
LoRA models are small Stable Diffusion models that apply tiny changes to standard checkpoint models. They are usually 10 to 100 times smaller than checkpoint models. That makes them very attractive to people who have an extensive collection of models.
This is a tutorial for beginners who haven’t used LoRA models before. You will learn what LoRA models are, where to find them, and how to use them in AUTOMATIC1111 GUI. Then you will find a few demos of LoRA models at the end.
Table of Contents
What are LoRA models?
LoRA (Low-Rank Adaptation) is a training technique for fine-tuning Stable Diffusion models.
But we already have training techniques such as Dreambooth and textual inversion. What’s the big deal about LoRA? LoRA offers a good trade-off between file size and training power. Dreambooth is powerful but results in large model files (2-7 GBs). Textual inversions are tiny (about 100 KBs), but you can’t do as much.
LoRA sits in between. Its file size is much more manageable (2 – 200 MBs), and the training power is decent.
Stable Diffusion users who like to try different models can tell you how quickly their local storage fills up. Because of the large size, It is hard to maintain a collection with a personal computer. LoRA is an excellent solution to the storage problem.
Like textual inversion, you cannot use a LoRA model alone. It must be used with a model checkpoint file. LoRA modifies styles by applying small changes to the accompanying model file.
LoRA is a great way to customize AI art models without filling up local storage.
How does LoRA work?
LoRA applies small changes to the most critical part of Stable Diffusion models: The cross-attention layers. It is the part of the model where the image and the prompt meet. Researchers found it sufficient to fine-tune this part of the model to achieve good training. The cross-attention layers are the yellow parts in the Stable Diffusion model architecture below.
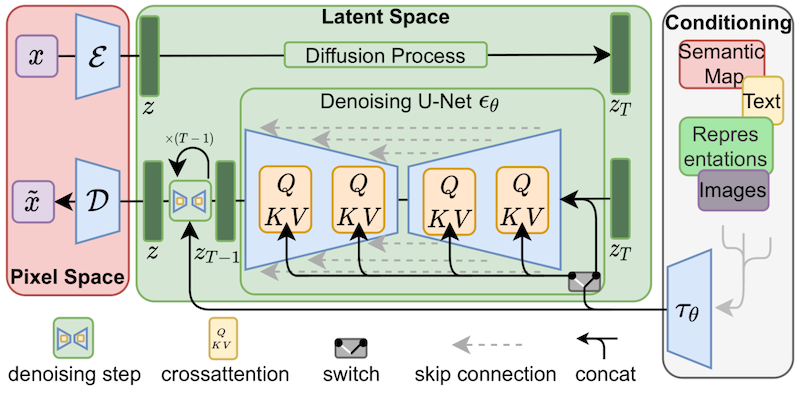
The weights of a cross-attention layer are arranged in matrices. Matrices are just a bunch of numbers arranged in columns and rows, like on an Excel spreadsheet. A LoRA model fine-tunes a model by adding its weights to these matrices.
How can LoRA model files be smaller if they need to store the same number of weights? The trick of LoRA is breaking a matrix into two smaller (low-rank) matrices. It can store a lot fewer numbers by doing this. Let’s illustrate this with the following example.
Let’s say the model has a matrix with 1,000 rows and 2,000 columns. That’s 2,000,000 numbers (1,000 x 2,000) to store in the model file. LoRA breaks down the matrix into a 1,000-by-2 matrix and a 2-by-2,000 matrix. That’s only 6,000 numbers (1,000 x 2 + 2 x 2,000), 333 times less. That’s why LoRA files are a lot smaller.
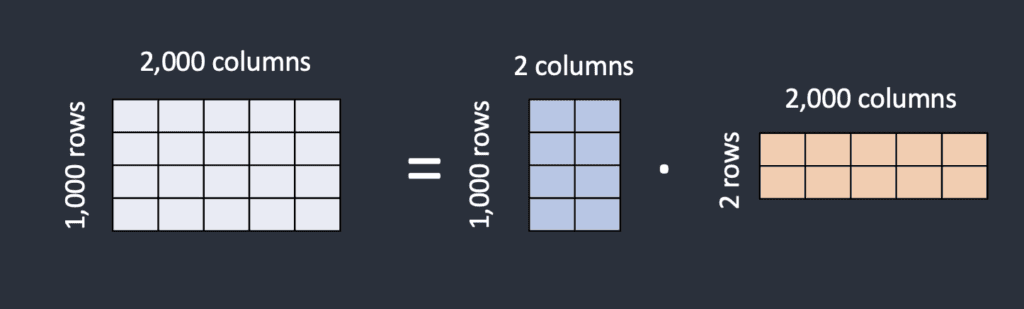
In this example, the rank of the matrices is 2. It is much lower than the original dimensions, so they are called low-rank matrices. The rank can be as low as 1.
But are there any harms in pulling a trick like that? Researchers found doing that in cross-attention layers did not affect the power of fine-tuning much. So we are good.
Where to find LoRA models?
