
Stable Diffusion Models, or checkpoint models, are pre-trained Stable Diffusion weights for generating a particular style of images.
What kind of images a model generates depends on the training images. A model won’t be able to generate a cat’s image if there’s never a cat in the training data. Likewise, if you only train a model with cat images, it will only generate cats.
We will introduce what models are, some popular ones, and how to install, use, and merge them.
This is part 4 of the beginner’s guide series.
Read part 1: Absolute beginner’s guide.
Read part 2: Prompt building.
Read part 3: Inpainting.
Table of Contents
Base models
Base models are AI image models trained with billions of images of diverse subjects and styles. They cost a lot of money and expertise to create, and only a few of them exist.
They are created to be versatile in creating different subjects and styles. Almost all of the checkpoint models you find on CivitAI, a resources site for sharing models, are derived from one of these base models.
The most popular base models are:
- Stable Diffusion v1.5
- Stable Diffusion XL
- Flux.1 dev
Stable diffusion v1.5

Runway ML, a partner of Stability AI, released Stable Diffusion 1.5 in October 2022. It is unclear what improvements it made over the 1.4 model, but the community quickly adopted it as the go-to base model.
Stable Diffusion v1.5 is a general-purpose model. The default image size is 512×512 pixels.
Stable Diffusion XL
SDXL model is an upgrade to the celebrated v1.5 and the forgotten v2 models.
The improvements of SDXL base model are
- Higher native resolution – 1024×1024 pixels compared to 512×512 pixels for v1.5
- Higher image quality (compared to the v1.5 base model)
- Capable of generating legible text
- It is easy to create darker images
Flux.1 dev

The Flux AI model was released by the Black Forest Labs, where many researchers were the original creators of Stable Diffusion 1.5.
The improvements of the Flux AI base model are:
- Legible text generation
- Excellent realistic images
- Excellent prompt adherence
The default image size of Flux.1 dev is 1024×1024 pixels.
Fine-tuned models
What is fine-tuning?
Fine-tuning is a common technique in machine learning. It involves taking a base model and training it more on a narrow dataset.
A fine-tuned model generates images similar to those used in the training. For example, the Anything v3 model is trained with anime images. So, it creates anime-style images by default.
Why do people make Stable Diffusion models?
The Stable Diffusion base model is great but not good at everything. For example, it generates anime-style images with the keyword “anime” in the prompt. However, creating images of a sub-genre of anime could be challenging. Instead of tinkering with the prompt, you can use a custom model fine-tuned with images of that sub-genre.
Images below are generated using the same prompts and settings but with different models.
- Realistic Vision: Realistic photo style.
- Anything v3: Anime style.
- Dreamshaper: Realistic painting style.



Using a model is an easy way to achieve a particular style.
How are models created?
Custom checkpoint models are made with (1) additional training and (2) Dreambooth. They both start with a base model like Stable Diffusion v1.5, SDXL, or Flux AI.
Additional training is achieved by training a base model with an additional dataset you are interested in. For example, you can train the Stable Diffusion v1.5 with an additional dataset of vintage cars to bias the cars’ aesthetic towards the vintage sub-genre.
Dreambooth, developed by Google, is a technique to inject custom subjects into text-to-image models. It works with as few as 3-5 custom images. You can take pictures of yourself and use Dreambooth to put yourself into the model. A model trained with Dreambooth requires a unique keyword to condition the model.
The checkpoint model is not the only model type. We also have textual inversion (also called embedding), LoRA, LyCORIS, and hypernetwork.
In this article, we will focus on the checkpoint model.
Popular Stable Diffusion Models
There are thousands of fine-tuned Stable Diffusion models, and the number is increasing daily. Below is a list of models that can be used for general purposes.
Realistic Vision

Base Model: Stable Diffusion 1.5
Realistic Vision v5 is suitable for generating anything realistic, whether they are people, objects, or scenes.
Learn more about generating realistic people.
DreamShaper

