
LCM-LoRA can speed up any Stable Diffusion models. It can be used with the Stable Diffusion XL model to generate a 1024×1024 image in as few as 4 steps.
In this article, you will learn/get:
- What LCM LoRA is.
- How does LCM LoRA work?
- Using LCM-LoRA in AUTOMATIC1111
- A downloadable ComfyUI LCM-LoRA workflow for speedy SDXL image generation (txt2img)
- A downloadable ComfyUI LCM-LoRA workflow for fast video generation (AnimateDiff)

Table of Contents
What is LCM-LoRA?
To answer this question, we have to start with the related Consistency Model (CM). CM is a new class of diffusion models trained to generate images in a single step. It was proposed by Yang Song and coworkers in the article Consistency Models.
The Latent Consistency Model (LCM) applies the same idea in latent diffusion models, such as Stable Diffusion, where the image denoising happens in the latent space.
Normally, you would need to train a new LCM for each custom checkpoint model, making it inconvenient to use. LCM-LoRA is an LoRA model trained with Stable Diffusion base models (v1.5 and SDXL) using the consistency method. It can be used with ANY custom checkpoint model to speed up the image generation to as few as four steps.
How does LCM-LoRA work?
To understand how LCM-LoRA works, you will first need to first understand the consistency model and the related efforts to speed up diffusion models.
Consistency models
A consistency model is a diffusion model trained to produce an AI image in a single step. It is a more efficient student model trained with a teacher model, such as the SDXL model. The student model is trained to produce the same image as the teacher model but in a single step. In other words, the consistency model is a faster version of the teacher model.
You can also train a consistency model directly from scratch without using a teacher model. In the future, you may see a new LCM models without a standard counterpart.
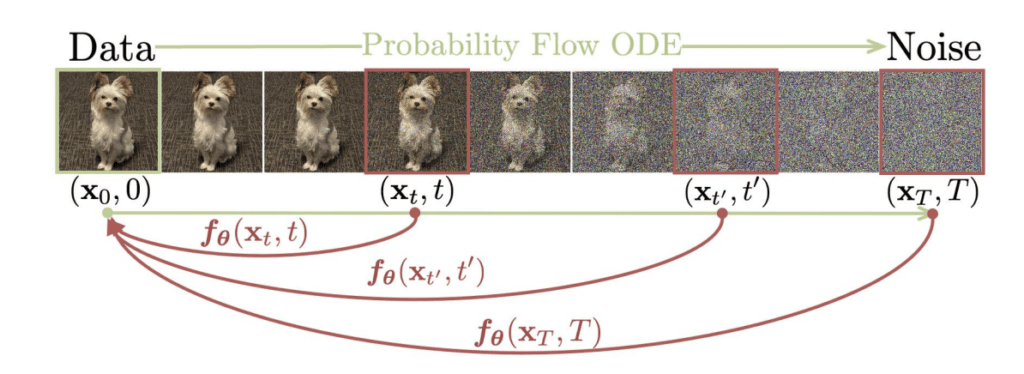
The idea behind the consistency model is to find a mapping between the final AI image and any denoising step. For example, if a diffusion model is trained to produce an AI image in 50 steps, a consistency model maps the intermediate noisy images at steps 0, 1, 2, 3… to the final step 50.
It is called a consistency model because the training takes advantage of the output of the mapping being consistent: It is always mapped to the final image in a single step. In other words, the mapping function’s outputs are always the same, no matter how noisy the image is.
In practice, the image quality of a single-step generation is not good. So people usually do a few steps instead.
The consistency model is a distillation method: It extracts and rearranges information from an existing (teacher) model to make it more efficient.
The consistency models are better than the progressive distillation method that promised to speed up Stable Diffusion dramatically. They produce higher-quality images.
Latent consistency model (LCM)
The Latent consistency model (LCM) is the consistency model with latent diffusion, such as in Stable Diffusion. It was studied by Simian Luo and coworkers in the article Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference. The original consistency model is in the pixel space and the LCM is in the latent space. This is the only difference.
