
Video generation with Stable Diffusion is improving at unprecedented speed. In this post, you will learn how to use AnimateDiff, a video production technique detailed in the article AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning by Yuwei Guo and coworkers.
AnimateDiff is one of the easiest ways to generate videos with Stable Diffusion. In the most basic form, you only need to write a prompt, pick a model, and turn on AnimateDiff!
This is what AnimateDiff videos look like.


We will cover:
- How AnimateDiff works
- Installing the AnimateDiff extension
- Step-by-step guide to generating a video
- Advanced settings
- Using Motion LoRA to enhance movement
- Stylize a video with ControlNet and AnimateDiff
- Using AnimateDiff with image-to-image
- AnimateDiff prompt travel
- Increase resolution with high res fix
- Speeding up AnimateDiff
Table of Contents
- What is AnimateDiff?
- Software setup
- Installing AnimateDiff extension
- Downloading motion modules
- Generating a video with AnimateDiff
- Advanced options
- Video-to-video with AnimateDiff
- Motion LoRA
- Image-to-image
- AnimateDiff Prompt travel
- Increasing resolution with Hi Res fix
- AnimateDiff v3
- AnimateDiff for SDXL
- Speeding up AnimateDiff
- Troubleshooting
What is AnimateDiff?
AnimateDiff turns a text prompt into a video using a Stable Diffusion model. You can think of it as a slight generalization of text-to-image: Instead of generating an image, it generates a video.
How does AnimateDiff work?
But how does it do that?
AnimateDiff uses a control module to influence a Stable Diffusion model. It is trained with a variety of short video clips. The control module conditions the image generation process to produce a series of images that look like the video clips it learns.
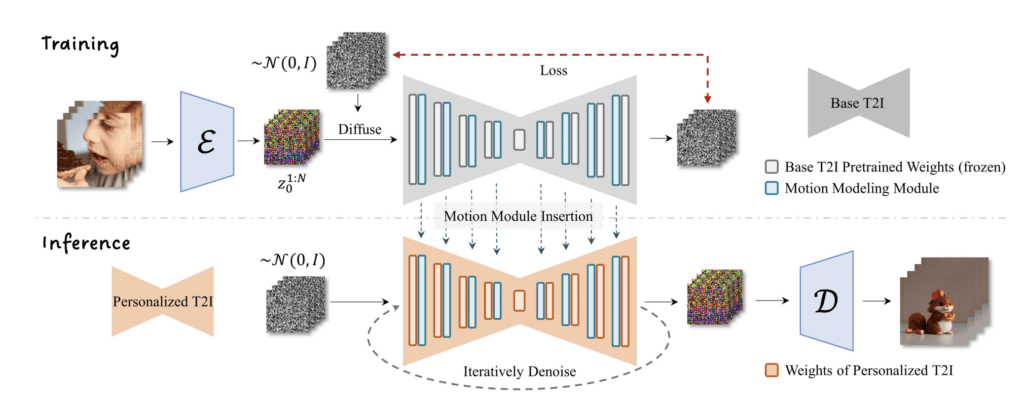
Like ControlNet, the control module of AnimateDiff can be used with ANY Stable Diffusion model. Currently, only Stable Diffusion v1.5 models are supported.
Limitation of AnimateDiff
Since it follows the motion learned from the training data, it produces a generic motion that’s typically seen. It won’t produce a video that follows a detailed sequence of motions in the prompt.
The quality of motion is sensitive to the training data. It can’t animate exotic graphics that is not present in the training data. Keep this in mind when you choose what to animate. Not all subjects and styles are equal.
There are tricks to improve the motion:
- Change the prompt during video generation. This technique is called prompt travel.
- Use a reference video with ControlNet.
You will learn both techniques in this article.
Software setup
We will use AUTOMATIC1111 Stable Diffusion WebUI. It is a popular and free open-source software. You can use this GUI on Windows, Mac, or Google Colab.
Check out the Quick Start Guide if you are new to Stable Diffusion. Check out the AUTOMATIC1111 Guide if you are new to AUTOMATIC1111.
Installing AnimateDiff extension
We will use the AnimateDiff extension for Stable Diffusion WebUI.
Google Colab
Installing AnimateDiff in the Colab Notebook in the Quick Start Guide is easy. All you need to do is check the AnimateDiff option in the Extensions section.

Windows or Mac
To install the AnimateDiff extension in AUTOMATIC1111 Stable Diffusion WebUI:
- Start AUTOMATIC1111 Web-UI normally.
2. Navigate to the Extension Page.
3. Click the Install from URL tab.
4. Enter the extension’s URL in the URL for extension’s git repository field.
https://github.com/continue-revolution/sd-webui-animatediff5. Wait for the confirmation message that the installation is complete.
6. Restart AUTOMATIC1111.
Downloading motion modules
(You don’t need to do this step if you are using our Colab notebook.)
You need to download at least one motion module before using AnimateDiff. They can be found on the original authors’ Hugging Face page.
If you only want to download the latest versions of the motion modules, get:
- mm_sdxl_v10_beta.safetensors — SDXL version
- mm_sd15_v3.safetensors — SD 1.5 version
Here are the older versions.
- mm_sd_v15_v2.ckpt — This tutorial also uses the v2 model. It’s fine to substitute with v3.
- mm_sd_v15.ckpt
- mm_sd_v14.ckpt
Put the motion module ckpt files in the folder stable-diffusion-webui > extensions > sd-webui-animatediff > model.
Generating a video with AnimateDiff
Let’s generate a video of a happy girl trying out her new armor in the living room.
Step 1: Select a Stable Diffusion model
I’m going with a realistic character in this example. Let’s use CyberRealistic v3.3. Download the model and put it in stable-diffusion-webui > models > Stable-Diffusion.
In the Stable Diffusion checkpoint dropdown menu, select cyberrealistic_v33.safetensors.
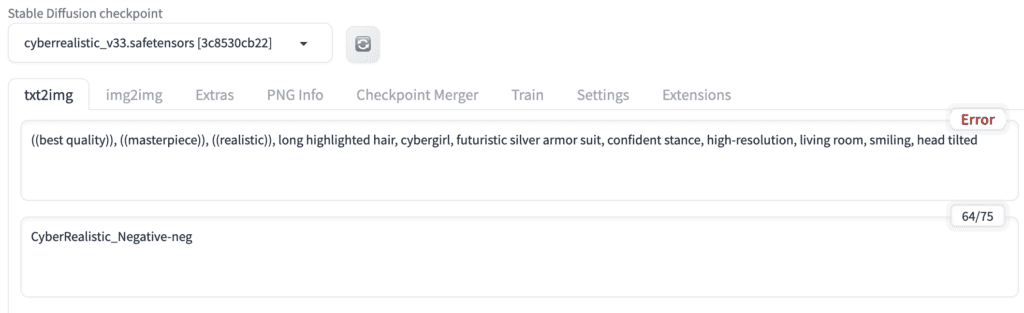
Step 2: Enter txt2img settings
On the txt2img page, Enter the following settings.
- Prompt
((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted
CyberRealistic_Negative-neg
Note: CyberRealistic_Negative is a negative embedding (guide to install).
- Steps: 20
- Sampler: DPM++ 2M Karras
- CFG scale: 10
- Seed: -1
- Size: 512×512
Adjust the batch count to generate multiple videos in one go.
Step 3: Enter AnimateDiff settings
On the txt2img page, scroll down to the AnimateDiff section.
Enter the following settings.
- Motion Module: mm_sd_v15_v2.ckpt
- Enable AnimateDiff: Yes
- Number of frames: 32 (This is the length of the video)
- FPS: 8 (This is frame per second. So the video length is 32 frames / 8 fps = 4 secs)
You can leave the rest as default.
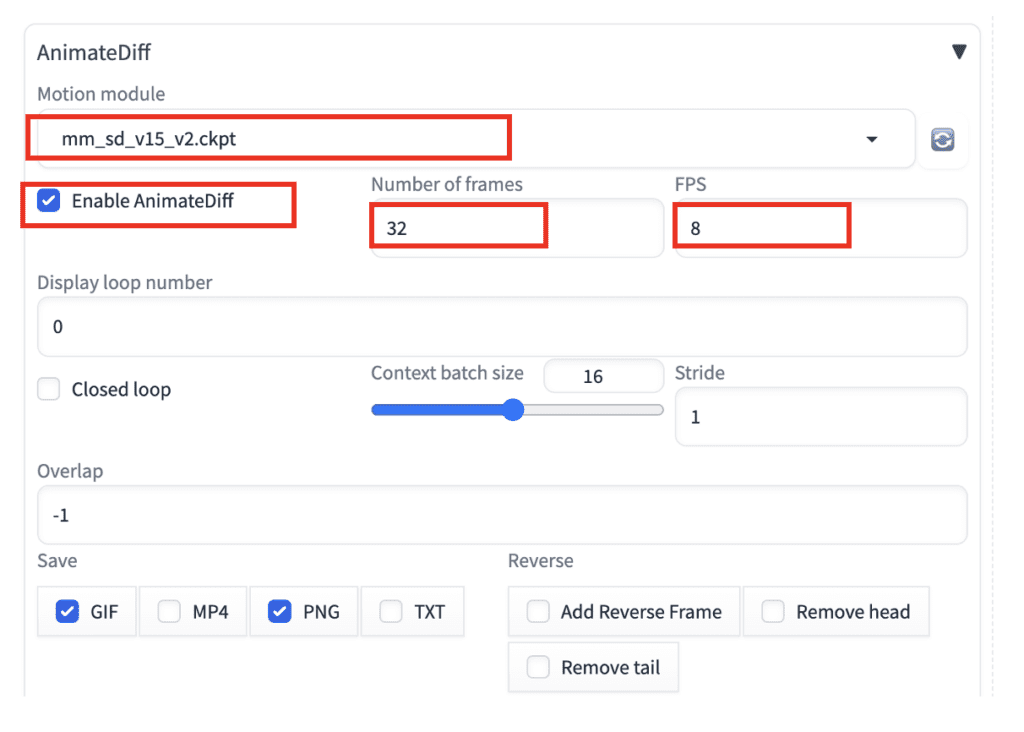
Select MP4 in the Save options if you want to save an MP4 video.
Step 4: Generate the video
Press Generate to create a video. You should get something similar to this.
Advanced options
You can find detailed explanations of parameters on the GitHub page. Below are some explanations with illustrated examples.
Close loop
The close loop option makes a video continuous. That is the first frame, the same as the last frame. So you won’t see the sudden jump when transitioning from the last to the first frame.
- N: Close loop is not used.
- R-P: Reduce the number of closed-loop contexts. The prompt travel will NOT be interpolated to be a closed loop.
- R+P: Reduce the number of closed-loop contexts. The prompt travel WILL BE interpolated to be a closed loop.
- A: Make the last frame the same as the first frame. The prompt travel WILL BE interpolated to be a closed loop.