Base model: Stable Diffusion 1.5
The Dreamshaper model is fine-tuned for a portrait illustration style that combines photorealistic elements with computer graphics. It’s easy to use, and if you like this style, you will like it.
Juggernaut XL
Base model: Stable Diffusion XL
The Juggernaut XL model is a well-finetuned SDXL model that is especially good at generating realistic style photos. However, it was trained with diverse, high-quality images to create various styles. It is a good replacement for the SDXL base model.
Pony Diffusion
Base model: Stable Diffusion XL
Pony Diffusion is an SDXL model trained with a lot of anime and cartoon-style images. It is the go-to model for generating anything not realistic. The model is highly creative and follows prompts well.
Anything V3

Base model: Stable Diffusion 1.5
Anything V3 is a special-purpose model trained to produce high-quality anime-style images. You can use danbooru tags (like 1girl, white hair) in the text prompt.
It helps cast celebrities to amine style, which can then be blended seamlessly with illustrative elements.
One drawback (at least to me) is that it produces females with disproportional body shapes. I like to tone it down with F222.
Deliberate v2

Base model: Stable Diffusion 1.5
Deliberate v2 is another must-have model (so many!) that renders realistic illustrations. The results can be surprisingly good. Whenever you have a good prompt, switch to this model and see what you get!
F222

Base model: Stable Diffusion 1.5
F222 was initially trained to generate nudes, but people found it helpful in generating beautiful female portraits with correct body part relations. Contrary to what you might think, it’s pretty good at generating aesthetically pleasing clothing.
F222 is good for portraits. It tends to generate nudes. Include wardrobe terms like “dress” and “jeans” in the prompt.
Find more realistic photo-style models in this post.
ChilloutMix

Base model: Stable Diffusion 1.5
ChilloutMix is a special model for generating photo-quality Asian females. It is like the Asian counterpart of F222. Use with Korean embedding ulzzang-6500-v1 to create K-pop girls.
Like F222, it sometimes generates nudes. Suppress them with wardrobe terms like “dress” and “jeans” in the prompt and “nude” in the negative prompt.
Protogen v2.2 (Anime)

Base model: Stable Diffusion 1.5
Protogen v2.2 is classy. It generates illustrations and anime-style images that are of good taste.
GhostMix

Base model: Stable Diffusion 1.5
GhostMix is trained with Ghost in the Shell style, a classic anime in the 90s. You will find it useful for generating cyborgs and robots.
Waifu-diffusion

Base model: Stable Diffusion 1.5
Waifu Diffusion is a Japanese anime style.
Inkpunk Diffusion