LCM-LoRA
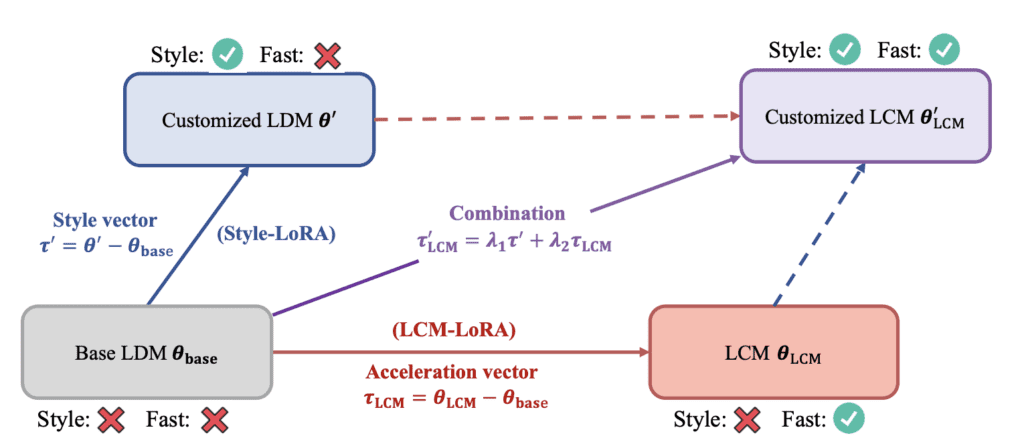
Now, we are finally in the position to introduce LCM-LoRA! Instead of training a checkpoint model, you train a LoRA for an LCM. LoRA is a small model file designed to modify a checkpoint model. It’s like a small patch.
The benefit of using LoRA is:
- Portability: an LCM-LoRA can be applied to ANY Stable Diffusion checkpoint models. LCM-LoRA for Stable Diffusion v1.5 and SDXL models are available. Essentially, you speed up a model when you apply the LoRA.
- Faster training: LoRA has a smaller number of weights to train. So it is faster and less demanding to train one.
Sampling method for LCM-LoRA
The LCM model is trained to do 1-step inference. In other words, the model will try to produce the final AI image in one step. But the quality is not as good as we hoped.
So here’s the sampling method for LCM:
- Denoise the latent image.
- Add back some noise (according to the noise schedule)
- Repeat steps 1 and 2 until reaching the last sampling step.
LCM-LoRA download pages
Here are the Huggingface links to the LCM-LoRA weights.
Using LCM-LoRA in AUTOMATIC1111
AUTOMATIC1111 does not have official support for LCM-LoRA yet. But you can use the LCM-LoRA speed up in a limited way.
Stable Diffusion v1.5 models
First, download the LCM-LoRA for SD 1.5 and put it to the LoRA folder stable-diffusion-webui > models > Lora. Rename it to lcm_lora_sd15.safetensors.
Select a Stable Diffuions v1.5 model, e.g. the DreamShaper model.
Use the LoRA directive in the prompt:
a very cool car <lora:lcm_lora_sd15:1>
Sampler: Euler.
You need to use a low CFG scale: 1 – 2
Sampling steps: 4

For comparison, these images are without using the LCM-LoRA using 4 steps.

Stable Diffusion XL
As of Nov 24, 2023, native support of LCM-LoRA in AUTOMATIC1111 is lacking. You can use the method above, but the results are not as good as the v1.5 models.
Adding the LCM sampler with AnimateDiff extension
The SDXL model doesn’t work well because we should have used the LCM sampling method. Before the LCM sampler is added, you can install the AnimateDiff extension. Update it if you have it already. It adds the LCM sampler to the list of available sampling methods.
Download the LCM LoRA for SDXL. Put it in stable-diffusion-webui > models> Lora. Rename it to lcm_lora_sdxl.safetensors.
To generate SDXL images using the LCM sampler:
- Checkpoint model: sd_xl_base_1.0
- Prompt:
a very cool car <lora:lcm_lora_sdxl:1>
- Sampling method: LCM
- Size: 1024 x 1024
- CFG Scale: 1 to 2
- Sampling steps: 4

ComfyUI LCM-LoRA SDXL text-to-image workflow
We will use ComfyUI, a node-based Stable Diffusion GUI. You can use ComfyUI on Window/Mac or Google Colab.