Frame interpolation
Frame interpolation makes the video look smoother by increasing the number of frames per second.
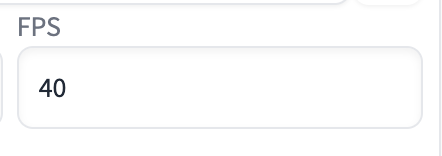
Set Frame Interpolation to FILM, and Interp X to a multiplier of FPS. E.g. Setting it to 5 makes an 8 FPS video 40 FPS.

For some reason, you will need to set FPS to 8 times 5 = 40 FPS in order to make the animated GIF look right. Otherwise, it would be in slow motion.

Context batch size
Context batch size controls the temporal consistency. A higher context batch size makes the video changes less. A small value makes it change more.
But the quality seems to degrade when it is different from 16. So it is better to keep it at 16.



Video-to-video with AnimateDiff
You can direct the motion with a reference video using ControlNet.
Let’s use this reference video as an example. The goal is to have AnimateDiff follow the girl’s motion in the video.
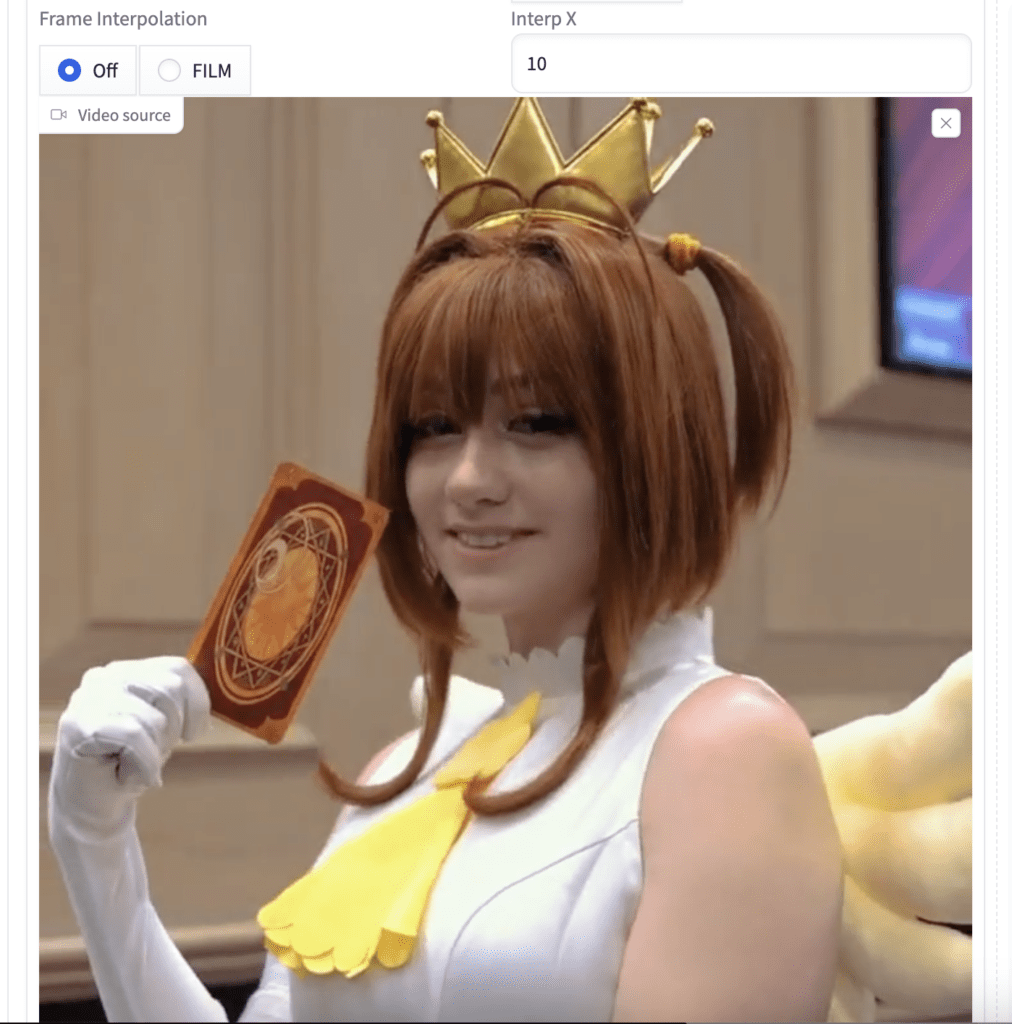
Step 1: Upload video
On the txt2img page, scroll down the AnimateDiff section.
Upload the video to the Video source canvas.
Step 2: Enter AnimateDiff settings
The number of frames and FPS parameters should match the video. They should have populated automatically. They are:
- Number of frames: 96
- FPS: 29
Don’t forget to enable AnimateDiff.
- Enable AnimateDiff: Yes
Step 3: Enter txt2img settings
The txt2img parameters are:
- Checkpoint model: cyberrealistic_v33.safetensors
- Prompt
((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted
- Negative Prompt:
CyberRealistic_Negative-neg
- Steps: 20
- Sampler: DPM++ 2M Karras
- CFG scale: 10
- Seed: -1
- Size: 512×512
Step 4: Turn on ControlNet
You must enable ControlNet to copy the reference’s video.
In the ControlNet Unit 0 section:
Let’s use DW Openpose.
- Enable: Yes
- Preprocessor: dw_openpose_full
- Model: Openpose
Step 5: Generate video
Press Generate.
(The AnimateDiff extension is finicky. If it errors out, try to press Generate again. If it still doesn’t work, restart A1111 completely and try again.)
Openpose
Here’s the AnimateDiff video with Openpose.

You can see the pose is translating well, but other objects and background keep changing.
Canny
You can also use Canny Edge detection for OpenPose.
- Enable: Yes
- Preprocessor: Canny
- Model: Canny
- Control weight: 1

HED and OpenPose
Let’s use TWO ControlNet to fix the pose AND the lines.
ControlNet 0:
- Enable: Yes
- Preprocessor: Softedge_HED
- Model: control_v11p_sd15_softedge
- Control weight: 0.5
ControlNet 1:
- Enable: Yes
- Preprocessor: dw_openpose_full
- Model: control_v11p_sd15_openpose
- Control weight: 0.5

Motion LoRA
You can use motion LoRA to add camera movement to the video. They are used in the same way as the standard LoRA.
Installing motion LoRA
You can download the motion LoRAs at the following link.
Download all files with lora as part of the filename.
Put them in stable-diffusion-webui > models > Lora.
Using motion LoRA
All you need to do is add the motion LoRA in the prompt. So, for example,
Prompt:
((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted <lora:v2_lora_PanLeft:1>
Negative prompt:
CyberRealistic_Negative-neg
You see the background is moving to the right, suggesting the camera is panning to the left.

But using LoRA weight 1 seems to create an artifact in the background. Reducing the LoRA weight to 0.75 produces better results.
((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted <lora:v2_lora_PanLeft:0.75>

Zoom in:

Zoom out:

Image-to-image
You can direct the composition and motion to a limited extent by using AnimateDiff with img2img. In this method, you can define the initial and final images of the video. They cannot be used exactly because they will undergo the image-to-image process.
Navigate to the img2img page in AUTOMATIC1111.
Enter the img2img settings.
- Prompt:
((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted <lora:v2_lora_ZoomOut:1>
- Negative prompt:
CyberRealistic_Negative-neg
Upload the initial image to the image canvas of the img2img tab.
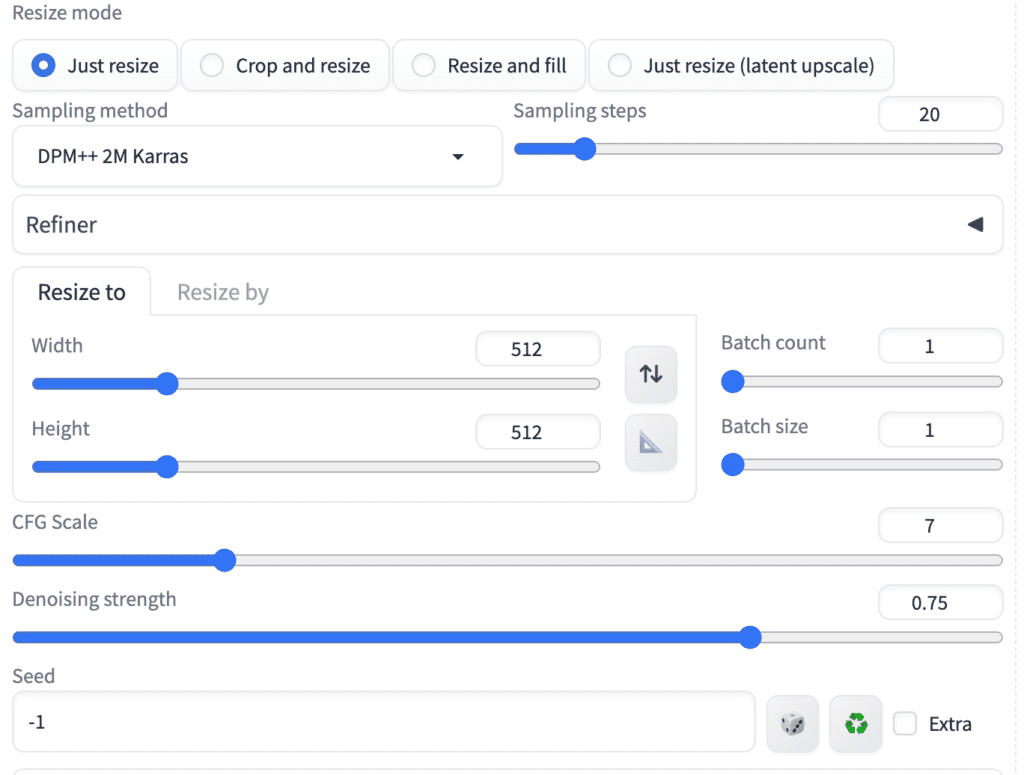
- Steps: 20
- Sampler: DPM++ 2M Karras
- CFG scale: 7
- Seed: -1
- Size: 512×512
- Denoising strength: 0.75
- Motion Module: mm_sd_v15_v2.ckpt
- Enable AnimateDiff: Yes
- Number of frames: 32
- FPS: 8
You can leave the rest as default.
Upload an image to the optional last frame canvas.
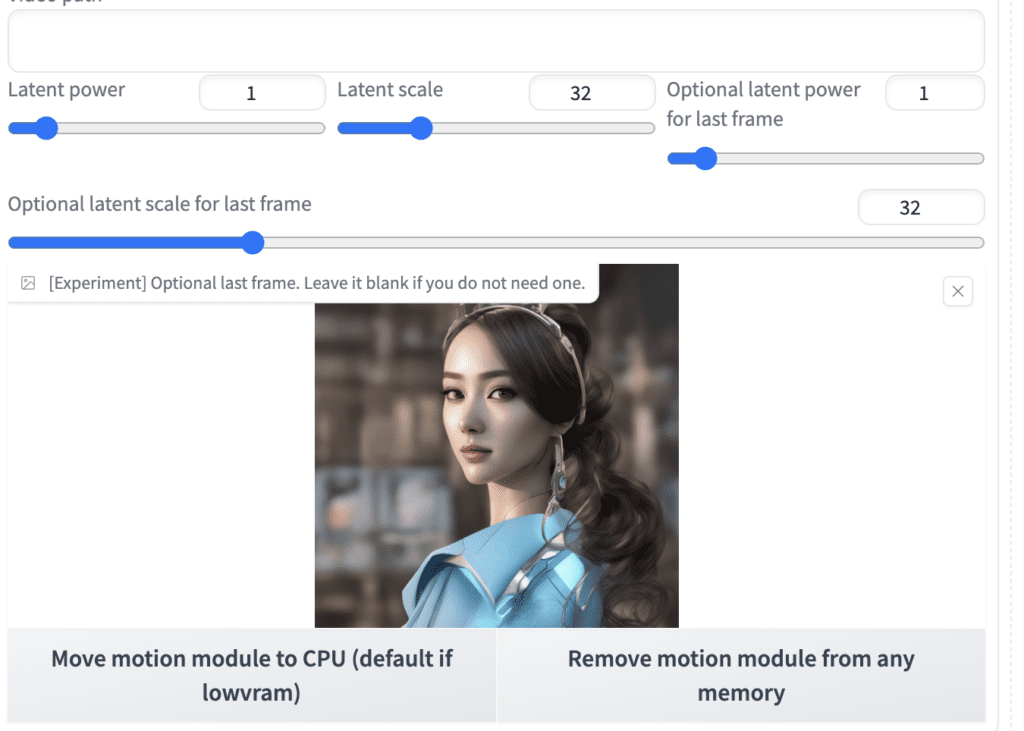
Press Generate.

AnimateDiff Prompt travel
Do you feel the motion of AnimateDiff is a bit lacking? You can increase the motion by specifying different prompts at different time points. This feature is generally known as prompt travel in the Stable Diffusion community.
This is how prompt travel works. Let’s say you specify prompt 1 at the 1st frame and prompt 2 at the 10th frame. The prompts at frame 1 and frame 10 are prompt 1 and prompt 2 for sure. It interpolates the prompts between frame 1 and frame 10.
Without prompt travel
Prompt:
(masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl), extreme detailed,(fractal art:1.3),colorful,highest detailed
Negative prompt:
(worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, normal quality, ((monochrome)), easynegative, badhandv4

With prompt travel
Use the prompt in the following format to use prompt travel
(masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl), extreme detailed,(fractal art:1.3),colorful,highest detailed
0: smile
8: (arm over head:1.2)
studio lighting
The first line is the prompt prefix. The last line is the prompt suffix. They are added to the beginning and ending of the prompt, respectively.
In the middle, we specify the prompts at different frames.
Here’s what you get:
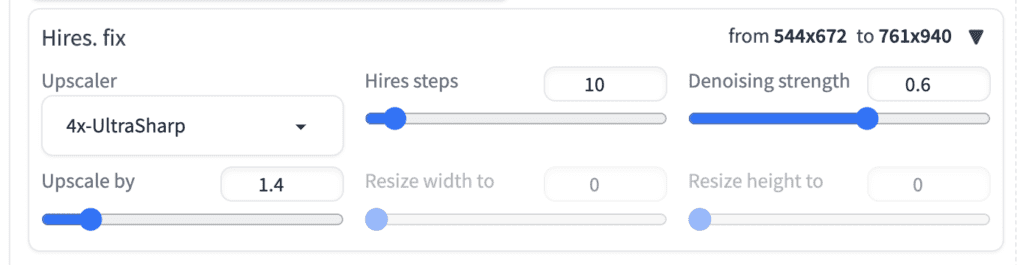
Increasing resolution with Hi Res fix
You can use AnimateDiff with Hi Res fix to increase resolution.
- Upscaler: 4x-UltraSharp
- Hires steps: 10
- Denoising strength: 0.6
- Upscale by: 1.4

AnimateDiff v3
AnimateDiff v3 is not a new version of AnimateDiff, but an updated version of the motion module. All you need to do to use it is to download the motion module and put it in the stable-diffusion-webui > models > animatediff folder.
Download the v3 motion module for AUTOMATIC1111.
You can use the Animate v3 motion module the same way as v2.
Model: Hello Young
Prompt:
(masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl), extreme detailed,(fractal art:1.3),colorful,highest detailed
Negative prompt:
(worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, normal quality, ((monochrome)), easynegative, badhandv4
This is an AnimateDiff video using AnimateDiff v3.

Below is an animation with the same settings but using the v2 model for comparison.

In my testing, I cannot say v3 is better than v2. They generate different motions. You can keep both in your toolbox and see which one works better in your particular workflow.
AnimateDiff for SDXL
AnimateDiff SDXL is not a new version of AnimateDiff, but a motion module that is compatible with the Stable Diffusion XL model. You need to download the SDXL motion module and put it in the stable-diffusion-webui > models > animatediff folder.
You can use the Animate SDXL motion module the same way as other motion modules. Remember to set it to an image size compatible with the SDXL model, e.g. 1024 x 1024.
You can use any SDXL model, not just the base model.
Below is an example of AnimateDiff SDXL.
Checkpoint Model: dreamshaperXL10_alpha2Xl10
Prompt:
In Casey Baugh’s evocative style, art of a beautiful young girl cyborg with long brown hair, futuristic, scifi, intricate, elegant, highly detailed, majestic, Baugh’s brushwork infuses the painting with a unique combination of realism and abstraction, greg rutkowski, surreal gold filigree, broken glass, (masterpiece, sidelighting, finely detailed beautiful eyes: 1.2), hdr, realistic painting, natural skin, textured skin, closed mouth, crystal eyes, butterfly filigree, chest armor, eye makeup, robot joints, long hair moved by the wind, window facing to another world, Baugh’s distinctive style captures the essence of the girl’s enigmatic nature, inviting viewers to explore the depths of her soul, award winning art
Negative prompt:
ugly, deformed, noisy, blurry, low contrast, text, BadDream, 3d, cgi, render, fake, anime, open mouth, big forehead, long neck
Image size: 1024 x 1024
Motion module: mm_sdxl_v10_beta.safetensors

Speeding up AnimateDiff
Video generation can be slow. AnimateDiff is no exception. Here are a few ways you can speed up video generation with AnimateDiff.
LCM LoRA
LCM LoRA is a LoRA model for speeding up Stable Diffusion. You can expect the video generation to be 3 times faster.
Follow the LCM LoRA tutorial to install the LCM LoRA modules. There are SD 1.5 and SDXL versions available.
The image settings of LCM LoRA is quite different. It is important to first nail down the settings without using AnimateDiff.
Model: Hello Young
Sampling method: LCM
Sampling steps: 7
CFG Scale: 2
Prompt:
(masterpiece, top quality, best quality, official art, beautiful and aesthetic:1.2), (1girl), extreme detailed,(fractal art:1.3),colorful,highest detailed <lora:lcm_lora_sd15:1>
Negative prompt:
(worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, normal quality, ((monochrome)), easynegative, badhandv4
With AnimateDiff off, it generates a good image.