Base model: Stable Diffusion 1.5
Inkpunk Diffusion is a Dreambooth-trained model with a very distinct illustration style.
Use keyword: nvinkpunk
Finding more models
Civitai is the go-to place for downloading models.
Huggingface is another good source, although the interface is not designed for Stable Diffusion models.
How to install and use a model
These instructions are for v1 and SDXL models.
To install a model in AUTOMATIC1111 GUI, download and place the checkpoint model file in the following folder
stable-diffusion-webui/models/Stable-diffusion/Press the reload button next to the checkpoint dropbox on the top left.
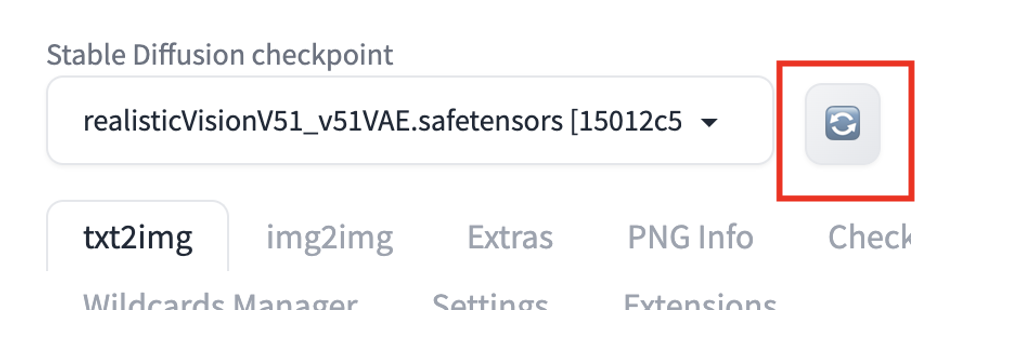
You should see the checkpoint file is available for selection. To use the model, select the new checkpoint file.
Alternatively, select the Checkpoints tab on the txt2img or img2img page and choose a model.
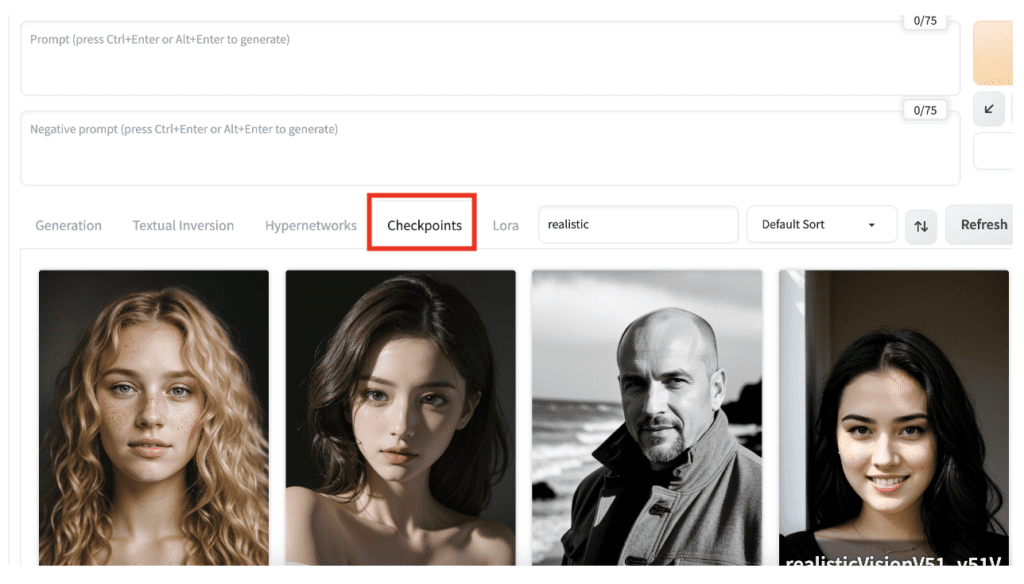
If you are new to AUTOMATIC1111 GUI, some models are preloaded in the Colab notebook included in the Quick Start Guide.
See the instructions for v2.0 and v2.1.
See the SDXL article for using the SDXL model.
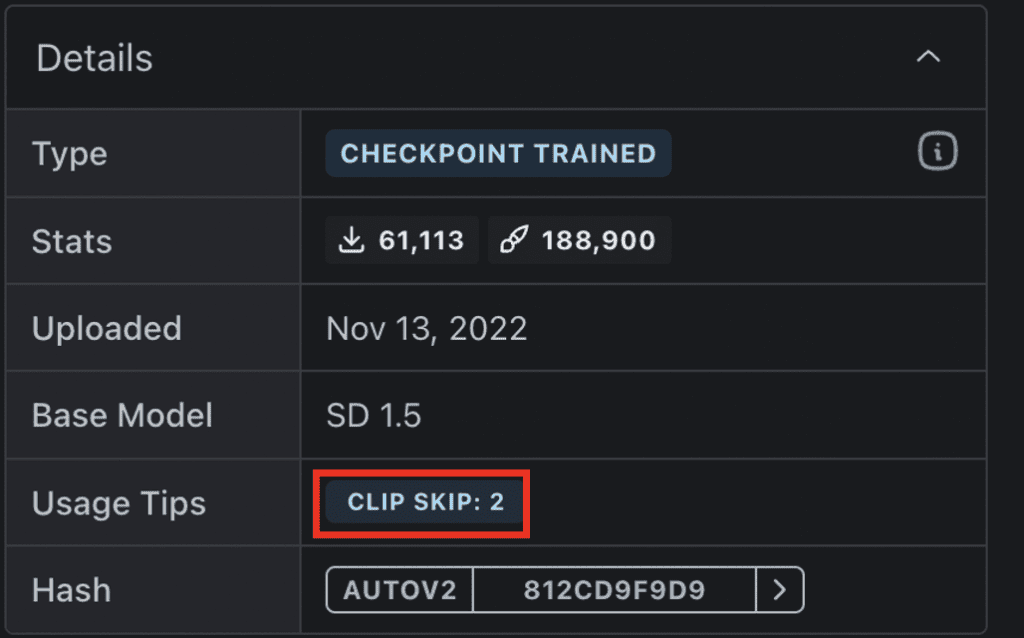
CLIP Skip
Some models recommend a different Clip Skip setting. You should follow this setting to get the intended style.
What is CLIP Skip?
CLIP Skip is a feature that skips a number of last layers in the CLIP text embedding network during image generation in Stable Diffusion. CLIP is the language model used in Stable Diffusion v1.5 models. It converts text tokens in the prompt into embeddings. It is a deep neural network model that contains many layers. CLIP Skip refers to how many of the last layers to skip.
In AUTOMATIC1111 and many Stable Diffusion software, CLIP Skip of 1 does not skip any layers. CLIP Skip of 2 skips the last layer, and so on.
Why do you want to skip some CLIP layers? A neural network summarizes information as it passes through layers. The earlier the layer is, the richer the information it contains.
Skipping CLIP layers can have a dramatic effect on images. Many anime models are trained with CLIP Skip of 2. See the examples below with different CLIP skips but the same prompt and seed.



