
Stable Diffusion is getting quite good at generating anime images, thanks to a long list of freely available anime models created by enthusiasts. In this post, you will find
- Some popular anime models
- Anime VAE
- Embeddings that are useful for anime
- Anime-related LoRAs
- Some notes on building anime prompts
- Anime prompt examples
Table of Contents
Software setup
We will use AUTOMATIC1111 Stable Diffusion GUI. You can use this GUI on Windows, Mac, or Google Colab. Check out the Quick Start Guide if you are new to Stable Diffusion.
For anime images, it is common to adjust Clip Skip and VAE settings based on the model you use. It is convenient to enable them in Quick Settings.

On the Settings page, click User Interface on the left panel. In the Quicksetting List, add the following
- CLIP_stop_at_last_layers
- sd_vae
Apply Settings and restart Web-UI.
Anime checkpoint models
You use an anime model to generate anime images. Well, technically, you don’t have to. Stable Diffusion base model CAN generate anime images but you won’t be happy with the results.
Anime models are specially trained to generate anime images. So let’s leave the job to the professionals. You will find the download links to some of the most popular and versatile Stable Diffusion anime models in this section. But first, let’s compare the images generated from these models.
Image comparison
You will see images generated using the following prompt and settings below.
Prompt:
(masterpiece, best quality),1girl, solo, flower, long hair, outdoors, letterboxed, school uniform, day, sky, looking up, short sleeves, parted lips, shirt, cloud, black hair, sunlight, white shirt, serafuku, upper body, from side, pink flower, blurry, brown hair, blue sky, depth of field
Size: 768×512
Seed: 2912044817
Sampler: DPM++ 2M Karras
CFG Scale: 7







Now let’s go through a few models.
Anything v3

Anything v3 is a popular anime model released in the early days of Stable Diffusion. It is fine-tuned from Novel AI’s leaked NAI model. The quality is reported to be better than the original model.
Anything v5
- Model Page
- Download link (Prt-RE)
- Clip skip: 2

Anything v5 is the improved version of Anything v3. There are multiple Anything v5 versions available. Due to the training process, the authors suggest using more detailed and specific prompts.
You may find Anything v4 and v4.5 models. They are not released and maintained by the original authors of Anything v3.
DiscoMix Anime
- Model Page
- Download link
- Clip Skip: 2

DiscoMix is a merged model of Anything v3, Disco and PastelMix. Simple prompts work well with this model.
OrangeMixs
- OrangeMixs Model Page
- Download AbyssOrangeMix3 model
- Clip Skip: 1 or 2
- Prompt: As simple as possible
- Negative prompt: Starts with (worst quality, low quality:1.4)

OrangeMixs generates realistic textures with diverse content. This model can generate both SFW and NFSW content. Use NFSW in the negative prompt for SFW content.
Counterfeit
- Counterfeit Model Page
- Download model
- Trigger keyword:
girl - Negative embedding: EasyNegative

Counterfeit is a popular anime model trained with Dreambooth, merging block weights and LoRA. Natural language prompts should work well because of the training process. The model was trained to produce diverse compositions.
Use Easy Negative (embedding for the negative prompt) with this model to improve the anatomy and image quality.
Don’t forget to include the trigger keyword girl in the prompt!
TMND Mix

TMND Mix can generate complex backgrounds with good lighting. It is a very good general-purpose animal model good for generating a wide range of subjects.
Use OrangeMix VAE to enhance the color.
Silicon29-Dark

Silicon29 is a merge good for general-purpose anime images. The dark version is capable of generating darker images. This is an overlooked model that produces stunning images.
Anime embeddings
Embeddings (aka textual inversion) are specially trained keywords to enhance images generated using Stable Diffusion.
However, there’s a twist. It is common to use negative embeddings for anime. It is simple to use. All you need to do is to download the embedding file stable-diffusion-webui > embeddings and use the extra networks button (under the Generate button) to use them.
Make sure to add to the negative prompt!
Easy Negative

EasyNegative is an embedding that improves the images for anime models such as Counterfeit and AbyssOrangeMix. It should be used in the negative prompt.
Bad Artist Negative Embedding


