
Embedding, also called textual inversion, is an alternative way to control the style of your images in Stable Diffusion. We will review what embedding is, where to find them, and how to use them.
Table of Contents
What is embedding?
Embedding is the result of textual inversion, a method to define new keywords in a model without modifying it. The method has gained attention because its capable of injecting new styles or objects to a model with as few as 3 -5 sample images.
How does textual inversion work?
The amazing thing about textual inversion is NOT the ability to add new styles or objects — other fine-tuning methods can do that as well or better. It is the fact that it can do so without changing the model.
The diagram from the original research article reproduced below illustrates how it works.
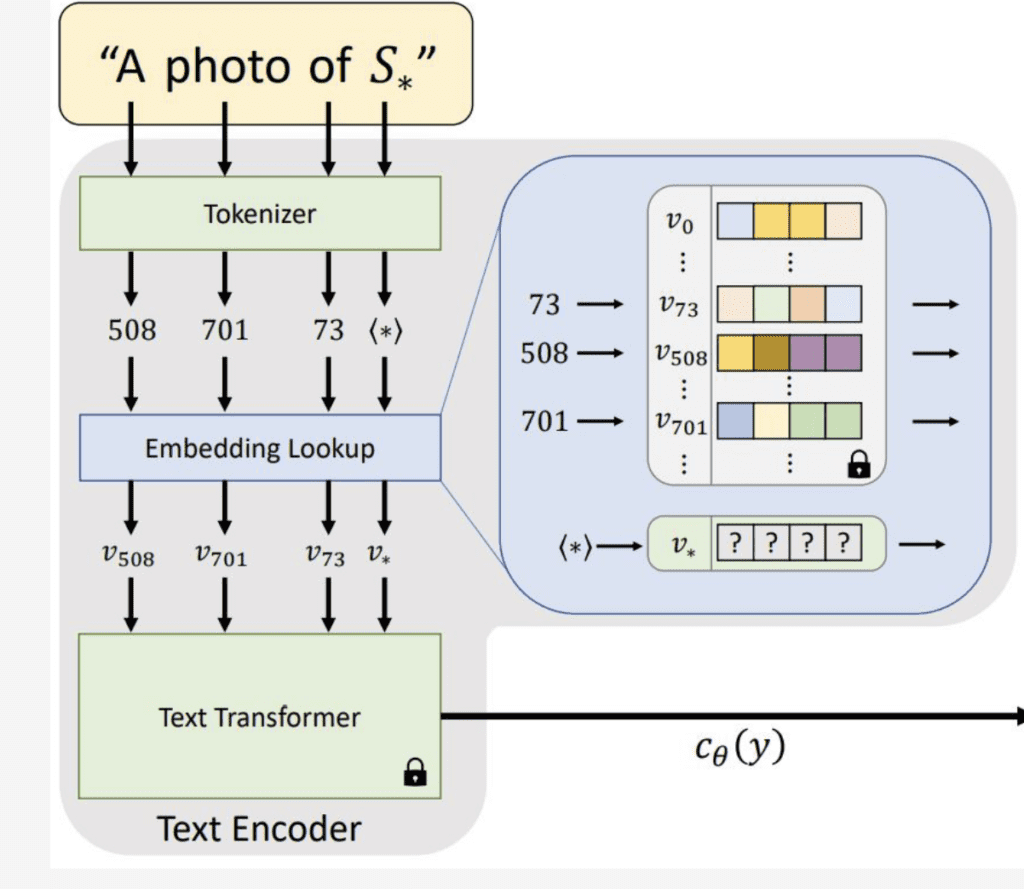
First you define a new keyword that’s not in the model for the new object or style. That new keyword will get tokenized (that is represented by a number) just like any other keywords in the prompt.
Each token is then converted to a unique embedding vector to be used by the model for image generation.
Textual inversion finds the embedding vector of the new keyword that best represents the new style or object, without changing any part of the model. You can think of it as finding a way within the language model to describe the new concept.
Examples of embeddings
Embeddings can be used for new objects. Below is an example of injecting a toy cat. Note that the new concept (toy cat) can be used with other existing concepts (boat, backpack, etc) in the model.