Setting CLIP Skip in AUTOMATIC1111
You can set the CLIP Skip on the Settings Page > Stable Diffusion > Clip Skip. Adjust the value and click Apply Settings.
But if you need to change CLIP Skip regularly, a better way is to add it to the Quick Settings. Go to the Settings page > User Interface > Quicksettings list. Add CLIP_stop_at_last_layer. Click Apply Settings and Reload UI.
The clip skip slider should appear at the top of AUTOMATIC1111.
Merging two models
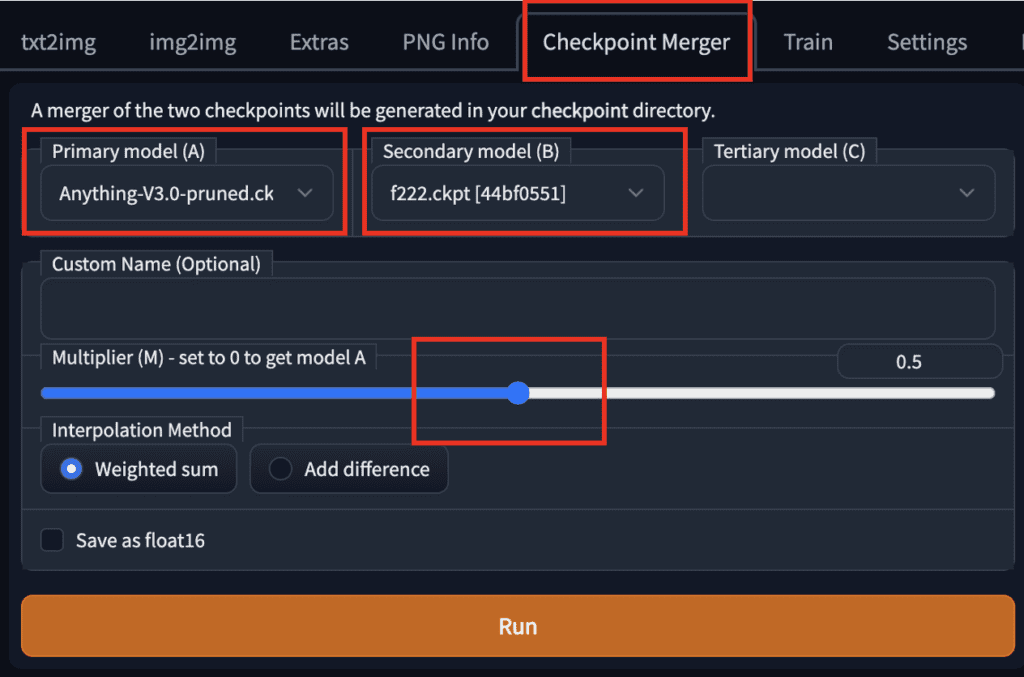
To merge two models using AUTOMATIC1111 GUI, go to the Checkpoint Merger tab and select the two models you want to merge in Primary model (A) and Secondary model (B).
Adjust the multiplier (M) to adjust the relative weight of the two models. Setting it to 0.5 would merge the two models with equal importance.
After pressing Run, the new merged model will be available for use.
Example of a merged model
Here are sample images from merging F222 and Anything V3 with equal weight (0.5):