Check out Think Diffusion for a fully managed ComfyUI/A1111/Forge online service. They offer 20% extra credits to our readers. (and a small commission to support this site if you sign up)
See the beginner’s guide for ComfyUI if you haven’t used it.
Step 1: Load the workflow
Download the ComfyUI workflow JSON file, then drag and drop it to ComfyUI to load the workflow.
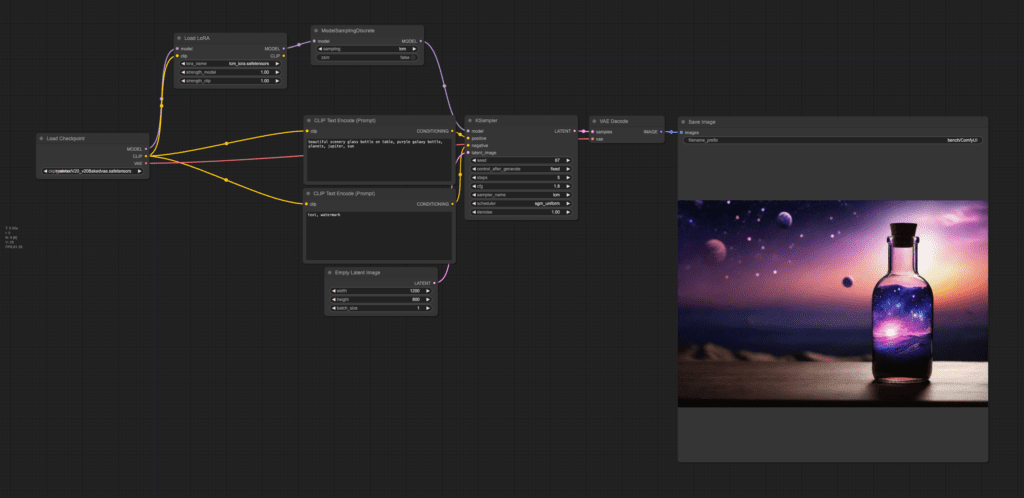
Step 2: Load a SDXL model
In the Load Checkpoint node, select an SDXL model in the dropdown menu. It can be the SDXL base or any custom SDXL model.
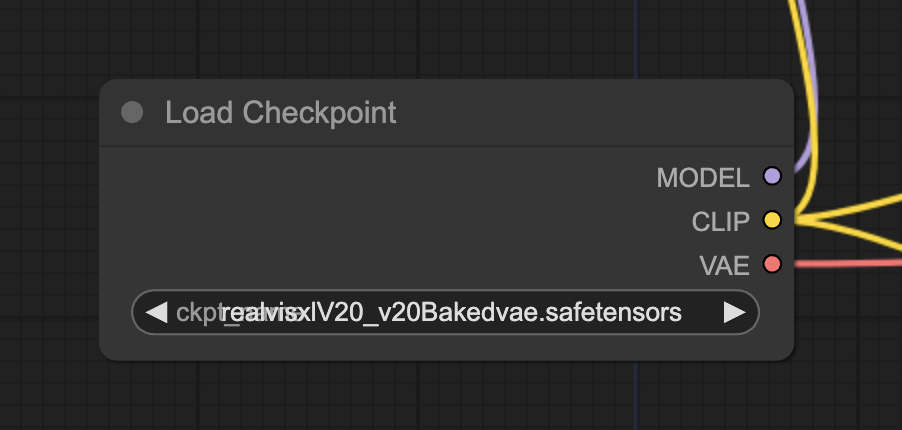
Step 3: Download and load the LoRA
Download the LCM-LoRA for SDXL models here.
Rename the file to lcm_lora_sdxl.safetensors. Put it in the folder ComfyUI > models > loras. (Put it in A1111’s LoRA folder if your ComfyUI shares model files with A1111)
Refresh the ComfyUI page.