Embeddings can also be a new style. The example below shows embedding a new style and transferring the style to different context.

Where to find embeddings
The go-to place to download embeddings is Civitai. Filter with textual inversion to view embeddings only.
Hugging Face hosts the Stable Diffusion Concept Library, which is a repository of a large number of custom embeddings.
How to use embeddings
Web interface
Stable Diffusion Conceptualizer is a great way to try out embeddings without downloading them.
First, identify the embedding you want to test in the Concept Library. Let’s say you want to use this Marc Allante style. Next, identify the token needed to trigger this style. You can find it in the file token_identifier.txt, which is <Marc_Allante>.
Putting in the prompt
<Marc_Allante>a dog
Gives you the unique Marc Allante style.

The downside of the web interface is you cannot use the embedding with a different model or change any parameters.
AUTOMATIC1111
Using embedding in AUTOMATIC1111 is easy.
First, download an embedding file from Civitai or Concept Library.
If you download the file from the concept library, the embedding is the file named learned_embedds.bin. Make sure not to right-click and save in the below screen. That will save a webpage that it links to. Click on the file name and click the download button on the next page.
Next, rename the file to the keyword you wanted to use for this embedding. It has to be something that does not exist in the model. marc_allante.bin is a good choice.
Put it in the embeddings folder in the GUI’s working directory:
stable-diffusion-webui/embeddingsRestart the GUI. In the startup terminal, you should see a message like this:
Loaded a total of 1 textual inversion embeddings.
Embeddings: marc_allante
Use the filename as part of the prompt to
For example, the following prompt would work on AUTOMATIC1111.
(
marc_allante:1.2)a dog
We get the image with the expected style.

Shortcut to use embeddings in AUTOMATIC1111
An embedding won’t work even if it’s one letter off. Also, you cannot use an embedding trained for Stable Diffusion v1.5 with v2, and vice versa — Their language models are different.
You may wonder if you are using an embedding but not a keyword. It could be difficult to tell because Its effect can sometimes be subtle.
Instead of typing the filename of an embedding, you should use the GUI button to insert it. Click the Textual Inversion tab on the txt2img or img2img pages. Select the embedding you want to insert. The embedding keyword should be inserted in your prompt.
Note on using embeddings in AUTOMATIC1111
If you pay attention to the prompt, you will notice I have increased the strength of the triggering keyword marc_allante. I found that it is necessary to adjust the keyword strength. This may have something to do with the way AUTOMATIC1111 loads the embedding.
You may have to play with the keyword strength to get the effect you want. Below is an example of varying the strength while keeping the seed and everything else the same.

To further complicate the matter, the strength needed could be different for different seed values.
Useful embeddings
Many useful embeddings are negative embeddings. Put them in the negative prompt. (Very important!)
BadDream

BadDream is a negative embedding for the DreamShaper model.
UnrealisticDream

UnrealisticDream is a negative embedding for realistic style images. You should use it with a realistic model like Realistic Vision.
This negative embedding needs to be used with BadDream, so use it like this:
BadDream, UnrealisticDream
EasyNegative

EasyNegative is a negative embedding for anime models like Anything v3 and OrangeMix.
Embeddings I like
There are many embeddings available that I can try. Here are a few I found that I like.
wlop_style




If you have played with Stable Diffusion base models, you will find it impossible to generate wlop‘s style, no matter how hard you try. Embedding together with a custom model can finally do this.
The wlop_style embedding is able to render some nice illustration style of the artist wlop. It should be used with SirVeggie’s wlop-any custom model. (See this guide for installing custom models.)
Direct download link – wlop_style embedding
Direct download link – wlop-any model
If you try it out, you may find it doesn’t work. What you need to do is adjust the prompt strength.
A working prompt for AUTOMATIC1111 is
(wlop_style :0.6) (m_wlop:1.4) woman wearing dress, perfect face, beautiful detailed eyes, long hair, birds
Negative prompt:
closed eyes, disfigured, deformed
wlop_style is keyword for embedding, m_wlop is keyword for the model.
Don’t get frustrated if you don’t get the style. Try changing the prompt strengths of the two keywords. Some objects may not work with the embedding. Try some common objects in wlop’s artworks.
Kuvshinov