The merged model sits between the realistic F222 and the anime Anything V3 styles. It is a very good model for generating illustration art with human figures.
Stable Diffusions model file formats
On a model download page, you may see several model file formats.
- Pruned
- Full
- EMA-only
- FP16
- FP32
- .pt
- .safetensor
This is confusing! Which one should you download?
Pruned vs Full vs EMA-only models
Some Stable Diffusion checkpoint models consist of two sets of weights: (1) The weights after the last training step and (2) the average weights over the last few training steps, called EMA (exponential moving average).
You can download the EMA-only model if you are only interested in using the model. These are the weights you use when you use the model. They are sometimes called pruned models.
You will only need the full model (i.e. A checkpoint file consisting of two sets of weights) if you want to fine-tune the model with additional training.
So, download the pruned or EMA-only model if you want to use it to generate images. This saves you some disk space. Trust me, your hard drive will fill up very soon!
Fp16 and fp32 models
FP stands for floating point. It is a computer’s way of storing decimal numbers. Here the decimal numbers are the model weights. FP16 takes 16 bits per number and is called half precision. FP32 takes 32 bits and is called full precision.
The training data for deep learning models (such as Stable Diffusion) is pretty noisy. You rarely need a full-precision model. The extra precision just stores noise!
So, download the FP16 models if available. They are about half as big. This saves you a few GB!
Safetensor models
The original pytorch model format is .pt. The downside of this format is that it is not secure. Someone can pack malicious codes in it. The code can run on your machine when you use the model.
Safetensors is an improved version of the PT model format. It does the same thing as storing the weights but will not execute any codes.
So, download the safetensors version whenever it is available. If not, download the PT files from a trustworthy source.
Other model types
Four main types of files can be called “models”. Let’s clarify them so you know what people are talking about.
- Checkpoint models are the real Stable Diffusion models. They contain all you need to generate an image. No additional files are required. They are large, typically 2 – 7 GB. They are the subject of this article.
- Textual inversions (also called embeddings) are small files defining new keywords to generate new objects or styles. They are small, typically 10 – 100 KB. You must use them with a checkpoint model.
- LoRA models are small patch files to checkpoint models for modifying styles. They are typically 10-200 MB. You must use them with a checkpoint model.
- Hypernetworks are additional network modules added to checkpoint models. They are typically 5 – 300 MB. You must use them with a checkpoint model.
Summary
I have introduced Stable Diffusion models, how they are made, a few common ones, and how to merge them. Using models can make your life easier when you have a specific style in mind.
Check out the Stable Diffusion Course for a step-by-step guided course.
This is part 4 of the beginner’s guide series.
Read part 1: Absolute beginner’s guide.
Read part 2: Prompt building.
Read part 3: Inpainting.
Is there any description or definition of the file structure?
(I mean a header for included parts, like diffusion model, clip_models, vae, recommended settings and others …)
Is there an identification possibility inside the model file, to allow it to be checked for its origin, even after renaming?
Version Stable diffusion v1.5 downloand link not working anymore… :/ It write this:
Invalid username or password.
Hi, link updated.
Great intro to SD. Love the ELI5 way to explaning technical jargons.
I am not a Stable Diffusion user yet. I am trying to rap my head around what is possible, first. As I read about it, obvious questions pop up. Search engines are not very helpful. Your articles have answered a lot of my questions. Thank you. A question I have not found an answer for is. Models are just fine tuning a base model. SD1.5 for example. Is there a way to train a model without the base model? I would like to get past any limitations caused by CompVis or Stability AI. Is it possible to make your own tiny SD1.5?
It is possible to train a v1 model from scratch but requires significant skill and resources. The base model costed $600k to train for gpus alone.
I’d like to have some information about the process, to have a better understanding of SD… not to actually train a new model. How is it done?