Select the LCM-LoRA in the load LoRA node.
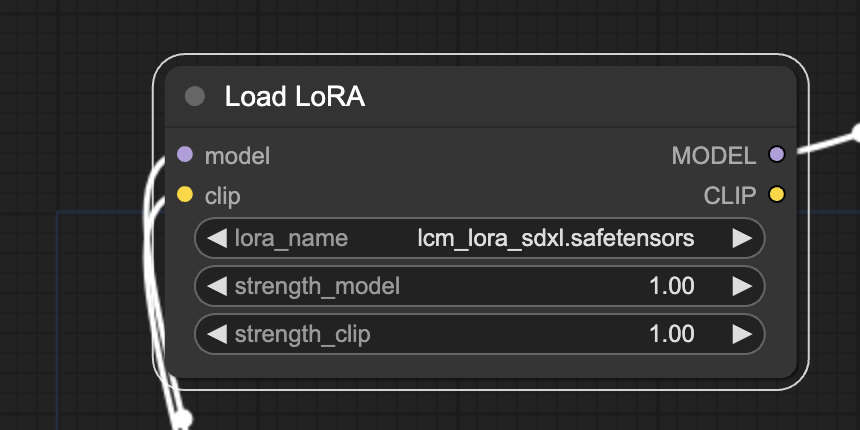
Step 4: Generate images
Review the prompt, the negative prompt, and the image size. Press Queue Prompt to generate an image. It should appear in no time because this workflow only uses 5 sampling steps!
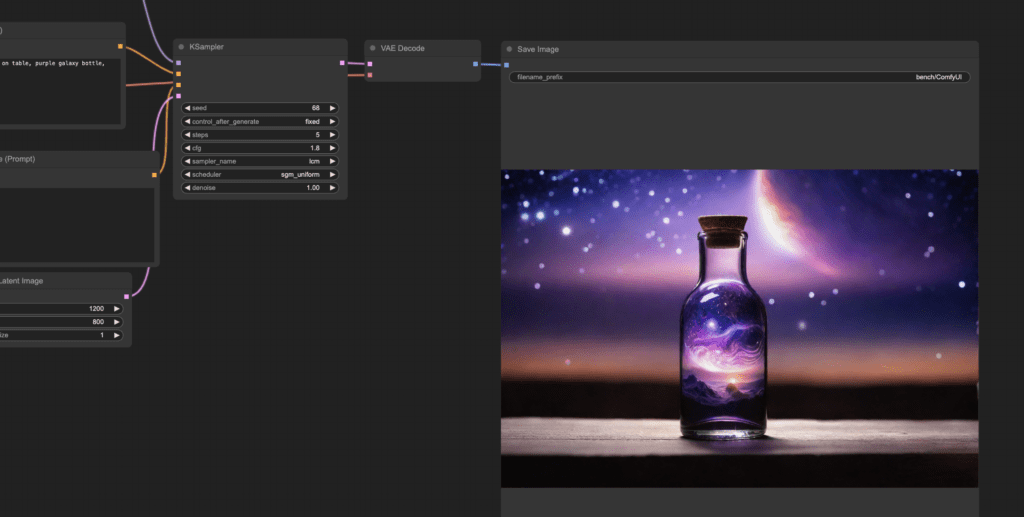
Remarks
You can use the same workflow with Stable Diffusion v1.5 custom models. You need to use a v1.5 model and v1.5 LCM-LoRA. Don’t forget to change the image size to 768 x 512 pixels!
ComfyUI LCM-LoRA animateDiff prompt travel workflow
What comfyUI workflows can use some speed up? Of course it’s making videos! So here you go: A ComfyUI AnimateDiff prompt travel workflow sped up by LCM-LoRA!
Step 1: Load the workflow
Download the workflow JSON file. Drag and drop the workflow file to ComfyUI to load it.
