
Hypernetwork models are small neural networks for modifying styles.
In this post, you’ll learn everything you need to know about hypernetworks and how to use them to achieve the results you’re looking for. I’ll cover everything from the basics of a hypernetwork model to how to use it with AUTOMATIC1111 Stable Diffusion GUI. I’ll also show you some of my favorite hypernetworks that I use in my work.
Table of Contents
What is a hypernetwork in Stable Diffusion?
Hypernetwork is a fine-tuning technique developed by Novel AI, an early adopter of Stable Diffusion. It is a small neural network attached to a Stable Diffusion model to modify its style.
Where is the small hypernetwork inserted? It is, of course, the most critical part of the Stable Diffusion model: the cross-attention module of the noise predictor UNet. LoRA models similarly modify this part of Stable Diffusion models but in a different way.
The hypernetwork is usually a straightforward neural network: A fully connected linear network with dropout and activation. Just like the ones you would learn in the introductory course on neural networks. They hijack the cross-attention module by inserting two networks to transform the key and query vectors. Compare the original and the hijacked model architecture below.
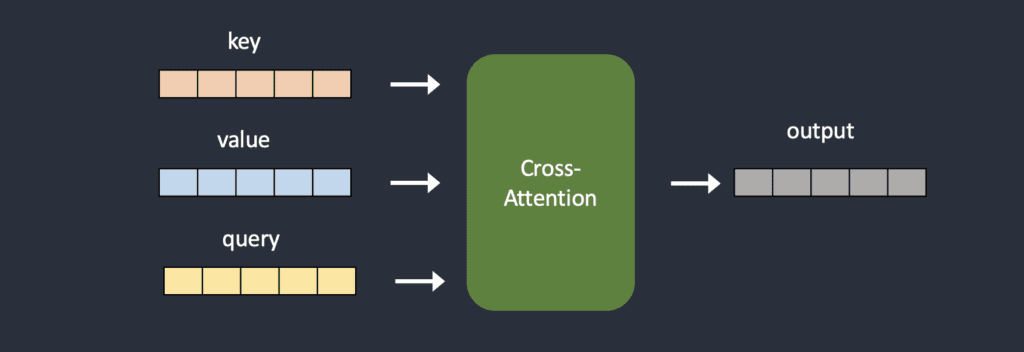
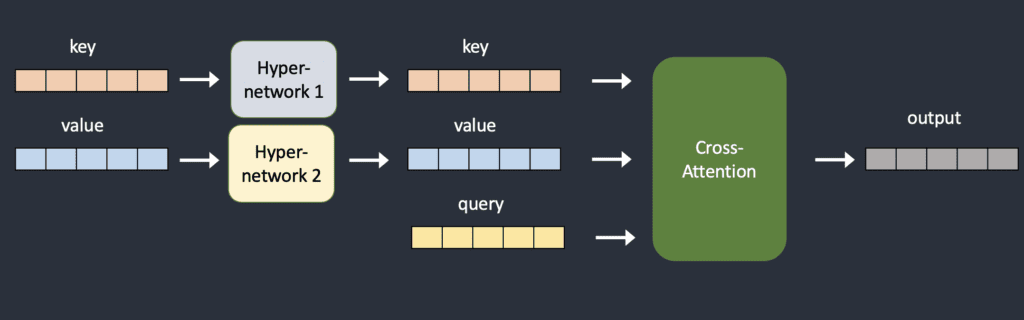
During training, the Stable Diffusion model is locked but the attached hypernetwork is allowed to change. Since the hypernetwork is small, training is fast and demands limited resources. Training can be done on a run-of-the-mill computer.
Fast training and small file sizes are the main appeals of hypernetworks.
You should be aware that it is NOT the same as the hypernetwork commonly known in machine learning. That’s a network that generates weights for another network. So no, the hypernetwork of Stable Diffusion was not invented in 2016.
Difference from other model types
I will explain the difference between hypernetworks and other model types: Checkpoint models, LoRA, and embeddings.
Checkpoint models
Checkpoint models contain all the necessary information to generate images. You can recognize them by their large file size. They range from 2 to 7 GB. Hypernetwork is typically below 200 MB.
Hypernetwork cannot function alone. It needs to work with a checkpoint model to generate images.
The checkpoint model is more powerful than a hypernetwork. It can store styles a lot better than a hypernetwork. When training a checkpoint model, the whole model is fine-tuned. When training a hypernetwork, only the hypernetwork is fine-tuned.
LoRA models
LoRA models are most similar to hypernetworks. They are both small and only modify the cross-attention module. The difference lies in how they modify it. A LoRA model modifies the cross-attention by changing its weight. Hypernetwork does it by inserting additional networks.