This one should do: https://stable-diffusion-art.com/how-stable-diffusion-work/
Thank you, I will read it carefully
I read the four “Absolute beginner” posts and I have a question that what is the good choice to read next tutorial?
Hey Ebi, I have the same question as you. What articles did you go through after these?
Of course it was not necessary. But it was appreciated. Don’t body shame. There might be women with large breasts reading this. They should feel as welcome and celebrated as anyone else.
Please try to be more kind and considerate of others in the future. Thank you. Be well.
LOL, you should speak to the manager about this.
For some models, when I click on the link, I don’t see a download button. How do I download these models? For example: inkpunk diffusion.
You will need to navigate to the checkpoint file page to download. I have added the download link the inkpunk.
Hey, sorry for ask but exist android versions too?
Running on Android is not practical currently.
Was it really necessary to use images of women with extensive cleavage to illustrate your post? Does this indicate you think your market is mostly men seeking images of women with exaggerated breasts?
No and no.
OP did not say anything about women with extensive cleavage in the article. Does this mean that you are assuming the gender of a person just by looking how big their breasts are?
I will give you a free advice Marie. Next time, write your own instructions article and use images of your choice.
I am thankful to the author for the hard work he put in to publish this very useful information. And frankly, i also liked his pictures, but that’s just my personal taste.
hello i have problem
C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui>git pull
error: Your local changes to the following files would be overwritten by merge:
javascript/hints.js
requirements.txt
Please commit your changes or stash them before you merge.
Aborting
Updating 5ab7f213..89f9faa6
venv “C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\venv\Scripts\Python.exe”
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Commit hash: 5ab7f213bec2f816f9c5644becb32eb72c8ffb89
Installing requirements
Launching Web UI with arguments:
No module ‘xformers’. Proceeding without it.
ControlNet v1.1.191
ControlNet v1.1.191
Error loading script: img2img.py
Traceback (most recent call last):
File “C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\modules\scripts.py”, line 256, in load_scripts
script_module = script_loading.load_module(scriptfile.path)
File “C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\modules\script_loading.py”, line 11, in load_module
module_spec.loader.exec_module(module)
File “”, line 883, in exec_module
File “”, line 241, in _call_with_frames_removed
File “C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\scripts\img2img.py”, line 16, in
from imwatermark import WatermarkEncoder
ModuleNotFoundError: No module named ‘imwatermark’
Error loading script: txt2img.py
Traceback (most recent call last):
File “C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\modules\scripts.py”, line 256, in load_scripts
script_module = script_loading.load_module(scriptfile.path)
File “C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\modules\script_loading.py”, line 11, in load_module
module_spec.loader.exec_module(module)
File “”, line 883, in exec_module
File “”, line 241, in _call_with_frames_removed
File “C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\scripts\txt2img.py”, line 14, in
from imwatermark import WatermarkEncoder
ModuleNotFoundError: No module named ‘imwatermark’
Loading weights [c0d1994c73] from C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\models\Stable-diffusion\realisticVisionV20_v20.safetensors
Creating model from config: C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\configs\v1-inference.yaml
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Applying cross attention optimization (Doggettx).
Textual inversion embeddings loaded(0):
Model loaded in 8.0s (load weights from disk: 0.3s, create model: 0.5s, apply weights to model: 3.9s, apply half(): 0.7s, move model to device: 0.7s, load textual inversion embeddings: 1.9s).
Traceback (most recent call last):
File “C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\launch.py”, line 353, in
start()
File “C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\launch.py”, line 348, in start
webui.webui()
File “C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\webui.py”, line 302, in webui
shared.demo = modules.ui.create_ui()