Now, turn AnimateDiff on.
Motion Module: mm_sd15_v3.safetensors
Enable AnimateDiff: Yes

SDXL Turbo
SDXL Turbo models have the same architecture as other SDXL models but the Turbo training method enables fewer sampler steps. You can expect the video generation to be 3 times faster.
Checkpoint Model: dreamshaperXL10_alpha2Xl10
It is important to use the following sampling method, steps, and CFG scale. Or else the quality would be poor.
Sampling method: DPM++ SDE Karras
Sampling steps: 7
CFG Scale: 2
Prompt:
In Casey Baugh’s evocative style, art of a beautiful young girl cyborg with long brown hair, futuristic, scifi, intricate, elegant, highly detailed, majestic, Baugh’s brushwork infuses the painting with a unique combination of realism and abstraction, greg rutkowski, surreal gold filigree, broken glass, (masterpiece, sidelighting, finely detailed beautiful eyes: 1.2), hdr, realistic painting, natural skin, textured skin, closed mouth, crystal eyes, butterfly filigree, chest armor, eye makeup, robot joints, long hair moved by the wind, window facing to another world, Baugh’s distinctive style captures the essence of the girl’s enigmatic nature, inviting viewers to explore the depths of her soul, award winning art
Negative prompt:
ugly, deformed, noisy, blurry, low contrast, text, BadDream, 3d, cgi, render, fake, anime, open mouth, big forehead, long neck
Image size: 1024 x 1024
Motion module: mm_sdxl_v10_beta.safetensors