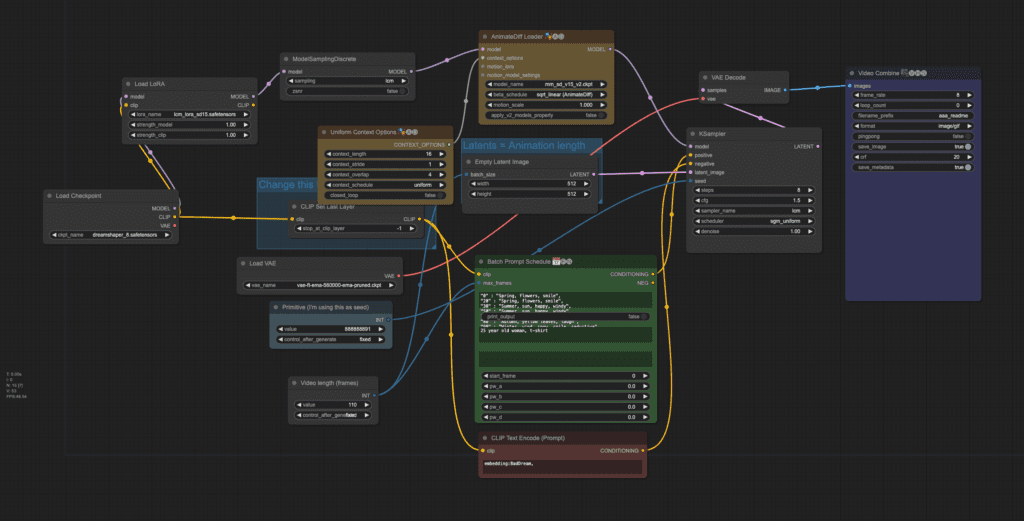
You may need to update ComfyUI, install missing custom nodes and update all the custom nodes.
Step 2: Select a checkpoint model
Download the checkpoint model DreamShaper 8. Put the safetensors file in the folder ComfyUI > models > checkpoints.
Refresh the browser tab.
Find the node Load Checkpoint. Click the ckpt_name dropdown menu and select the dreamshaper_8 model.
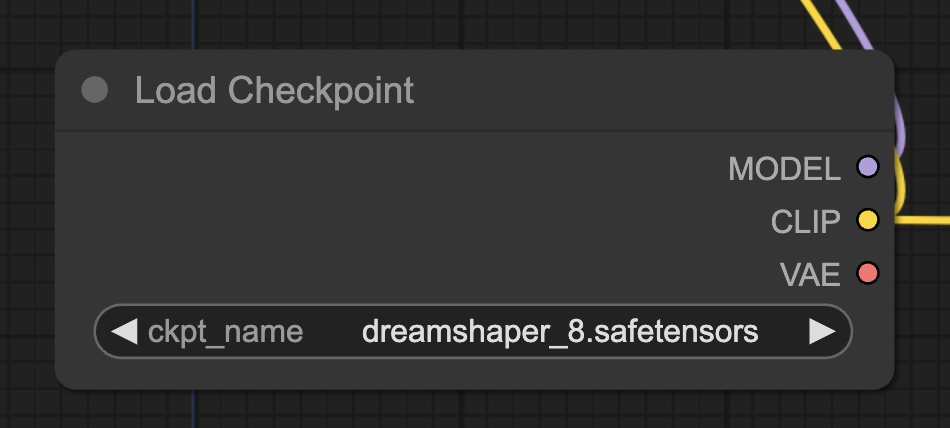
Step 3: Select a VAE
Download the ema-560000 VAE. Put the file in the folder ComfyUI > models > vae.
Refresh the browser page.
In the Load VAE node, select the file you just downloaded.