Kuvshinov is a Russian illustration. You can use the kuvshinov embedding with Stable Diffusion v1.4.
Prompt:
(_kuvshinov:1), a woman with beautiful detailed eyes, highlight hair
Negative prompt:
disfigured, deformed
(Note I have renamed the embedding as _kuvshinov.bin)
Difference between embedding, dreambooth and hypernetwork
Three popular methods to fine-tune Stable Diffusion models are textual inversion (embedding), dreambooth, and hypernetwork.
Embedding defines new keywords to describe a new concept without changing the model. The embedding vectors are stored in .bin or .pt files. Its file size is very small, usually less than 100 kB.
Dreambooth injects a new concept by fine-tuning the whole model. The file size is typical of Stable Diffusion, around 2 – 4 GB. The file extension is the same as other models, ckpt.
Hypernetwork is an additional network attached to the denoising UNet of the Stable Diffusion model. The purpose is to fine-tune a model without changing the model. The file size is typically about 100 MB.
Pros and Cons of using embedding
One of the advantages of using embedding is its small size. With a file size of 100 KB or less, storing multiple of them in your local storage is simple. Because embeddings are just new keywords, they can be used together in the same image.
The drawback of using embedding is sometimes it’s unclear which model it should be used with. For anime styles, try using them with anime models like Anything v3.
Despite its size advantage, embeddings can be more difficult to use than custom models. It is common to find yourself unable to reproduce the intended effect.
I am not seeing the embeddings in the Textual Inversion tab, please help.
I see a similar issue. I ended up installing a fresh copy of A1111.
press refresh on the right
Hi. Great article.
Is there a way to access the concept library for SD? It’s Aug 2023 and it says it’s offline (error).
Hi, I just tried and the link to concept library is working.
But nowadays Civitai has more embeddings.
Thanks for great article(s), one question: let’s say i’ve trained an embedding for a person (in automatic1111) that’s almost good but after all the steps there are some minor things i’d like to change (for instance the face should be thinner). Is there a way to modify the embedding without having to start from scratch?
Thanks for writing these. Very helpful. I have seen people on tiktok make videos are they using this type of AI? https://www.tiktok.com/@nosikompovolosikam/video/7227963092603243778
Amazing. An improved ways to steal other artist’s art. I can’t imagine how proud you are of yourselfs!
Try at least to generate something more original than Wlop a Kuvshinov, please.
Another very nice and enlightening post – thanks a lot! What I (a newbie) am trying to figure out is, if and how I can use embeddings inside an 1111 installation on Google Colab. I am lost at how to get the .bin file loaded into the 1111 interface in Colab instad of dropping it into a local folder. Could you please help me out there?
Many thanks! 😀
Yes, you can use the File Explorer on the left panel to drag and drop the bin file to the embedding folder. The location is
stable-diffusion-webui > embeddings
Great article! I’d like to point out a simple UI to use a large collection of the embeddings: aiTransformer (https://aitransformer.net/PromptBuilder). Full disclosure: I’m the developer of aiTransformer, tested every embedding listed on the Stable Diffusion Textual Inversion Embeddings page (https://cyberes.github.io/stable-diffusion-textual-inversion-models), finally integrated 500+ of the embeddings working on our platform (based on SD v1.5), including 2 mentioned in this article: and .
Beginner here, and I’ve just read every article you wrote (great articles).
I have a 2 part question I keep thinking about:
Would it make sense to combine both DreamBooth + Embedding?
I was thinking of generating female models wearing a specific jewellery item( i.e: earrings of a particular brand).
So my approach would be to leverage F222 as a base model and combine with photos of jewellery products for embedding.
For the photos; should it be a female model wearing this particular earring, or just earrings by itself?
Thanks for reading 🙂
For your case, it could be easier to generate the model first and use inpainting to add the earrings. Since they are small, you will need to inpaint at full resolution to generate good results.
I think combining dreambooth and embedding could work but needs to be done carefully. Most dreambooth models are not well behaved. The ability to generate other objects are often compromised.