File “C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\modules\ui.py”, line 461, in create_ui
modules.scripts.scripts_txt2img.initialize_scripts(is_img2img=False)
File “C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\modules\scripts.py”, line 298, in initialize_scripts
script = script_class()
File “C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\scripts\controlnet.py”, line 209, in __init__
self.preprocessor = global_state.cache_preprocessors(global_state.cn_preprocessor_modules)
File “C:\stable-diffusion\stable-diffusion1\stable-diffusion-webui\scripts\global_state.py”, line 22, in cache_preprocessors
CACHE_SIZE = shared.cmd_opts.controlnet_preprocessor_cache_size
AttributeError: ‘Namespace’ object has no attribute ‘controlnet_preprocessor_cache_size’
Press any key to continue . . .
Maybe related. https://github.com/Mikubill/sd-webui-controlnet/issues/1381
Excuse me, sir. I want to add new model and VAE of like GhostMix. I already have inserted model and vae files into “stable-diffusion-webui/models/Stable-diffusion/” and “stable-diffusion-webui/models/VAE/” but it didn’t come out in the web UI.
Try to refresh button? It should come up after restart.
And check to see if you have downloaded the file correctly. The size of models should be at least 2GB.
hwo do you know the trigger word for specific model, also how do you know who is in the model file.
ey, is possible add any model from huggingface?
Yes, download and put in the model folder. In the colab notebook in quick start guide, you can provide a link to use directly.
I downloaded F222 and it arrived as a zip file. When I unzip it, do I just use the file called ‘data’ and do I need to rename it?
Hi, It should not be a .zip file but a file called f222.ckpt
You can put f222.ckpt in model folder and you are good to go.
im currently stuck at this point its not downloading
Already up to date.
venv “C:\Users\User\stable-diffusion-webui\venv\Scripts\Python.exe”
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Commit hash: 22bcc7be428c94e9408f589966c2040187245d81
Installing requirements for Web UI
Launching Web UI with arguments: –xformers
Loading weights [9e2c6ceff3] from C:\Users\User\stable-diffusion-webui\models\Stable-diffusion\f222.ckpt
Creating model from config: C:\Users\User\stable-diffusion-webui\configs\v1-inference.yaml
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
See temp solution here: https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/7901
thanks for the help its running now 🙂
Thank you so much! This article cleared up a lot of questions I had and it was super easy to understand.
You are welcome!
Thank you so much, by the way.
Like a good little geek, I’ve looked at Reddit and such for help. But people throw all of these terms around, that I have no idea what means. Figured it would all make sense eventually, but finding someone to break it all down is a godsend.
Do you *have to* use the “triggering word/key word”, to activate the models?
You don’t have to but you won’t get the intended effect.
Welcome to my site!
AWWW- I found it: https://stable-diffusion-art.com/embedding/#AUTOMATIC1111
-Thanks! You have the best, easiest tutorials I’ve ever seen!!
Do you have to merge the files? (it all starts getting really big) So say I have small niche LORA file do I have to merge it with a big checkpoint file to use it? Or can I say something in a prompt? Other methods?
Thanks loads for all your content, really informative and a huge help to get me started with AI content ?
You are welcome. Don’t forget to subscribe! 🙂
Seems like Anything URL is broken
Fixed. Thanks!
When I try to merge models it says: Error merging checkpoints: unhashable type: ‘list’
am I doing something wrong? I’m trying to merge a dreambooth face I trained, with a model I downloaded online called “midjourneyPapercut_v1.ckpt”
I’m not familiar with the papercut model. Perhaps you can systematically figure out whether it is a issue with setup or models.
1. Merge v1.4 and anythingv3 model with your setup. It should work.
2. Merge dreambooth model with v1.4. If it doesn’t work, the issue is with dreambooth.
3. Do the same for papercut.
Have you tried Dreambooth on a non SD base model (not 1.4 or 1.5) but rather using f222 as base? My finding is that you can’t get more than 5% of your likeness into one of these already finetuned models, I would like to hear from other’s experience.
No I haven’t tried it. I think models fine tuned with additional training is less stable since the fine tuning samples lack diversity. Dreambooth and text inversion were designed to solve this issue.