Users generally find LoRA models produce better results. Their file sizes are similar, typically below 200MB, and way smaller than checkpoint models.
LoRA is a data storage method. It does not define the training process, which can be dreambooth or additional training. Hypernetwork defines the training.
Embeddings
Embeddings are the result of a fine-tuning method called textual inversion. Like hypernetwork, textual inversion does not change the model. It simply defines new keywords to achieve certain styles.
Textual inversion and hypernetwork work on different parts of a Stable Diffusion model. Textual inversion creates new embeddings in the text encoder. Hypernetwork inserts a small network into the cross-attention module of the noise predictor.
Where to find hypernetworks
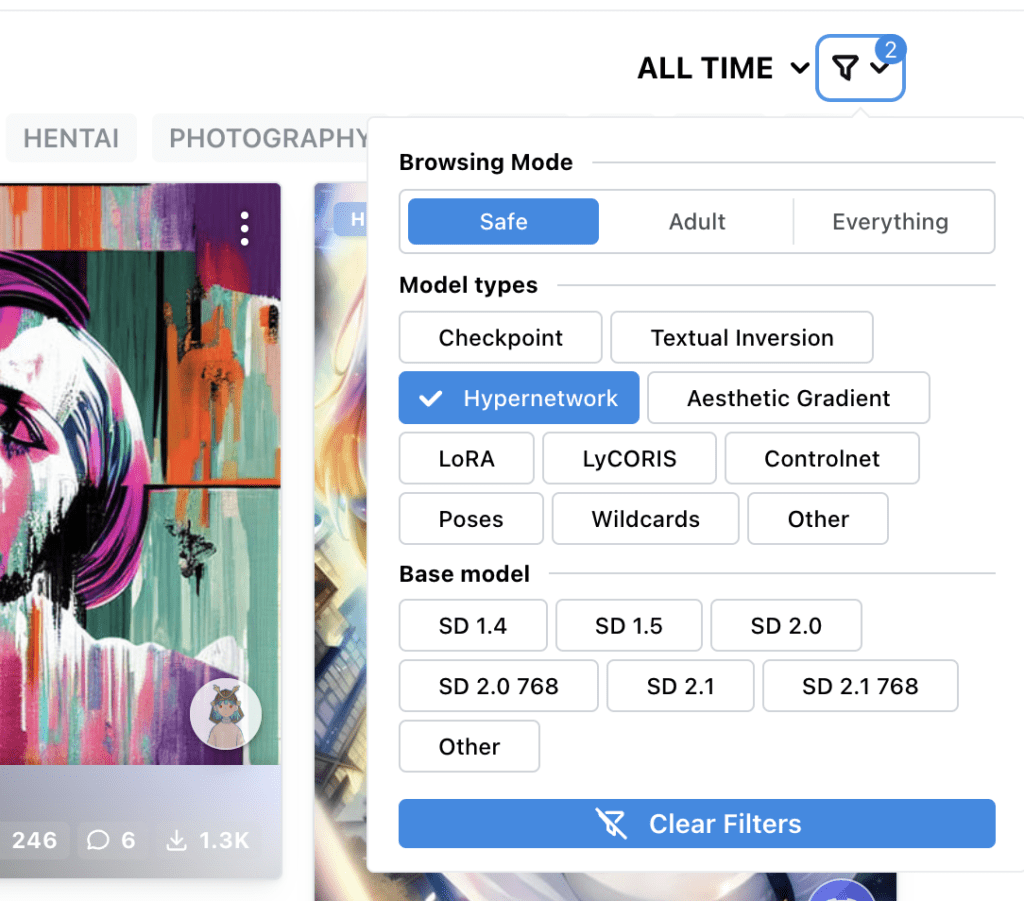
The best place is civitai.com. Filter the model type with Hypernetwork.
How to use hypernetworks
I will show you how to use hypernetworks in AUTOMATIC1111 Stable Diffusion GUI. You can use this GUI on Windows, Mac, or Google Colab.
Step 1: Install a hypernetwork model
To install hypernetwork models in AUTOMATIC1111 webui, put the model files in the following folder.
stable-diffusion-webui/models/hypernetworksStep 2: Use a hypernetwork model
To use a hypernetwork, put the following phrase in the prompt.
<hypernet:filename:multiplier>filename is the file name of the hypernetwork, excluding the extension (.pt, .bin, etc).
multiplier is the weight applied to the hypernetwork model. The default is 1. Setting it to 0 disables the model.
How can you be sure the filename is correct? Instead of writing this phrase, you should use the GUI to insert it. Click on the Hypernetworks tab. You should see a list of hypernetworks installed. Click on the one you want to use.