Bad Artist Negative Embedding can be used in the negative prompt to significantly alter the aesthetic of the images. For the best effect, precede the embedding with “by”, i.e. by bad artist-neg.
Anime LoRA
LoRA is a small modification of Stable Diffusion checkpoint files. Here are some LoRAs that you can use as add-on to the anime checkpoint models.
3D rendering style
- Model Page
- Download link
- Triggering keyword:
3DMM

3DMM Lora adds a 3D rendering style to anime images. You are supposed to use it with the RevAnimated model but I found it also compatible with other anime models.
Mecha Lora
- Model Page
- Download link
- Triggering keyword:
Mecha

This LoRA generates awesome-looking Mecha. You will have no problem using it with Anything v3.
Anime VAEs
VAE (Variational Auto-Encoder) is the part of the neural network that decodes the latent image into the real pixel image. A good VAE can introduce style and add details.
OrangeMix VAE

This VAE improves color and clarity. You can experiment with it if you are unsatisfied with the generation.
kl-f8-anime2

kl-f8-anime2 is one of the best VAEs for anime. It enhances color and sharpens the image.
Use HiRes. Fix to improve color
HiRes. fix can improve the quality of anime images. Here’s how.
Let’s use the following prompt and negative prompt.
masterpiece, best quality, winter, snow field, smile, blush, 1girl, bangs, blue eyes, blunt bangs, bonnet, brown footwear, brown hair, red dress, frills, fruit, full body, hat, long hair, long sleeves, looking at viewer, black pantyhose, red flower, red rose, rose, shoes, sitting, solo, sky, sunset, mountain, forest, lake,
EasyNegative, (worst quality:2), (low quality:2), (normal quality:2) verybadimagenegative_v1.3
(EasyNegative and veryBadImageNegative negative embeddings are used.)
- Sampler: DPM++2M Karras
- Sampling steps: 30
- Size: 768 x 512
- Model: TMND-MIX

It’s decent but a bit blurry. The contrast is a bit low.
Now, let’s enable HiRes fix. Expand the Hires Fix section to enable (It was a checkbox before A1111 version 1.6.0).
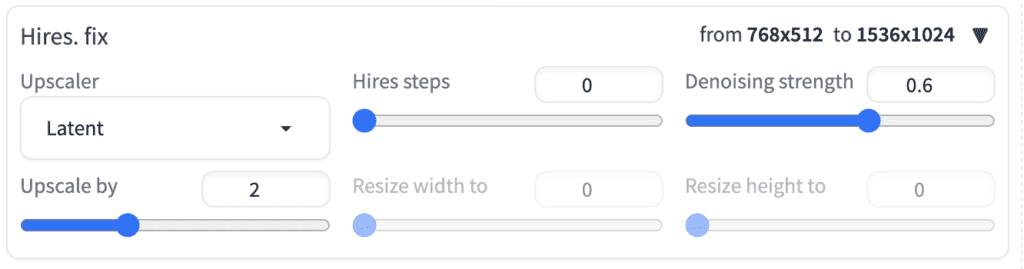
- Hires. fix: Enabled
- Upscale by: 2
- Upscaler: Latent
- Denoising: 0.6

Now you get a clearer image. The color pops out more. This works really well for anime! As a bonus, you get more details on the outfit and the background.
Here’s another HiRes Fix setting that works well.
- Hires. fix: Enabled
- Upscale by: 2
- Upscaler: R-ESRGAN 4x+
- Denoising: 0.2 – 0.5
Anime prompts
Building a good anime prompt
Building a good anime prompt is similar to building a good prompt in general. Read the article if you are unfamiliar with prompt building. Here, I will only talk about things that are specific to anime prompts.
Start with a very simple prompt. It can be as simple as 3 keywords which include the subject, viewing angle, and background. You will be surprised by the quality of the anime images generated.
For the best result, you should use a negative prompt with an anime model. Many of them won’t generate good images with a good negative prompt. A good negative embedding is Easy Negative.
For some reason, high keyword weights can be used with anime models with little negative consequence. Try adventuring in using weights as high as 2. This applies to the negative prompt too.
It is common for anime models to recommend a different Clip Skip than the default value. Read the model page and make sure you are using the correct setting.
Using the Danbooru tags in the prompt goes a long way. Use them to control subjects, view angle, perspective, and composition. (Caution: Some tags are NSFW.)
For example, use the following tags to control the viewing angle.
- from above
- from below
- from side