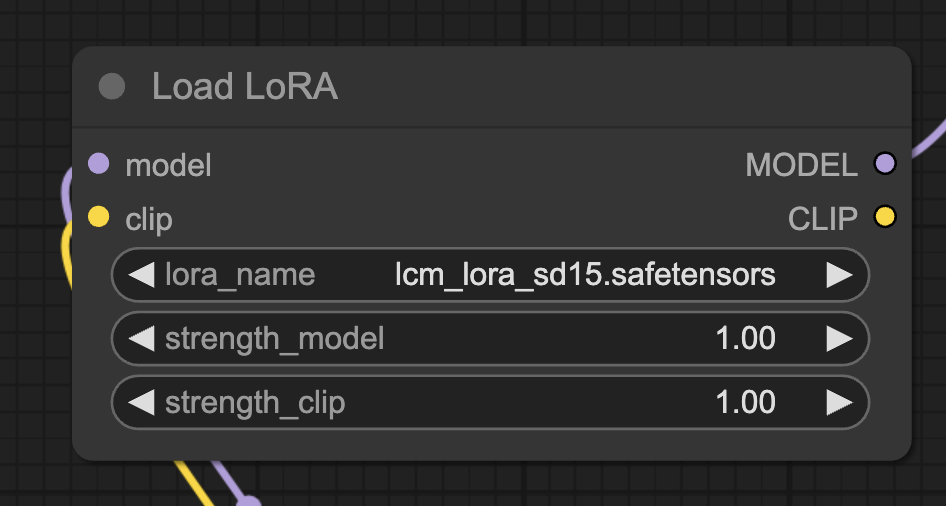
Step 4: Select the LCM-LoRA
Download the SD v1.5 LCM-LoRA. Rename it to lcm_lora_sd15.safetensors.
Put it in ComfyUI > models > loras.
Refresh ComfyUI.
Select lcm_lora_sd15.safetensors in the Load LoRA node.
Step 5: Select the AnimateDiff motion module
Download the AnimateDiff v1.5 v2 motion model. Put it in the folder ComfyUI > custom_nodes > ComfyUI-AnimateDiff-Evolved > models.
Refresh the browser page.
In the AnimateDiff Loader node, Select mm_sd_v15_v2.ckpt in the model_name dropdown menu.
Step 6: Download the negative embedding
This workflow uses the BadDream negative embedding in the negative prompt. It is a negative embedding trained for the Dream Shaper model.
Download the BadDream embedding. Put the file in ComfyUI > models > embeddings.
Step 7: Generate the video
Click Queue Prompt to start generating a video.
The progress bar will appear at the KSampler node. When it is done, you will see the video appearing in the Video Combine node.
This is what you should get:
Readings
Consistency Models – Yang Song and coworkers (2023) – This paper describes the Consistency Model for diffusion models.
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference – Simian Luo and coworkers (2023) – Applying the Consistency Model to latent diffusion models.
LCM-LoRA: A Universal Stable-Diffusion Acceleration Module – Simian Luo and coworkers (2023) – Training a LoRA for LCM.
Great tips on speed! Makes me wonder about advanced ai girl generator | GPTProto workflows.
I’m a bit late to the party but i don’t understand where the girl comes from.
There’s no prompt for the girl, theres no image, so how come it creates her
Hi Andrew I don’t think you saw my reply:
There are 2 green download buttons. The first one in the section “text-to-image” is indeed pointing to a json file but the second one in section “animateDiff prompt travel” is pointing to a png, and that’s the one I’m referring to. That’d be great to have that one working too, thanks !
I saw your message, just haven’t get a chance to work on it. You can now download the json file.
Great thanks for fixing it Andrew !! Sorry for being pushy 🙂 cheers !
You said The server may have “optimized” the png file by striping its meta data. I updated the file to json.
But when I click download it’s a webp with no metadata, so I right click save link as, and get a png, but Comfy says there’s no metadata in it.
Did you put the json file somewhere it can be downloaded ? thanks !
Yes, you should see the green download buttons to download the json files. Don’t use the pngs.
I think I know where the confusion lies 🙂 there are 2 green download buttons.
The first one in the section “ComfyUI LCM-LoRA SDXL text-to-image workflow” is indeed pointing to a json file
but the second one in the section “ComfyUI LCM-LoRA animateDiff prompt travel workflow” is pointing to an image, and that’s the one I’m refering to. That’s be great to have that one working too, thanks !