Troubleshooting
AnimateDiff produces 2 distinct videos instead of one
The prompt may be too long. In AUTOMATIC1111 > Settings > Optimization, Check Pad prompt/negative prompt to be same length.
I got this error:
EinopsError: Error while processing rearrange-reduction pattern “(b f) d c -> (b d) f c”. Input tensor shape: torch.Size([2, 4096, 320]). Additional info: {‘f’: 16}. Shape mismatch, can’t divide axis of length 2 in chunks of 16
Any idea what I can do about this? It’s all gibberish to me.
Can you guys tell me why Animatefiff+PromptTravel are ignoring my LORAs? I can’t do it anymore… Tried a huge number of combinations of models, VAE, prompts, negative prompts, installed freeU – all useless.
1) https://imgur.com/a/ohL9vJZ
There are two videos in this link, prompts and checkpoints are different (just that these are the best examples), but the idea is the same – girl1 -> robot1 -> girl2 -> robot2
In the first one, I didn’t use LORAs and I see the transformation of the girl into a robot. In the second – I used LORAs of specific characters, but it doesn’t work, robots don’t appear.
2) A simpler example:
https://drive.google.com/file/d/1QHmhHgKCwz5659mvbhoLshxCmowKcc3q/view?usp=sharing
https://drive.google.com/file/d/1zM6WU0bvjLwGAoi0CXSg0q70T9RYin-U/view?usp=sharing
There is only girl1 and robot1. In the first case, the second prompt is simply ignored. In the second video I didn’t use LORAs – there’s a transformation into some kind of robot..
3) Even simpler example, without robot, girl1 and girl2, also without LORAs in the second video:
https://drive.google.com/file/d/1Bo7thtPfkQJz4WXFHRAsY32jI2moCRzU/view?usp=sharing
https://drive.google.com/file/d/1P1oZXf2xIaFcttZ5-qZVlPCSy1aHqvhh/view?usp=sharing
As you can see – in the first case some strange mix of two prompts is used without transition between the specifically mentioned ones
What am I doing wrong?
My main prompt (it’s different from the attached video, but the point is the same):
0: (best quality, masterpiece, colorful, dynamic angle, highest detailed), upper body photo, fashion photography of cute blue short hair girl (Ayanami Rei), (red eyes:1.3), dressing high detailed Evangelion white suit, plugsuit, interface headset, in dynamic pose, (intricate details, hyperdetailed:1.15), moonlight passing through hair, (official art, extreme detailed, highest detailed), HDR+,
16: (huge android:1.3), cinematic photo, Eva 00, evagod, Evangelion Mecha, , looking at viewer, (official art, Best quality, masterpiece:1.2), full-length, high-tech, high resolution, very detailed, scientific anatomy, futurism, epic
32: (best quality, masterpiece, colorful, dynamic angle, highest detailed), upper body photo, fashion photography of cute red long hair girl (Asuka Langley), (blue eyes:1.3), dressing high detailed Evangelion red suit, plugsuit, interface headset, in dynamic pose, (intricate details, hyperdetailed:1.15), moonlight passing through hair, (official art, extreme detailed, highest detailed), HDR+,
48: cinematic photo, Eva 02, evagod, Evangelion Mecha, , looking at viewer, (official art, Best quality, masterpiece:1.2), full-length, high-tech, huge android, high resolution, very detailed, scientific anatomy, futurism, epic
Prompts for short examples:
2) 0: (Ayanami Rei:1.2), (neon genesis evangelion:1.1), masterpiece, blue hair, red eyes, best quality, plug suit, perfect hands, perfect anatomy, perfect lighting,
16: (huge android:1.3), Eva 00, evagod, Evangelion Mecha, looking at viewer, (official art, Best quality, masterpiece:1.2), full-length, high-tech, high resolution, very detailed, scientific anatomy, futurism, epic,
3) 0: (Ayanami Rei:1.2), (neon genesis evangelion:1.1), masterpiece, blue hair, red eyes, best quality, plug suit, perfect hands, perfect anatomy, perfect lighting,
16: (Asuka Langley:1.2), (neon genesis evangelion:1.1), asuka langley soryu, orange hair, hair between eyes, blue eyes, masterpiece, best quality, plug suit, perfect hands, perfect anatomy, perfect lighting,
Animateiff adds another conditioning. The image could look different. You can increase the lora weight, reduce the animatediff control weight, or switch to another animatediff controlnet.
Thank you for sharing tutorials. Just reporting error messages in txt2img.
*********
EinopsError: Error while processing rearrange-reduction pattern “(b f) d c -> (b d) f c”. Input tensor shape: torch.Size([2, 4096, 320]). Additional info: {‘f’: 16}. Shape mismatch, can’t divide axis of length 2 in chunks of 16
*******
I tried some conditions with animdiff and searched for a solution, but so far I haven’t been able to pass. Thanks.
AnimateDiff is flincky. Try toggle it on and off to see if it resolves…
If not, you can post the steps to reproduce the error.
I have the same issue: EinopsError: Error while processing rearrange-reduction pattern “(b f) d c -> (b d) f c”. Input tensor shape: torch.Size([2, 4096, 320]). Additional info: {‘f’: 16}. Shape mismatch, can’t divide axis of length 2 in chunks of 16
And the steps to reproduce are very easy – just try to start colab notebook and try to use animateDiff. After that the error occurs even without animateDiff
Hi Andrew,
Should I be concerned about using .ckpt files over .safetensor?
The LoRA models here are .ckpt?
Thanks,
V
Some models are not available in safetensors format. I would say use at your own risk. I am generally comfortable if they are downloaded from a trust source, e.g. original author’s repo.
I delete all ckpt models in AnimateDiff. Only safetensors models works properly. There are the two models “mm_sdxl_v10_beta.safetensors” and “mm_sd15_v3.safetensors”. Thats all what you need. A note about motion LoRA “v2_lora_*.ckpt” models. They works only with SD1.5 Model. SDXL produces errors without useful results. I hope this motion LoRA come for SDXL too.
A note about calculating speed. With LoRA LCM Model (SD1.5 and SDXL) the speed is really faster, but the result can be different as without it. Anyway is the speed to slow for me. My computer has 32GB RAM and a Nvidia 3060 12GB graphics card. All memory will be used with AnimateDiff and the calculating time need hours for 4 sec. animation. If you use Hires.fix and/or Adetailer needs days to calculate a animation. This is for me too much. There is only one what you can do. Try, try, try. 😉
Thanks for sharing!
Hello,
I am somewhat confused by Prompt Travel. In the example we say the use of 1-10. I assume this 1-10 frames? So if I have 96 frames, if I choose this:
0:(((laughing))),
80:(staring:1.2),
from the start of the new animation it will prompt the girl in the silver armor, in a living room to be laughing, then by frame 80 it will start to process a stare?
Is this correct?
Thanks,
V
I believe it is doing an interpolation between 0 and 80. i.e. The prompt gradually changes from that specified in 0 to that in 80.
Nice tutorial thanks . For the hello young LCM example the is missing from the promp
good catch. thanks!
Running on a Mac, using mm_sd_v15_v2.ckpt, or any model for that matter. When I go to generate nothing really happens and terminal stops here.
To create a public link, set `share=True` in `launch()`.
Startup time: 4.2s (import torch: 1.4s, import gradio: 0.5s, setup paths: 0.5s, other imports: 0.5s, load scripts: 0.4s, create ui: 0.3s, gradio launch: 0.3s).
Applying attention optimization: sub-quadratic… done.
Model loaded in 8.1s (load weights from disk: 0.5s, create model: 0.5s, apply weights to model: 5.4s, apply float(): 1.1s, load VAE: 0.4s, calculate empty prompt: 0.1s).
2024-01-22 00:30:08,417 – AnimateDiff – INFO – AnimateDiff process start.
2024-01-22 00:30:08,418 – AnimateDiff – INFO – Loading motion module mm_sd_v15_v2.ckpt from /Users/brodyvangoodlife/stable-diffusion-webui/extensions/sd-webui-animatediff/model/mm_sd_v15_v2.ckpt
Calculating sha256 for /Users/brodyvangoodlife/stable-diffusion-webui/extensions/sd-webui-animatediff/model/mm_sd_v15_v2.ckpt: 69ed0f5fef82b110aca51bcab73b21104242bc65d6ab4b8b2a2a94d31cad1bf0
2024-01-22 00:30:10,352 – AnimateDiff – INFO – Guessed mm_sd_v15_v2.ckpt architecture: MotionModuleType.AnimateDiffV2
2024-01-22 00:30:12,871 – AnimateDiff – WARNING – Missing keys
2024-01-22 00:30:14,655 – AnimateDiff – INFO – Injecting motion module mm_sd_v15_v2.ckpt into SD1.5 UNet middle block.
2024-01-22 00:30:14,655 – AnimateDiff – INFO – Injecting motion module mm_sd_v15_v2.ckpt into SD1.5 UNet input blocks.
2024-01-22 00:30:14,655 – AnimateDiff – INFO – Injecting motion module mm_sd_v15_v2.ckpt into SD1.5 UNet output blocks.
2024-01-22 00:30:14,655 – AnimateDiff – INFO – Setting DDIM alpha.
2024-01-22 00:30:14,671 – AnimateDiff – INFO – Injection finished.
2024-01-22 00:30:14,671 – AnimateDiff – INFO – Hacking LoRA module to support motion LoRA
2024-01-22 00:30:14,672 – AnimateDiff – INFO – Hacking CFGDenoiser forward function.
0%|
Please Let me know if i’m missing something Andrew. I also deleted the venv folder updated AUTOMATIC1111 Web-UI. and double checked all the settings?
Running on a M2 Max 16gb macbook pro
Appreciate your help
I don’t know how much support they have on Mac. You can go to their repos and raise an issue.
Sorry super newb question, but the repos for STABLE DIFFUSION?, AUTOMATIC1111? Or AnimateDiff?
Animatediff
Hi Andrew,
when I use the FILM option, this is what I get:
FILM progress: 100% 199/199 [02:04= 1
*** Error running postprocess: /content/drive/MyDrive/AI/stable-diffusion-webui/extensions/sd-webui-animatediff/scripts/animatediff.py
Traceback (most recent call last):
File “/content/drive/MyDrive/AI/stable-diffusion-webui/modules/scripts.py”, line 651, in postprocess
script.postprocess(p, processed, *script_args)
File “/content/drive/MyDrive/AI/stable-diffusion-webui/extensions/sd-webui-animatediff/scripts/animatediff.py”, line 96, in postprocess
AnimateDiffOutput().output(p, res, params)
File “/content/drive/MyDrive/AI/stable-diffusion-webui/extensions/sd-webui-animatediff/scripts/animatediff_output.py”, line 42, in output
video_paths += self._save(params, frame_list, video_path_prefix, res, i)
File “/content/drive/MyDrive/AI/stable-diffusion-webui/extensions/sd-webui-animatediff/scripts/animatediff_output.py”, line 175, in _save
imageio.imwrite(
File “/usr/local/lib/python3.10/dist-packages/imageio/v3.py”, line 139, in imwrite
with imopen(
File “/usr/local/lib/python3.10/dist-packages/imageio/core/v3_plugin_api.py”, line 367, in __exit__
self.close()
File “/usr/local/lib/python3.10/dist-packages/imageio/plugins/pyav.py”, line 789, in close
self._flush_writer()
File “/usr/local/lib/python3.10/dist-packages/imageio/plugins/pyav.py”, line 1193, in _flush_writer
self._container.mux(packet)
File “av/container/output.pyx”, line 211, in av.container.output.OutputContainer.mux
File “av/container/output.pyx”, line 232, in av.container.output.OutputContainer.mux_one
File “av/container/core.pyx”, line 285, in av.container.core.Container.err_check
File “av/error.pyx”, line 336, in av.error.err_check
av.error.ValueError: [Errno 22] Invalid argument: ‘/content/drive/MyDrive/AI/stable-diffusion-webui/outputs/txt2img-images/AnimateDiff/2023-12-04/00003-1688266874.gif’; last error log: [gif] Application provided invalid, non monotonically increasing dts to muxer in stream 0: 1 >= 1
—
ERROR:libav.gif:Application provided invalid, non monotonically increasing dts to muxer in stream 0: 3 >= 3
Exception ignored in:
Traceback (most recent call last):
File “/usr/local/lib/python3.10/dist-packages/imageio/core/v3_plugin_api.py”, line 370, in __del__
self.close()
File “/usr/local/lib/python3.10/dist-packages/imageio/plugins/pyav.py”, line 789, in close
self._flush_writer()
File “/usr/local/lib/python3.10/dist-packages/imageio/plugins/pyav.py”, line 1193, in _flush_writer
self._container.mux(packet)
File “av/container/output.pyx”, line 211, in av.container.output.OutputContainer.mux
File “av/container/output.pyx”, line 232, in av.container.output.OutputContainer.mux_one
File “av/container/core.pyx”, line 285, in av.container.core.Container.err_check
File “av/error.pyx”, line 336, in av.error.err_check
av.error.ValueError: [Errno 22] Invalid argument: ‘/content/drive/MyDrive/AI/stable-diffusion-webui/outputs/txt2img-images/AnimateDiff/2023-12-04/00003-1688266874.gif’; last error log: [gif] Application provided invalid, non monotonically increasing dts to muxer in stream 0: 3 >= 3
