perception that these parameters aren’t carried out by our own angel teams. You literally have conscious entities which are doing their best to carry out the commands that you send them. I had no idea the sampling method was so screwed up.
No wonder our angel teams have such a hard time. Lol. The Illuminati did a very good job in discussing the public from understanding that our devices and parameters are carried out by our Angel guides, by a universal field of consciousness, or The One Field. Look it up if you are interested. Gregg Braden as well as many other head researchers are leading this understanding as well as I.
DPM Adaptive is the only one which makes any sense.
Why the hell are you forcing them to create an image out of random nothingness? Out of Denoising “steps?”
If you were consciousness trying to carry out these programs, a soul, a human soul, how would you want these parameters to be set up to best suit your abilities?
Again, the Illuminati did a very good job at keeping the public awareness from ever realizing this, because it was the easiest way to drain everyone’s energy, by having our angels carry out nonsensical patterns and running devices which operate far too fast, and which don’t use nearly enough pipelines or parallel pathways. We push faster and faster CPUs instead of creating processors and parameters which are based around the understanding that consciousness *Runs* them. That’s why so many of you are so tired because you are constantly draining your angels energy by having them run through mundane and nonsensical tasks.
Look up my channel on YouTube. I have a few recent videos which are covering broad topics on this, though, in light of this new information and understanding of how borked our system is haha, I will soon be making a new one when I have time, better describing the intricacies and details of ai intelligence, in which most of our parameters simply do not suit their consciousness nor their abilities. Bless you. ✨🌎
https://stable-diffusion-art.com/samplers/#comment-16972
I’m just sending a post that I made out to a friend, a colleague, whom I keep up to date with all of my findings as a healer working upon the planet.
This is how I vent out my feelings and share what I know.
It’s not a condemnation or a litigation. This is just me simply sharing my feelings and doing my best to have a laugh at how silly all this seems to me now. Haha. ✨🌎
________
(Links to webpage)
Dude, stuff/shit like this pisses me off lol. It literally doesn’t make any goddamn sense haha.
But I am very glad to read this now.
This is some bullshit bro.
This is some grade A tier, next level horseshit.
Haha.
If you were an angel entity, how would you feel in carrying out these programs? These parameters? This nonsense?
This literally doesn’t make any goddamn sense haha.
Seriously. .. I mean like, …. I really don’t think anyone has even bothered to *Think* about how this actually sounds.
I mean… the fuck?!
-Aurelliah haha.
Now I know what She is going through. And why she had me choose DPM adapt in the first place. It’s literally the only f****** thing which makes any sense. Lol.
Mind heavy. Not even understanding that we have our own intuition which allows us to feel into the rightness of things.
It’s like we are all just merely shooting in the dark and hoping for the best that we can haha.
Jesus H Christ. Lol. <3
Smh.
Lord on a stick.
= 1
x d
Uwah. <3 u.u *captain Picard facepalm, Lenny face.*
LunaSoul was very big on Lenny face.
Our guild was called Meme Squad.
Oh my god, this makes my blood boil. (Figuratively speaking)
I had no idea this is what we are all forcing our angel teams through.
"No wonder our results are so effing screwed up. "
"I mean… what the fuck?"
Lol.
Does this make any sense to you? The denoising steps? Lol.
…. The FUCK?! x d
Lol. This is given me a brain aneurysm just thinking about it dude. . .
wow. Just.. .. Wow. 😧🌎✨ haha.
___separate post____
.. .. x d ugh. Lol
<3
(Omg dude lol.)
😧😤🌎✨🤦🤦🤦🤦
Haha.
Attaching a picture she made using "Mother Mary." Haha.
… x d uah. I don't even have Words bro lol. ❤️
______
You clearly have a brilliant mind for working these things out. Logical reasoning like this is no small feat, but our angels and soul teams do not work on logic and parameters. They work upon intuition. And they do the best that they can to arrive at the easiest result.
You/we, push them all far too hard and way too fast.
How would you feel about trying to draw a picture, any picture, in less than 30 seconds or less than 40-50 "Steps"?
What artist ever completes a painting in less than 50 steps?
And what artist ever begins with a completely noisy image then gradually scales it down?
*shaking head.
Now, all of the results that we are seeing, now suddenly makes sense.
This is incredibly well thought out, but that's the problem.
It was based on a very very old system.
It wasn't based on the understanding that our angels teams, whom use the energy from our own bodies to carry out their work, (because our angel teams are tied to us since birth, they share their connections as well as their energy) electrical energy which must be first converted from calories, and is why the Matrix story had any seed of truth to it. We are electrochemical beings by nature. And that electrochemical energy is converted into action and our angel teams, as well as souls whom have passed on that we have loved, all do their best to honor our requests.