Hi again,
like other people I can’t load the png, comfy stays empty, updated to last version, no missing custom nodes
Hi Andrew ! thanks for all these great tutorials !
the ema-560000 VAE link actually points to another file, orangemix VAE, it’s 900Mb instead of 384 for the ema560000
Good catch! corrected.
hi its my error dear.
mixed dtype (CPU): expect parameter to have scalar type of Float
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\execution.py”, line 151, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\execution.py”, line 81, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\execution.py”, line 74, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\nodes.py”, line 1344, in sample
return common_ksampler(model, seed, steps, cfg, sampler_name, scheduler, positive, negative, latent_image, denoise=denoise)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\nodes.py”, line 1314, in common_ksampler
samples = comfy.sample.sample(model, noise, steps, cfg, sampler_name, scheduler, positive, negative, latent_image,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py”, line 419, in motion_sample
latents = orig_comfy_sample(model, noise, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-Advanced-ControlNet\adv_control\control_reference.py”, line 47, in refcn_sample
return orig_comfy_sample(model, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\comfy\sample.py”, line 37, in sample
samples = sampler.sample(noise, positive, negative, cfg=cfg, latent_image=latent_image, start_step=start_step, last_step=last_step, force_full_denoise=force_full_denoise, denoise_mask=noise_mask, sigmas=sigmas, callback=callback, disable_pbar=disable_pbar, seed=seed)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py”, line 761, in sample
return sample(self.model, noise, positive, negative, cfg, self.device, sampler, sigmas, self.model_options, latent_image=latent_image, denoise_mask=denoise_mask, callback=callback, disable_pbar=disable_pbar, seed=seed)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py”, line 663, in sample
return cfg_guider.sample(noise, latent_image, sampler, sigmas, denoise_mask, callback, disable_pbar, seed)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py”, line 650, in sample
output = self.inner_sample(noise, latent_image, device, sampler, sigmas, denoise_mask, callback, disable_pbar, seed)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py”, line 629, in inner_sample
samples = sampler.sample(self, sigmas, extra_args, callback, noise, latent_image, denoise_mask, disable_pbar)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py”, line 534, in sample
samples = self.sampler_function(model_k, noise, sigmas, extra_args=extra_args, callback=k_callback, disable=disable_pbar, **self.extra_options)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\utils\_contextlib.py”, line 115, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\sampling.py”, line 762, in sample_lcm
denoised = model(x, sigmas[i] * s_in, **extra_args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py”, line 272, in __call__
out = self.inner_model(x, sigma, model_options=model_options, seed=seed)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py”, line 616, in __call__
return self.predict_noise(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py”, line 619, in predict_noise
return sampling_function(self.inner_model, x, timestep, self.conds.get(“negative”, None), self.conds.get(“positive”, None), self.cfg, model_options=model_options, seed=seed)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py”, line 456, in evolved_sampling_function
cond_pred, uncond_pred = sliding_calc_conds_batch(model, [cond, uncond_], x, timestep, model_options)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py”, line 593, in sliding_calc_conds_batch
sub_conds_out = calc_cond_uncond_batch_wrapper(model, sub_conds, sub_x, sub_timestep, model_options)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py”, line 653, in calc_cond_uncond_batch_wrapper
return comfy.samplers.calc_cond_batch(model, conds, x_in, timestep, model_options)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py”, line 218, in calc_cond_batch
output = model.apply_model(input_x, timestep_, **c).chunk(batch_chunks)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\comfy\model_base.py”, line 97, in apply_model
model_output = self.diffusion_model(xc, t, context=context, control=control, transformer_options=transformer_options, **extra_conds).float()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py”, line 1511, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py”, line 1520, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\comfy\ldm\modules\diffusionmodules\openaimodel.py”, line 850, in forward
h = forward_timestep_embed(module, h, emb, context, transformer_options, time_context=time_context, num_video_frames=num_video_frames, image_only_indicator=image_only_indicator)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py”, line 132, in forward_timestep_embed
x = layer(x, context)
^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py”, line 1511, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py”, line 1520, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\motion_module_ad.py”, line 673, in forward
return self.temporal_transformer(input_tensor, encoder_hidden_states, attention_mask, self.view_options, mm_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py”, line 1511, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py”, line 1520, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\motion_module_ad.py”, line 882, in forward
hidden_states = self.norm(hidden_states).to(hidden_states.dtype)
^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py”, line 1511, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py”, line 1520, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\comfy\ops.py”, line 94, in forward
return super().forward(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py”, line 171, in groupnorm_mm_forward
input = group_norm(input, self.num_groups, weight, bias, self.eps)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\pars\Desktop\stabel\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\functional.py”, line 2561, in group_norm
return torch.group_norm(input, num_groups, weight, bias, eps, torch.backends.cudnn.enabled)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Hey Andrew, something is weird with the image files. Previously on another computer I had downloaded the png files and these were drag and drop working on comfy.