There are more tags than I can exhaust here. The best way to learn is to try them out.
Prompt examples
1. Torri Shrine
(masterpiece, best quality), 1girl in traditional japanese clothing, with white wolf beside her, standing in front of a a magical torri shrine, 200mm
Model: Anything_v3
2. Face Tattoo

1girl, short hair, torn clothes, messy, face tattoo, face paint, (dirty face, dirty hair:1.1), mischieval smile, jacket, (wearing hood:1.2), dramatic lighting, action shot, heavy shadows, vibrant, paint spray, (graffiti:1.3), (very colorful:1.3), (colorful clothes:1.2), game cg, vibrant color
blurry, (skinny:1.4), by bad-artist, by bad-artist-anime, (from behind:1.1), dim colors, bland, no headwear, low contrast
Model: AbyssOrangeMix3
3. Mechanical girl
1girl, masterpiece, best quality, sitting, full body, indoors, (1 mechanical girl locked on a hanger:1.5),(transparent surfaces and skins:1.5),(many mechanical gears and electronic components inside the body:1.4),(mechanical vertebra and cervial:1.3),solo,expressionless,(wires and cables attaching to head and body:1.4),(mechanical arms of surgical machine around:1.2),(Circuit boards:1.4),(character focus:1.3),science fiction
EasyNegative, (worst quality:2), (low quality:2), (normal quality:2), bad art, ugly
Negative embedding: EasyNegative
Model: TMND Mix
Clip Skip: 2
4. Feathers

(((masterpiece))),best quality, illustration,(beautiful detailed girl), a girl ,solo,bare shoulders,flat_chest,diamond and glaring eyes,beautiful detailed cold face,very long blue and sliver hair,floaing black feathers,wavy hair,black and white sleeves,gold and sliver fringes,a (blackhole) behind the girl,a silver triple crown inlaid with obsidian,(stand) on the black ((mountain)), (depth) of (field),
(worst quality, low quality:1.4), easynegative
Negative embedding: EasyNegative
Model: DiscoMix Anime
Clip Skip: 2
5. Rock Giant

(masterpiece, best quality), a giant made of rock, highly detailed, rock texture
easynegative
Negative embedding: EasyNegative
Model: Silicon29-Dark
Clip Skip: 2
6. Starry night

octans, sky, star(sky), scenery, starry sky, night, night sky, outdoors, building, cloud, milky way, sitting, tree, city, silhouette, cityscape
easynegative
Negative embedding: EasyNegative
Model: Anything v5
Clip Skip: 2
Reference
- Evaluation of the latent horniness of the most popular anime-style SD models – This post provides valuable insights in the generation bias in some popular anime models.
- Tag Groups Wiki | Danbooru – You can generate anything if you master this list!
Hello,
I love your site and I even purchased your guide (and read the whole thing) and prompt generator. I was going to ask about the hires fix settings. I don’t see any checkmark and when I change the denoising to 0.6 I get bad results. I’m using Anything v3 and Anything v3 VAE. Is the layout different in the new stable-diffusion-webui?
Thanks for reading and please reply when you get the chance.
Hi Gopal, thank you for your support!
Yes, the layout has changed in A1111 v1.6.0. I updated the figure in the article.
I just tried. But besides the GUI change, it is working the same as before.
The result is bad in what way?
0.6 comes out kind of blurry with weird effects, but 0.7 comes out fine. I don’t understand why. But my biggest problerm is with inpainting, is there some kind of trick to get it to work good whenever I do it I get bad results mostly, and I followed your guide as well.
What does 1boy or 1girl mean in the prompts?
It’s danbooru tags.
You can see in danbooru wiki:
“An image depicting one female character.
Dolls only count if they act on their own.
Depictions of characters in paintings, etc don’t count unless it plays a major role in the work.
If the presence of a character is only implicated, it doesn’t count.”,
“An image depicting one male character.
Anthropomorphic characters (such as dolls) only count if they act on their own.
Depictions of characters (for example, on paintings) don’t count unless they play a major role in the work.
If the presence of a character is only implicated, it doesn’t count.”