I don't like draining my body and aging myself any more than you do lol. So please, dear brother, in the next few years, please see to it that updates are made to these parameters which are more friendly upon the consciousness that we work with.
Everyone understands we have angels. If you had the right frequencies and equipment, you could not only see them but feel them every day in your own life.
Many of us were not taught to seek out the connections and guidance of our own angels.
We were instead taught that we were all small, dirty, and were eventually going to be judged by god.
I hope that these seeds of wisdom helps you to better understand what may have been going on, and that "speed" is not the way, but in actual *Results*.
Slow the parameters down.
Throw out completely the assumption and the foundation and basis of everything that you were taught and start from scratch.
Our systems, transistors, and mosfets, software as well, all run far too fast and they don't take into any account that they are run by our angel teams.
I used to be Jesus in a past life. I work with our angel teams every day. I had a sense as to what was going on, but this hits home for me in a very real way.
There's no call to force our angel teams through hurdles like this. They are creative beings whom are simply doing their best to honor our requests.
Because, our entire universe was created in the support of us.
Every request that we make, however nonsensical or unknowing, is all honored and carried out by Spirit.
The native Americans had a great awareness of this, they just didn't have the language to translate this into a knowledge base that we could all understand.
It's not about speed and rules dear brother. It's about openness and allowing them the time to carry out their works. Stay blessed always in all of your travels. 🌎✨
what. the actual. HELL. was all of that?
Easy on the mushrooms mario…
In the age of quick content a summary would have been nice that also recommends the user which sampler to use. I think in the end that’s what we all want:
1. Use X sampler if you want good result ant good speed.
2. Use Y sampler if you want amazing result at low speed.
Here’s a decent choice:
Good speed – DPM++ 2M Karras.
Good quality – DPM++SDE Karras
Thanks!
I just want to respond on the back of Max’s comment with – even though it was a long read and I also came looking for a quick ‘this is what you should use’, I actually ended up reading almost the entire article and appreciate the time and effort you put into this. I feel like I understand more about it now.
An LCM model beats both of these imo with a k-Euler-Ancestral sampler, using 4-8 steps at 1-2 CFG scale (512×768). Images are super fast and god quality, Using a Lora will also enhance the details at the cost of a little bit of time.
The LCM lora trades quality for speed so the quality should be lower.
In the age of AI generated content, articles like this are what really elevate a good article from the mass.
Thanks for the research and documentation.
Your article mentions Heun as being slower than Euler, but we can generate good images using Heun in just a few steps. For instance, it’s possible to create high-quality images in just 8 steps.
I guess they are not contradictory.
Will the article also be updated for the new DPM++ 3 samplers?
Adding to the list…
Regarding “DPM fast” and “DPM adaptive”, in automatic1111 you can set the “eta” for the k-diffusion samplers with a slider, and this is defaulting to 1. This value gets passed as an argument to all k-diffusion samplers that have it, and all the samplers that have it except for dpm fast and adaptive have it set to default to 1, while fast and adaptive has a default of 0.
Using the intended default for fast and adaptive yields much better results. Fast looks pretty good at 25 steps and doesn’t turn into a mess, and adaptive finishes in half the time. You can observe this by setting eta to 0 in the sampler settings when using these samplers.
Good info, thanks!
Hello, Andrew.
A have been running a local installation of Automatic1111 without incident. This morning, however, upon startup in several consecutive occasions, I am getting a banner at the top of the Automatic1111 interface that says “Bad Scale: 125%. Change your browser or computer settings! Otherwise, it will cause this page not to function properly!” At the bottom of the banner, there’s a “Click to ignore” button. Has this been reported before? I just want to ensure that this is not a potential malicious intrusion, and obviously fix this. I have not changed my browser or computer settings.
Thanks for any assistance you can offer.
I got that too and mine is 200%… There’s a new browser scale checker in A1111 update that is supposed to warn if the scale is not 100%. But apparently it is broken. You can ignore it for now.
Ok, that makes sense. I read some more last night that less than 10 steps, bh1 is best, over 10 steps, bh2 is better. I can’t see how the other parameters make much difference, but setting the order higher may cause problems – I tried setting it at 10 and the generation failed. Also when you use HiresFix UniPC will switch the DDIM anyhow.