Now it looks like the png have lost the workflow metadata? i dont see it with a metadata viewer on the png. Weirdly sometimes, I’m getting a webp file when I save instead of a png! Can you check the png files or wharever the host is for them?
You can check the downloaded pngs from here using this online tool:
https://www.nayuki.io/page/png-file-chunk-inspector
All of my comfyui generated images I tried there show the prompt and workflow chunks in the metadata. The workflow pngs here in the article do not have these chunks
The server may have “optimized” the png file by striping its meta data. I updated the file to json.
I attempted to download the ComfyUI workflow file by clicking the ‘Download’ button in the article, but instead of receiving a JSON file, I ended up with a PNG image.
Hi, the png files have workflow embedded in them. Just drag and drop it to comfy to load the workflow.
Hi Andrew, I’m trying it with AnimateDiff but I keep getting this error “‘VanillaTemporalModule’ object has no attribute ‘cons”, have you also got it / any solutions? thanks!
Btw, if you are on Mac and you have black images output instead of the animation, here is the workaround https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved/issues/48
Thanks for sharing, Andrew!
Do you know if there is any guideline in setting up sdxl locally for programmatic inference without gui?
a1111 has an api interface.
--apiI believe.why when i drag and drop the workflow into Comfy nothing happens, the workflow doesn’t load
You probably need to update your comfy
same for me on mac, I’ve updated and it’s the latest
Hi Andrew,
I hope you are doing well.
LCM-LoRA is not working on my side in AUTOMATIC1111. I followed your tutorial but it’s not working.
This is my result and settings: https://www.dropbox.com/scl/fi/tiv66ptkcm3qpxgz05lgp/Screenshot-2023-11-26-163044.jpg?rlkey=w56eama4loqmikauw03ep2yf6&dl=0
Please let me know how can I achieve a successful result like your tutorial.
Waiting for your response.
Thanks
Maybe you fell victim to the same Typo as I did…. The File ending should be safeteNSors, not SafeteSNors.
Name the File: lcm_lora_sd15.safeteNSors
@Andrew: Please change it in the Article, because the fatal Typo is nearly not visible at first 😉
good catch! thanks.
Hope Maybelle’s comment resolves your issue. You can watch the terminal to make sure the lora is loaded before the sampling steps.
I’ve made many tests in A1111 (stable diffusion webui) with ‘photon V1’, ‘Deliberate’ and other checkpoints and I noticed the images can be even better if you tweak the steps up to 6, CFG 2, Euler or Euler A, and LORA weight 0.7 or more. In some tests, 0.7 is the sweet spot (and required if you use more LORAS).
Thanks for the tips!!
Great tutorial and workflow.
Question: is it possible to provide an input image using a similar workflow (img2vid)? If so, is there a tutorial or workflow on how to do it?
yes, the comfyui workflow can be modified to use a starting img.
Can it work with automatic1111?
Not supported yet.
Technically it is possible.
Latest version of AnimateDiff extension for A1111 comes with LCM Sampling method, which, of course, is suitable for static image generation as well as for video (it will be available in standard Sampling method dropdown after extension update is installed).
In combination with LCM-LoRAs (which can be found e.g. on Civitai in both 1.5 and SDXL versions) that gives significant boost in generation time.
LCM-LoRAs can be successfully used with Euler A as well (and some others methods, but support may vary). You just have to experiment with CFG scale, number of steps and LoRA weight and see what works best for you (2.5 CFG, 8 steps, 0.45 LoRA weight with Euler A (or 0.75 for LCM) with JuggernautXL model in my case yields great results).