At this point the script terminates itself.
As far as I can tell, everything is up-to-date. Without the FILM option it works (I’m using a video + OpenPose). What am I doing wrong?
Cheers!
Hi! Would love help here – I’m getting the following message after unsuccessfully trying to load Cyberrealistic in the Stable Diffusion checkpoint:
User friendly error message:
Error: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument index in method wrapper_CUDA__index_select). Please, check your schedules/ init values.
Loading weights [23017d7a76] from /content/stable-diffusion-webui/models/Stable-diffusion/cyberrealistic_v40.safetensors
changing setting sd_model_checkpoint to cyberrealistic_v40.safetensors: SafetensorError
Traceback (most recent call last):
File “/content/stable-diffusion-webui/modules/options.py”, line 140, in set
option.onchange()
File “/content/stable-diffusion-webui/modules/call_queue.py”, line 13, in f
res = func(*args, **kwargs)
File “/content/stable-diffusion-webui/modules/initialize_util.py”, line 170, in
shared.opts.onchange(“sd_model_checkpoint”, wrap_queued_call(lambda: sd_models.reload_model_weights()), call=False)
File “/content/stable-diffusion-webui/modules/sd_models.py”, line 741, in reload_model_weights
state_dict = get_checkpoint_state_dict(checkpoint_info, timer)
File “/content/stable-diffusion-webui/modules/sd_models.py”, line 315, in get_checkpoint_state_dict
res = read_state_dict(checkpoint_info.filename)
File “/content/stable-diffusion-webui/modules/sd_models.py”, line 291, in read_state_dict
pl_sd = safetensors.torch.load_file(checkpoint_file, device=device)
File “/usr/local/lib/python3.10/dist-packages/safetensors/torch.py”, line 259, in load_file
with safe_open(filename, framework=”pt”, device=device) as f:
safetensors_rust.SafetensorError: Error while deserializing header: MetadataIncompleteBuffer
Please advise, thank you!
1. After animatediff, have you deleted the venv folder and restart?
2. Have you used any memory optimization flag that may have moved the model to cpu?
Thanks so much for your reply!
1. I don’t see a venv folder, can you tell me where to find it please?
2. I don’t think so. I’m new to this so unless I accidentally did it, no. Is there any way for me to check?
Thanks again so much!!
Wanted to note I’m using AUTOMATIC1111 Web-UI
Thank u!
One more thing – regarding the “stable-diffusion-webui > extensions > sd-webui-animatediff > model” section, I’m not seeing “sd-webui-animatediff” folder under extensions. I’m only seeing “put extensions here.”
I believe I am using your Colab notebook, this one correct? “StableDiffusionUI_ngrok_sagiodev.ipynb”
Thanks!
Sorry for the multi posts, maybe someone also runs into this issue. It was fixed after I gave the Cyberrealistic model about 30 mins to finish uploading. It’s indicated in the Colab note by a small bar that completes in a circle, in the lower left hand corner.
The issue I’m running into now is – how can I pick up where I left off, when I open the note tomorrow? It seems as if I have to re-upload Cyberrealistic, as well as the SD_v15 model, every time. This takes about 30-40 minutes. If I select “save everything” in Drive, will I be able to pick up where I left off the day before? Or, can I save the Colab note?
Thanks again!
Don’t select save everything in the notebook. To save the model in your google drive, install the model using an url and check save a copy in google drive.
Ok last one (for this thread, until I get stumped again).
It all seems to be working now! Giving Cyber time to fully upload once (about 25-30 mins) and in sessions after, it uploads super fast. Seems to pick up where I left off. Hopefully this is helpful for someone. Feel free to delete if it’s annoying.
Thanks for all your work on this project! Excited to dive deeper.
Hi, venv folder is in stable-diffusion-webui > venv
thank you!!
Hey Andrew!
Tutorial sounds easy enough to follow but I’ve been having some trouble.
I installed AnimateDiff without issue (or at least it appears so), but when I’m trying to create the silver armored girl (or anything else) I just get a mishmash of colored artifacts, like some sort of mosaic.
Here’s what happen when I generate :
2023-11-16 14:55:08,503 – AnimateDiff – INFO – AnimateDiff process start.
2023-11-16 14:55:08,503 – AnimateDiff – INFO – Loading motion module mm_sd_v15_v2.ckpt from F:\Stable Diffusion\stable-diffusion-webui\extensions\sd-webui-animatediff\model\mm_sd_v15_v2.ckpt
2023-11-16 14:55:09,176 – AnimateDiff – INFO – Guessed mm_sd_v15_v2.ckpt architecture: MotionModuleType.AnimateDiffV2
2023-11-16 14:55:11,867 – AnimateDiff – WARNING – Missing keys
2023-11-16 14:55:12,717 – AnimateDiff – INFO – Injecting motion module mm_sd_v15_v2.ckpt into SD1.5 UNet middle block.
2023-11-16 14:55:12,718 – AnimateDiff – INFO – Injecting motion module mm_sd_v15_v2.ckpt into SD1.5 UNet input blocks.
2023-11-16 14:55:12,719 – AnimateDiff – INFO – Injecting motion module mm_sd_v15_v2.ckpt into SD1.5 UNet output blocks.
2023-11-16 14:55:12,719 – AnimateDiff – INFO – Setting DDIM alpha.
2023-11-16 14:55:12,723 – AnimateDiff – INFO – Injection finished.
2023-11-16 14:55:12,723 – AnimateDiff – INFO – Hacking loral to support motion lora
2023-11-16 14:55:12,723 – AnimateDiff – INFO – Hacking CFGDenoiser forward function.
2023-11-16 14:55:12,724 – AnimateDiff – INFO – Hacking ControlNet.
15%|████████████▍(and it goes to 100% without problem)
As you can see there doesn’t seem to be an issue. The only part that’s worrying me is the “WARNING – Missing keys” which kinda sounds problematic.
If you have any ideas I’d really appreciate the help!
I can’t see anything wrong either. I actually cannot get animatediff to work in my existing A1111. I have a fresh copy of A1111, animatediff and controlnet. It sometimes doesn’t play nice with other extensions. You can try that too.
How to update controlnet and a1111, please?
2023-11-13 22:02:38,909 – ControlNet – INFO – Loading model: control_sd15_depth [fef5e48e]0/20 [00:22<00:00, 1.13s/it]
2023-11-13 22:03:01,046 – ControlNet – INFO – Loaded state_dict from [D:\New Stable Diffusion\stable-diffusion-webui\extensions\sd-webui-controlnet\models\control_sd15_depth.pth]
2023-11-13 22:03:01,575 – ControlNet – INFO – controlnet_default_config
2023-11-13 22:03:05,792 – ControlNet – INFO – ControlNet model control_sd15_depth [fef5e48e] loaded.
*** Error running process: D:\New Stable Diffusion\stable-diffusion-webui\extensions\sd-webui-controlnet\scripts\controlnet.py
Traceback (most recent call last):
File "D:\New Stable Diffusion\stable-diffusion-webui\modules\scripts.py", line 619, in process
script.process(p, *script_args)
File "D:\New Stable Diffusion\stable-diffusion-webui\extensions\sd-webui-controlnet\scripts\controlnet.py", line 981, in process
self.controlnet_hack(p)
File "D:\New Stable Diffusion\stable-diffusion-webui\extensions\sd-webui-controlnet\scripts\controlnet.py", line 970, in controlnet_hack
self.controlnet_main_entry(p)
File "D:\New Stable Diffusion\stable-diffusion-webui\extensions\sd-webui-controlnet\scripts\controlnet.py", line 696, in controlnet_main_entry
input_image, image_from_a1111 = Script.choose_input_image(p, unit, idx)
File "D:\New Stable Diffusion\stable-diffusion-webui\extensions\sd-webui-controlnet\scripts\controlnet.py", line 608, in choose_input_image
raise ValueError('controlnet is enabled but no input image is given')
ValueError: controlnet is enabled but no input image is given
—
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [00:26<00:00, 1.34s/it]
Total progress: 100%|██████████████████████████████████████████████████████████████████| 20/20 [00:20<00:00, 1.04s/it]
Total progress: 100%|██████████████████████████████████████████████████████████████████| 20/20 [00:20<00:00, 1.03s/it]
How to solve that error?
I already updated A1111 and ControlNet and deleted venv folder.
After I generated, I got only an image, not video, why?
Somebody answer me please.
It said “ValueError: controlnet is enabled but no input image is given”. So controlnet is not getting the frame images. You can try a fresh installation of A111, animatediff and controlnet to see if the error is still there… (that’s what i use)
in a terminal or cmd, cd to A1111 and controlnet’s directory and run “git pull”. Delete the venv folder and start A1111.
Hi Andrew ,
DW_OPENPOSE is CPU only ?
During pose extraction I see the CPU activity at 90% and the GPU at 0% even with a 32 core Threadripper it can take 35 minutes for 300 frames. the generation is on the other hand faster on the 4090
There’s a way to enable gpu on dwpose. See https://github.com/Fannovel16/comfyui_controlnet_aux#qa
Hi Andrew, I followed your steps to the letter and getting this error
*** Error completing request
*** Arguments: (‘task(nz4au6pbx6i78te)’, ‘((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted’, ‘worst quality’, [], 20, ‘DPM++ 2M Karras’, 1, 1, 7, 512, 512, False, 0.7, 2, ‘Latent’, 0, 0, 0, ‘Use same checkpoint’, ‘Use same sampler’, ”, ”, [], , 0, False, ”, 0.8, -1, False, -1, 0, 0, 0, , , , , False, False, ‘positive’, ‘comma’, 0, False, False, ”, 1, ”, [], 0, ”, [], 0, ”, [], True, False, False, False, 0, False, None, None, False, None, None, False, None, None, False, 50) {}
Traceback (most recent call last):
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\modules\call_queue.py”, line 57, in f
res = list(func(*args, **kwargs))
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\modules\call_queue.py”, line 36, in f
res = func(*args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\modules\txt2img.py”, line 55, in txt2img
processed = processing.process_images(p)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\modules\processing.py”, line 732, in process_images
res = process_images_inner(p)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\extensions\sd-webui-animatediff\scripts\animatediff_cn.py”, line 118, in hacked_processing_process_images_hijack
return getattr(processing, ‘__controlnet_original_process_images_inner’)(p, *args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\modules\processing.py”, line 867, in process_images_inner
samples_ddim = p.sample(conditioning=p.c, unconditional_conditioning=p.uc, seeds=p.seeds, subseeds=p.subseeds, subseed_strength=p.subseed_strength, prompts=p.prompts)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\modules\processing.py”, line 1140, in sample
samples = self.sampler.sample(self, x, conditioning, unconditional_conditioning, image_conditioning=self.txt2img_image_conditioning(x))
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\modules\sd_samplers_kdiffusion.py”, line 235, in sample
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args=self.sampler_extra_args, disable=False, callback=self.callback_state, **extra_params_kwargs))
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\modules\sd_samplers_common.py”, line 261, in launch_sampling
return func()
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\modules\sd_samplers_kdiffusion.py”, line 235, in
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args=self.sampler_extra_args, disable=False, callback=self.callback_state, **extra_params_kwargs))
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\torch\utils\_contextlib.py”, line 115, in decorate_context
return func(*args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\repositories\k-diffusion\k_diffusion\sampling.py”, line 594, in sample_dpmpp_2m
denoised = model(x, sigmas[i] * s_in, **extra_args)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\extensions\sd-webui-animatediff\scripts\animatediff_infv2v.py”, line 250, in mm_cfg_forward
x_out = mm_sd_forward(self, x_in, sigma_in, cond_in, image_cond_in, make_condition_dict) # hook
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\extensions\sd-webui-animatediff\scripts\animatediff_infv2v.py”, line 160, in mm_sd_forward
out = self.inner_model(
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\repositories\k-diffusion\k_diffusion\external.py”, line 112, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\repositories\k-diffusion\k_diffusion\external.py”, line 138, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\modules\sd_hijack_utils.py”, line 17, in
setattr(resolved_obj, func_path[-1], lambda *args, **kwargs: self(*args, **kwargs))