The hypernet phrase will be inserted in the prompt.
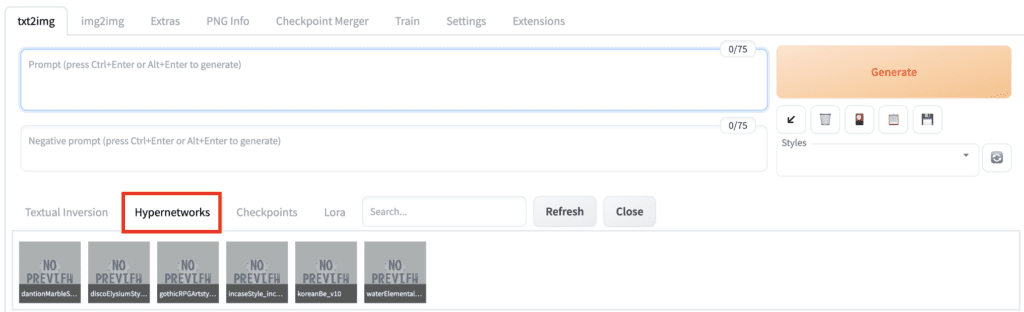
Be aware that the hypernet phrase is not treated as part of the prompt. It merely directs which hypernetworks to use. It will be removed after the hypernetwork is applied. So you cannot use any prompt syntax like [keyword1:keyword2:0.5] with them.
Step 3: Testing and creating art with the model
To give yourself the greatest chance of unlocking the intended style, start using the model it was trained with. But don’t stop there. Some hypernetworks require specific prompts or only work with certain subjects, so check out the prompt examples on the model page to see what works best.
And here’s a pro tip: if you notice your image is looking a bit too saturated, it may be a sign that you need to adjust the multiplier. It’s an easy fix. Stable Diffusion can sometimes interpret color saturation as the perfect way to hit the mark, but reducing the multiplier can help bring things back into balance.
Once you’ve confirmed that your hypernetwork is working its magic, why not experiment with using it on other models? You never know what interesting and unexpected effects might come up, and let’s be real, it’s just plain fun to play around with. So go ahead, let your creativity run wild.
Some hypernetworks
Here is my biased selection of hypernetworks.
Water Elemental
Water Elemental is a unique hypernetwork that can turn anything into water! Use the phrase “water elemental” before the subject. Make sure to describe the background. You can use this hypernetwork with the Stable Diffusion v1.5. Change the hypernetwork weight to adjust the water effect.
Water Elemental Hypernetwork Model Page
Prompt:
water elemental woman walking across a busy street <hypernet:waterElemental_10:0.7>



Prompt:
water elemental a boy running on water <hypernet:waterElemental_10:1>


Gothic RPG Artstyle
Gothic RPG Artstyle produces a stylish monochronic illustration style. Use with Protogen model.
Gothic RPG Artstyle Hypernetwork Model Page
Prompt:
drawing male leather jacket cyberpunk 2077 on a city street by WoD1 <hypernet:gothicRPGArtstyle_v1:1>




Readings
Here are some interesting reads if you have time to kill.
Hypernetwork Style Training, a tiny guide – A detailed training guide.
Illustrated self-attention – Explaining the mathematics of self-attention mechanism, which is similar to the cross-attention.
NovelAI’s improvements on Stable Diffusion – See the section “Hypernetworks” for their contributions. The other improvements are also interesting to read.
Adding Conditional Control to Text-to-Image Diffusion Models – It’s the ControlNet paper but contains an account of hypernetworks in Section 2.1 (Related Works).
I am a bit confused on the Civitai search. When I do a search on Civiai I only get 29 results for hypernetworks. Shouldn’t there be more? Also my search page is nothing like your illustration.
Yes you should get more. Make sure you don’t check any other filters. “Time period” should be set to “All time”.
Would you ever use LoRA and Hypernetworks? Are hypernetworks still being developed?
Thanks,
V
You are correct that people use LoRAs a lot more than hypernetworks. You can still train hypernetworks but we generally prefer to train LoRAs which is more powerful.
hello there, the article says the hypernetworks hijack the cross-attention module by inserting two networks to transform the key and query vectors, but the picture below shows the hypernetworks hijack the cross-attention module by inserting two networks to transform the key and vaule vectors. which one is crrect?
Hi, I tried to verbally describe the diagram but perhaps it was not clear. The diagram is accurate.
Thank you for your reply! Now I understand the principle. Also, thank you for your tutorial articles!
Excellent, and thanks for reviewing the https://civitai.com/models/5814/gothic-rpg-artstyle
it looks great