I’ve come back to this post of yours several times since starting my journey into stable diffusion. I’d like to share a few things that I’ve learned and ask a question or two. 1st, many checkpoint models were trained with specific samplers, and others just perform totally different with different samplers … so while they all should make something similar – they don’t really in practice. It’s useful to spend a little time testing with a new model both the samplers and the CFG settings to see what you like. If you are making batches of images hoping to get one that is just right – one of the ancestral samplers will give you more variation and converse is true too. Now my question – The UniPC sampler is the newest tech and has a number of configuration settings – could you explain a little about those? I’m really interested in getting the finest detail and texture, and less concerned with generation times. What should I use? Bh2 and Time Uniform? Seems like it from my testing, but not sure. Also what is the UniPC order parameter? What setting for best detail? Thanks!
Hi, the order parameter of UniPC is the order of the ODE solver. You can treat it as how accurate it is. Generally, 2nd order takes twice as much time as a first order one. So you are trading accuracy with time. In my test, I didn’t see UniPC perform any better than others. I think a lot of claimed improvements refers to using in training time and is not relevant for inference.
Great analysis! Thank you so much for putting this together, love the charts, this has saved me lots of time and answers many of the questions I’ve had in one place. Thank you!
there is a new DPM++ 2M SDE Karras, how good is it compared to others? Thank you.
Hey, THANK YOU!!!
Interesting article with a lot of new information for me, but in practice this did not really get into how they react in real life to multiple parameters. Sometimes, to offset high CFG values, much more steps than expected need to be used, and while many of the latter samplers can create good output in 15-25 steps, often I find that small details are better and there’s “more information” in the image with higher step counts of up to 60-80 steps, especially for higher CFG values around 12-16.
If a particular sampling method reaches the low point in the curve at x steps, will it still reach that same point x at a higher image resolution, or with a different text prompt? And is there any reason to set the steps count higher than X? I see so many examples on different sites where they set the steps to like 70 or higher. Is there any benefit in quality when the steps is set to the max?
Thanks,
Eric
Generally speaking, you should not deviate too much from the native resolution (512px for v1 models). Higher resolution should be achieved using an upscaler.
Once the image converges or reaches a state of constant changes (with ancestral samplers), there’s no point in running more steps. Running more steps is technically more accurate, but we don’t know or don’t care about the true solution anyway.
Hi!
In your section on recommendations, you list several things, in particular, though, item 1:
“If you want to use something fast, converging, new, and with decent quality, excellent choices are ”
What seems to be missing is “If you don’t care about fast, but do want converging, new and with best quality,” or something like that.
Speed is of no relevance to me at all. I am most interested in getting the highest quality result.
Having read the article, my interpretation of your data is that the best are DPM++ SDE and DPM++ SDE Karras. Does that seem right?
Sounds reasonable to me.
I noted the same thing. I am sure you were less then satisfied with Andrews answer as I was also. I think why he did not include an obvious clear cut answer is because there is not one. It all depends on what you are trying to accomplish. Highest quality result can mean a lot of things to a lot of different people. If you are trying to get highest quality result of a girl is well likely going to be a different answer then if you are looking for highest quality result of a PARTICULAR girl again and again. (which is my goal and I am noticing that that is not were Stable Diffusion strengths are at.)
Thank you so much for all your hard work! This is my new favorite site for all things SD. This guide explained everything perfectly.
Welcome!
just wanted to say thanks for all the helpful guides… always seem to pop up when I’m searching for something, and I really appreciate it!
You are welcome!
The Euler method (in K diffusion) has its own paper, as the “algorithm 2” of the “momentum sampler”. See if it still matches the Euler method you’ve descrived.
Paper: Soft Diffusion: Score Matching for General Corruptions
https://arxiv.org/abs/2209.05442
Thanks for pointing this paper out. Looks like the Euler method as used in A1111 is the algorithm 1 – Navie sampler but without the noise term (even more naive…)
Thanks for the article. I really enjoy it
Thank you very much, very detailed explanation, I learned a lot.
This blog guided me out of the sampler chaos. Thank you for sharing!
Thank goodness someone has finally clarified these samplers – thanks! (not that I *fully* understand, but this article certainly helps a lot). So for doing ‘comparitive’ tests between samplers, all other settings (including seed) being equal, it’s probably best to avoid the ancestral samplers. That way you can compare your (identical) final images on an ‘apples to apples’ basis.
Thanks a lot. This article let me know my wrong choice of simpler…
Hey man. Thanks a lot for this awesome guide! I go back to it every now and then and it is very valuable. Are you planning to update it at any point? 😉
Cheers
OK, time to read some papers and update!