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\modules\sd_hijack_utils.py”, line 28, in __call__
return self.__orig_func(*args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\models\diffusion\ddpm.py”, line 858, in apply_model
x_recon = self.model(x_noisy, t, **cond)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\models\diffusion\ddpm.py”, line 1335, in forward
out = self.diffusion_model(x, t, context=cc)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\modules\sd_unet.py”, line 91, in UNetModel_forward
return ldm.modules.diffusionmodules.openaimodel.copy_of_UNetModel_forward_for_webui(self, x, timesteps, context, *args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\diffusionmodules\openaimodel.py”, line 797, in forward
h = module(h, emb, context)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\repositories\stable-diffusion-stability-ai\ldm\modules\diffusionmodules\openaimodel.py”, line 86, in forward
x = layer(x)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\extensions\sd-webui-animatediff\motion_module.py”, line 107, in forward
return self.temporal_transformer(input_tensor, encoder_hidden_states, attention_mask)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\extensions\sd-webui-animatediff\motion_module.py”, line 173, in forward
hidden_states = block(hidden_states, encoder_hidden_states=encoder_hidden_states, video_length=video_length)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\extensions\sd-webui-animatediff\motion_module.py”, line 237, in forward
hidden_states = attention_block(
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\torch\nn\modules\module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\extensions\sd-webui-animatediff\motion_module.py”, line 596, in forward
hidden_states = self._memory_efficient_attention(query, key, value, attention_mask, optimizer_name)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\extensions\sd-webui-animatediff\motion_module.py”, line 494, in _memory_efficient_attention
hidden_states = xformers.ops.memory_efficient_attention(
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\xformers\ops\fmha\__init__.py”, line 192, in memory_efficient_attention
return _memory_efficient_attention(
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\xformers\ops\fmha\__init__.py”, line 290, in _memory_efficient_attention
return _memory_efficient_attention_forward(
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\xformers\ops\fmha\__init__.py”, line 310, in _memory_efficient_attention_forward
out, *_ = op.apply(inp, needs_gradient=False)
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\xformers\ops\fmha\cutlass.py”, line 175, in apply
out, lse, rng_seed, rng_offset = cls.OPERATOR(
File “C:\Automatic1111builds\SD16 AnimateDiff\stable-diffusion-webui\venv\lib\site-packages\torch\_ops.py”, line 502, in __call__
return self._op(*args, **kwargs or {})
RuntimeError: CUDA error: invalid configuration argument
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
I am using a fresh install of Automatic1111 and it has only Animatediff and ControlNet only. Can you please tell me how to fix this?
Thank You
HI Andrew,
i’ve follow the first part of tutorial but when the process is done i see only set of images are generated and not video, it is correct? Where should be the video? I made a check in the output folder but the video is not present. Thanks
I Andre when i click generate i have this error, can you help me?
0%| | 0/20 [00:01<?, ?it/s]
*** Error completing request
*** Arguments: ('task(na11rimj6slds3j)', '((best quality)), ((masterpiece)), ((realistic)), long highlighted hair, cybergirl, futuristic silver armor suit, confident stance, high-resolution, living room, smiling, head tilted', 'CyberRealistic_Negative-neg', [], 20, 'DPM++ 2M Karras', 1, 1, 7, 512, 512, False, 0.7, 2, 'Latent', 0, 0, 0, 'Use same checkpoint', 'Use same sampler', '', '', [], , 0, False, ”, 0.8, -1, False, -1, 0, 0, 0, False, False, False, False, ‘base’, , , , , None, False, ‘0’, ‘0’, ‘inswapper_128.onnx’, ‘CodeFormer’, 1, True, ‘None’, 1, 1, False, True, 1, 0, 0, False, 0.5, True, False, ‘CPU’, False, False, ‘positive’, ‘comma’, 0, False, False, ”, 1, ”, [], 0, ”, [], 0, ”, [], True, False, False, False, 0, False, None, None, False, None, None, False, None, None, False, 50) {}
Traceback (most recent call last):
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/call_queue.py”, line 57, in f
res = list(func(*args, **kwargs))
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/call_queue.py”, line 36, in f
res = func(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/txt2img.py”, line 55, in txt2img
processed = processing.process_images(p)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/processing.py”, line 732, in process_images
res = process_images_inner(p)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-animatediff/scripts/animatediff_cn.py”, line 118, in hacked_processing_process_images_hijack
return getattr(processing, ‘__controlnet_original_process_images_inner’)(p, *args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/processing.py”, line 867, in process_images_inner
samples_ddim = p.sample(conditioning=p.c, unconditional_conditioning=p.uc, seeds=p.seeds, subseeds=p.subseeds, subseed_strength=p.subseed_strength, prompts=p.prompts)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/hook.py”, line 451, in process_sample
return process.sample_before_CN_hack(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/processing.py”, line 1140, in sample
samples = self.sampler.sample(self, x, conditioning, unconditional_conditioning, image_conditioning=self.txt2img_image_conditioning(x))
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py”, line 235, in sample
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args=self.sampler_extra_args, disable=False, callback=self.callback_state, **extra_params_kwargs))
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/sd_samplers_common.py”, line 261, in launch_sampling
return func()
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py”, line 235, in
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args=self.sampler_extra_args, disable=False, callback=self.callback_state, **extra_params_kwargs))
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/utils/_contextlib.py”, line 115, in decorate_context
return func(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/repositories/k-diffusion/k_diffusion/sampling.py”, line 594, in sample_dpmpp_2m
denoised = model(x, sigmas[i] * s_in, **extra_args)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-animatediff/scripts/animatediff_infv2v.py”, line 250, in mm_cfg_forward
x_out = mm_sd_forward(self, x_in, sigma_in, cond_in, image_cond_in, make_condition_dict) # hook
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-animatediff/scripts/animatediff_infv2v.py”, line 160, in mm_sd_forward
out = self.inner_model(
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/repositories/k-diffusion/k_diffusion/external.py”, line 112, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/repositories/k-diffusion/k_diffusion/external.py”, line 138, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/sd_hijack_utils.py”, line 17, in
setattr(resolved_obj, func_path[-1], lambda *args, **kwargs: self(*args, **kwargs))
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/sd_hijack_utils.py”, line 28, in __call__
return self.__orig_func(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py”, line 858, in apply_model
x_recon = self.model(x_noisy, t, **cond)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py”, line 1335, in forward
out = self.diffusion_model(x, t, context=cc)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/hook.py”, line 858, in forward_webui
raise e
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/hook.py”, line 855, in forward_webui
return forward(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/hook.py”, line 592, in forward
control = param.control_model(x=x_in, hint=hint, timesteps=timesteps, context=context, y=y)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/cldm.py”, line 31, in forward
return self.control_model(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/cldm.py”, line 304, in forward
assert y.shape[0] == x.shape[0]
AttributeError: ‘NoneType’ object has no attribute ‘shape’
—
2023-11-07 12:26:57,671 – AnimateDiff – INFO – AnimateDiff process start.
2023-11-07 12:26:57,671 – AnimateDiff – INFO – Motion module already injected. Trying to restore.
2023-11-07 12:26:57,671 – AnimateDiff – INFO – Restoring DDIM alpha.
2023-11-07 12:26:57,672 – AnimateDiff – INFO – Removing motion module from SD1.5 UNet input blocks.
2023-11-07 12:26:57,672 – AnimateDiff – INFO – Removing motion module from SD1.5 UNet output blocks.
2023-11-07 12:26:57,672 – AnimateDiff – INFO – Removing motion module from SD1.5 UNet middle block.
2023-11-07 12:26:57,673 – AnimateDiff – INFO – Removal finished.
2023-11-07 12:26:57,685 – AnimateDiff – INFO – Injecting motion module mm_sd_v15_v2.ckpt into SD1.5 UNet middle block.
2023-11-07 12:26:57,685 – AnimateDiff – INFO – Injecting motion module mm_sd_v15_v2.ckpt into SD1.5 UNet input blocks.
2023-11-07 12:26:57,685 – AnimateDiff – INFO – Injecting motion module mm_sd_v15_v2.ckpt into SD1.5 UNet output blocks.
2023-11-07 12:26:57,685 – AnimateDiff – INFO – Setting DDIM alpha.
2023-11-07 12:26:57,689 – AnimateDiff – INFO – Injection finished.
2023-11-07 12:26:57,689 – AnimateDiff – INFO – AnimateDiff LoRA already hacked
2023-11-07 12:26:57,689 – AnimateDiff – INFO – CFGDenoiser already hacked
2023-11-07 12:26:57,689 – AnimateDiff – INFO – Hacking ControlNet.
2023-11-07 12:26:57,689 – AnimateDiff – INFO – BatchHijack already hacked.
2023-11-07 12:26:57,689 – AnimateDiff – INFO – ControlNet Main Entry already hacked.
2023-11-07 12:26:59,069 – ControlNet – INFO – Loading model from cache: thibaud_xl_openpose [c7b9cadd]
2023-11-07 12:27:00,349 – ControlNet – INFO – Loading preprocessor: dw_openpose_full
2023-11-07 12:27:00,349 – ControlNet – INFO – preprocessor resolution = 512
2023-11-07 12:28:19,664 – ControlNet – INFO – ControlNet Hooked – Time = 80.6015408039093
0%| | 0/20 [00:01<?, ?it/s]
*** Error completing request
*** Arguments: ('task(fxol1tlqqvedbh4)', 'a portrait of a beautiful woman, topless, , (light freckles, beauty spots:1.2), she has long (dirty blonde:1.2) wavy hair, she is wearing a beige sunhat background of the ocean, sunset, sun-kissed, sunflare', 'CyberRealistic_Negative-neg', [], 20, 'DPM++ 2M Karras', 1, 1, 7, 512, 512, False, 0.7, 2, 'Latent', 0, 0, 0, 'Use same checkpoint', 'Use same sampler', '', '', [], , 0, False, ”, 0.8, -1, False, -1, 0, 0, 0, False, False, False, False, ‘base’, , , , , None, False, ‘0’, ‘0’, ‘inswapper_128.onnx’, ‘CodeFormer’, 1, True, ‘None’, 1, 1, False, True, 1, 0, 0, False, 0.5, True, False, ‘CPU’, False, False, ‘positive’, ‘comma’, 0, False, False, ”, 1, ”, [], 0, ”, [], 0, ”, [], True, False, False, False, 0, False, None, None, False, None, None, False, None, None, False, 50) {}
Traceback (most recent call last):
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/call_queue.py”, line 57, in f
res = list(func(*args, **kwargs))
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/call_queue.py”, line 36, in f
res = func(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/txt2img.py”, line 55, in txt2img
processed = processing.process_images(p)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/processing.py”, line 732, in process_images
res = process_images_inner(p)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-animatediff/scripts/animatediff_cn.py”, line 118, in hacked_processing_process_images_hijack
return getattr(processing, ‘__controlnet_original_process_images_inner’)(p, *args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/processing.py”, line 867, in process_images_inner
samples_ddim = p.sample(conditioning=p.c, unconditional_conditioning=p.uc, seeds=p.seeds, subseeds=p.subseeds, subseed_strength=p.subseed_strength, prompts=p.prompts)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/hook.py”, line 451, in process_sample
return process.sample_before_CN_hack(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/processing.py”, line 1140, in sample
samples = self.sampler.sample(self, x, conditioning, unconditional_conditioning, image_conditioning=self.txt2img_image_conditioning(x))
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py”, line 235, in sample
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args=self.sampler_extra_args, disable=False, callback=self.callback_state, **extra_params_kwargs))
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/sd_samplers_common.py”, line 261, in launch_sampling
return func()
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/sd_samplers_kdiffusion.py”, line 235, in
samples = self.launch_sampling(steps, lambda: self.func(self.model_wrap_cfg, x, extra_args=self.sampler_extra_args, disable=False, callback=self.callback_state, **extra_params_kwargs))
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/utils/_contextlib.py”, line 115, in decorate_context
return func(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/repositories/k-diffusion/k_diffusion/sampling.py”, line 594, in sample_dpmpp_2m
denoised = model(x, sigmas[i] * s_in, **extra_args)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-animatediff/scripts/animatediff_infv2v.py”, line 250, in mm_cfg_forward
x_out = mm_sd_forward(self, x_in, sigma_in, cond_in, image_cond_in, make_condition_dict) # hook
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-animatediff/scripts/animatediff_infv2v.py”, line 160, in mm_sd_forward
out = self.inner_model(
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/repositories/k-diffusion/k_diffusion/external.py”, line 112, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/repositories/k-diffusion/k_diffusion/external.py”, line 138, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/sd_hijack_utils.py”, line 17, in
setattr(resolved_obj, func_path[-1], lambda *args, **kwargs: self(*args, **kwargs))
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/modules/sd_hijack_utils.py”, line 28, in __call__
return self.__orig_func(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py”, line 858, in apply_model
x_recon = self.model(x_noisy, t, **cond)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/repositories/stable-diffusion-stability-ai/ldm/models/diffusion/ddpm.py”, line 1335, in forward
out = self.diffusion_model(x, t, context=cc)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/hook.py”, line 858, in forward_webui
raise e
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/hook.py”, line 855, in forward_webui
return forward(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/hook.py”, line 592, in forward
control = param.control_model(x=x_in, hint=hint, timesteps=timesteps, context=context, y=y)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/cldm.py”, line 31, in forward
return self.control_model(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/venv/lib/python3.10/site-packages/torch/nn/modules/module.py”, line 1501, in _call_impl
return forward_call(*args, **kwargs)
File “/Users/sgiancristofaro/Documents/AI/stable-diffusion-webui/stable-diffusion-webui/extensions/sd-webui-controlnet/scripts/cldm.py”, line 304, in forward
assert y.shape[0] == x.shape[0]
AttributeError: ‘NoneType’ object has no attribute ‘shape’
it looks like you are processing an image or a video but you didn’t upload any? This could be an input video or controlnet image.
If that’s not what you are doing, try updating A1111 and animatediff.
if that still not work, start a new A1111 installation and install only animatediff and controlnet. That’s what i have.
no i downloaded the tutorial’s video and i uploaded on the stable diffusion
I’ve followed your instructions to generate the 3-second cosplay video and got the following error: “RuntimeError: The size of tensor a (45) must match the size of tensor b (32) at non-singleton dimension 1.” Can you help me fix or go around this error?
Things you can try:
1. You WebUI, Stable Diffusion and AnimateDiff may need updates. Update them to the latest version. Delete the venv folder. Start WebUI.
2. You have incompatible extensions installed (Like on my setup). I ended having a webui installation just with animatediff and controlnet.
3. You may have selected a controlnet model incompatible with your checkpoint model. E.g. Use v1.5 controlnets for v1.5 models, e.g.
Hi,
Thanks for your tutorial 😉
i have install the plugin today but I don’t have the same settings like your screenshot:
[img]https://i.imgur.com/fjmUaAA.png[/img]
Do you know what is N, R-P, R+P, A in the Closed loop options?
Because when i try an animation the scene and character change during the animation. i don’t know if it’s possible to keep the same character.
Great days!
They added this option recently. See the doc https://github.com/continue-revolution/sd-webui-animatediff#webui-parameters
Thanks I will check 😉
I’ve followed your instruction to generate the 3-second cosplay video, only to get the following error: RuntimeError: The size of tensor a (45) must match the size of tensor b (32) at non-singleton dimension 1
What shall I do to fix this error?
Hi, when I generate I only get still images. Where do the video output to? I followed your exact settings but can’t find the videos anywhere.
It is supposed to a video on the GUI. Check the terminal console for error messages.
Hello, I installed the folder and can see it on my installed extensions page, but animatediff doesn’t show up. What could be wrong?
It should be on txt2img page. any error message?
I had this problem initially when I installed AnimateDiff tonight, but then it occurred to me that I just hadn’t updated Automatic1111 in a long time. Here’s the link to Andrew’s updating instructions, in case anyone else encounters this problem: https://stable-diffusion-art.com/install-windows/#Updating_as_needed
Hey , I did my first test based on the tutorial steps you described, did step #2 & #3 as is,model realistic vision 5.1, the result was pretty good but all my tests finished with 4 sec video divided to two different movies , the topic is the same but two different persons , two different backgrounds etc, why is that? why I am missing, I want 4 sec single clip and not two clips of 2 sec
Hi, follow Geert’s suggestion in the comment
https://stable-diffusion-art.com/animatediff/#comment-3434
RuntimeError: CUDA error: device-side assert triggered
提示:Python 运行时抛出了一个异常。请检查疑难解答页面。
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
You should report this error on their github page. You can try
--opt-sdp-no-mem-attentionoption instead of xformers.my solution is installing animatediff v1.3. it warks
Thanks for your reply ! I’ve rolled back animatediff to v1.13.1 from the github: https://github.com/continue-revolution/sd-webui-animatediff/releases/tag/v1.13.1
And works now !
Hate to comment for troubleshooting but follwing the guide I’m getting:
*** Error running before_process: E:\AI\Image\A1111 WebUI\stable-diffusion-webui\extensions\sd-webui-animatediff\scripts\animatediff.py
Traceback (most recent call last):
File “E:\AI\Image\A1111 WebUI\stable-diffusion-webui\modules\scripts.py”, line 611, in before_process
script.before_process(p, *script_args)
File “E:\AI\Image\A1111 WebUI\stable-diffusion-webui\extensions\sd-webui-animatediff\scripts\animatediff.py”, line 56, in before_process
self.cn_hacker.hack(params)
File “E:\AI\Image\A1111 WebUI\stable-diffusion-webui\extensions\sd-webui-animatediff\scripts\animatediff_cn.py”, line 611, in hack
self.hack_cn()
File “E:\AI\Image\A1111 WebUI\stable-diffusion-webui\extensions\sd-webui-animatediff\scripts\animatediff_cn.py”, line 136, in hack_cn
from scripts.controlmodel_ipadapter import (PlugableIPAdapter,
ModuleNotFoundError: No module named ‘scripts.controlmodel_ipadapter’
Actually, oddly it seems that this doesn’t matter. My it/s are just ??? which led me to believe it was stalled, but leaving it to sit it does do it, just very slowly. Around 10% it shows the progress.
Can not find panel: Step 3: Enter AnimateDiff settings. Tried installing on 2 different Automatic1111 versions. How do I get to it?
It should be on the txt2img page. Scroll down to see.
Thank you for this tutorial, Andrew.
When I tried to use ControlNet, it says “AssertionError: No input images found for ControlNet module”. DWPose with Openpose model selected. Video is uploaded of course. I think the input is provided by the video frames. What did I miss? Please help.
This should work. Try updating controlnet/A1111 and delete venv folder.
Thank you for your reply, Andrew.
I simply clicked the Generate button again and it works.
hello i got this error : ValueError: controlnet is enabled but no input image is given
controlnet / A1111 is update and checkbox “Allow other script to control this extension”.
But stuck on this error, i dont understand.
i saw similar error on this thread : https://github.com/Mikubill/sd-webui-controlnet/issues/677
But i cannot see this options in my controlnet 1.1.411
if you have one idee thx ! 🙂
I did a clean install it works again but very strange
I actually couldn’t get animatediff to work on my existing setup. I have an a1111 installation just for animatediff with controlnet. Trying that could be far easier to troubleshoot!
Half way through every animation, it changes the image completely. I get two different girls in two different contexts looping back to back.
Also, the camera movement LORAs leave Shutterst*ck watermarks unless you turn them down to 0.85 or less. But then the motion is reduced and less natural.
I guess you mentioned that bit about reducing the impact of the LORAs. I missed it the first time.
Some prompts just doesn’t work and cause animation to switch. I think the problem is less with the mm1.5 v2 model, but it could still happen.
Prompt may be too long, go to automatic1111 settings -> optimisations and enable :
Pad prompt/negative prompt to be same length
This was the main problem for me. As soon as I enabled this, everything started working correctly
This is a great tutorial and explains the various settings in a clear way. Thanks!
🙂
No luck in Automatic1111 / Colab:
*** Error running postprocess: /content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-animatediff/scripts/animatediff.py
Traceback (most recent call last):
File “/content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/scripts.py”, line 651, in postprocess
script.postprocess(p, processed, *script_args)
File “/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-animatediff/scripts/animatediff.py”, line 76, in postprocess
AnimateDiffOutput().output(p, res, params)
File “/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-animatediff/scripts/animatediff_output.py”, line 35, in output
video_paths += self._save(params, video_list, video_path_prefix, res, i)
File “/content/gdrive/MyDrive/sd/stable-diffusion-webui/extensions/sd-webui-animatediff/scripts/animatediff_output.py”, line 146, in _save
imageio.imwrite(
File “/usr/local/lib/python3.10/dist-packages/imageio/v3.py”, line 139, in imwrite
with imopen(
File “/usr/local/lib/python3.10/dist-packages/imageio/core/imopen.py”, line 156, in imopen
raise err_type(err_msg) from err_from
ImportError: The `pyav` plugin is not installed. Use `pip install imageio[pyav]` to install it.
No GIF, no Mp4 is created.
It says the error right there –
The `pyav` plugin is not installed. Use `pip install imageio[pyav]` to install it.
I’d suggest using a local machine to run SD if you can get the GPUs, a GTX 1070 should be enough for this task.
Collab is difficult, any cloud resource generally will be, especially with a python framework
Hi, I cannot reproduce the error. Both gif and mp3 work. I see you save your SD in google drive. This is not recommended and is known to cause issues. Save only small models so that it reinstalls every time. It is also faster.
Thank you so much for this tutorial, it was a great help. I saw this
https://civitai.com/images/2815665?period=AllTime&sort=Newest&view=categories&modelVersionId=176425&modelId=43331&postId=660538
in Civitai and I am very impressed with how they made it. Coz animation seems so so smooth.
Do you think they are using AnimateDiff too? If I’m not mistaken, AnimatedDiff supports 512×512, but I’m not sure how to upscale.
Yes, it is animatediff with close loop. It saves the png file of each frame. You can do a batch upscale and put it back as a video.