Civitai
The go-to place to find Lora is Civitai. The site hosts a large collection of LoRA models. Apply the LORA filter to see only LoRA models. You may find that they all tend to be similar: female portraits, anime, realistic illustration styles, etc.
(Be aware that there’s a lot of NSFW stuff on Civitai. Make sure to put on NSFW filter if you don’t want to see something you cannot unsee…)
Hugging Face
Hugging Face is another good source of LoRA libraries. You will find more varieties of LoRA models. But there are not as many LoRA models there. Their collection is a lot smaller.
Search LoRA models in Hugging Face
How to use LoRA?
In this section, you will find instructions to use LoRA model in AUTOMATIC1111 Stable Diffusion GUI. You can use this GUI on Windows, Mac, or Google Colab.
AUTOMATIC1111 supports LoRA natively. You don’t need to install any extensions.
Step 1: Install the LoRA model
To install LoRA models in AUTOMATIC1111 webui, put the model files in the following folder.
stable-diffusion-webui/models/LoraStep 2: Use the LoRA in the prompt
To add a LoRA with weight in AUTOMATIC1111 Stable Diffusion WebUI, use the following syntax in the prompt or the negative prompt:
<lora: name: weight>name is the name of the LoRA model. It can be different from the filename.
weight is the emphasis applied to the LoRA model. It is similar to a keyword weight. The default is 1. Setting it to 0 disables the model.
How can you be sure the name is correct? Instead of typing this phrase, click the LoRA tab.
You should see a list of LoRA models installed. Click on the one you want to use.
The LoRA phrase will be inserted in the prompt.
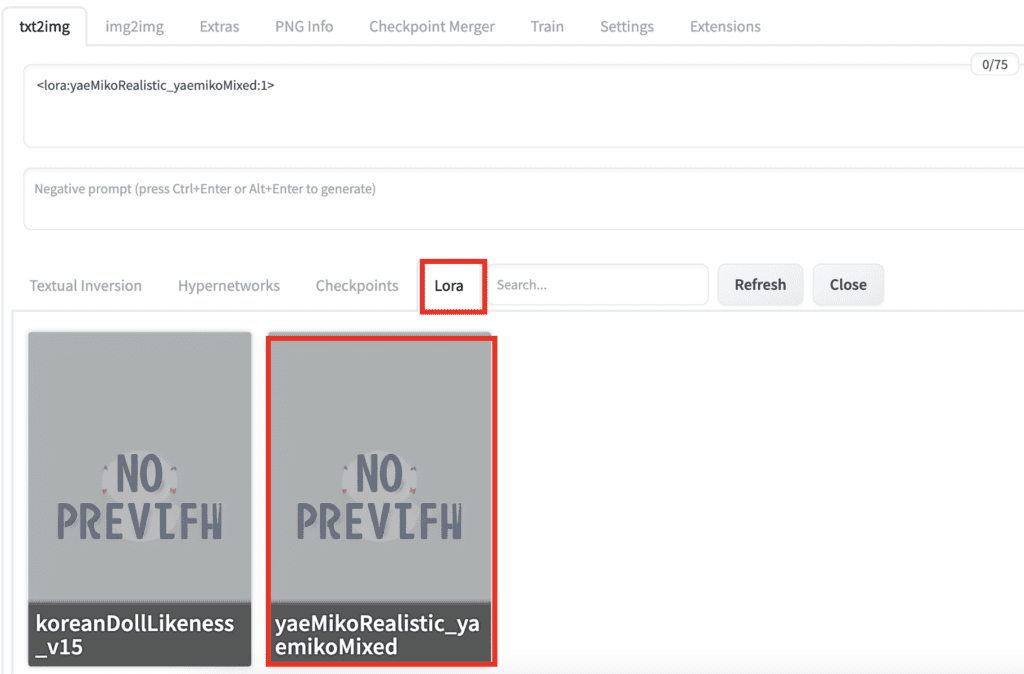
That’s it!
Notes on using LoRA
You may adjust the multiplier to crank up or tune down the effect. Setting the multiplier 0 disables the LoRA model. You can adjust the style effect between 0 and 1.
Some LoRA models are trained with Dreambooth. You will need to include a trigger keyword to use the LoRA model. You can find the trigger keyword on the model’s page.
Similar to embeddings, you can use multiple LoRA models at the same time. You can also use them with embeddings.
In AUTOMATIC1111, the LoRA phrase is not part of the prompt. It will be removed after the LoRA model is applied. That means you cannot use prompt syntax like [keyword1:keyword2: 0.8] with them.
Useful LoRA models
Detail Tweaker

Who doesn’t want more details in AI images? Detail Tweaker lets you increase or reduce fine details in an image. Now, you can dial in the amount of details you want.
Use a positive LoRA weight to increase the detail and a negative weight to decrease the detail.
Epi Noise Offset

It is well-known that many Stable Diffusion v1.5 models cannot generate dark images. The Epi Noise Offset LoRA lets you generate dark images with any v1.5 models. Use keywords dark studio, rim lighting, two tone lighting, dimly lit, low key, etc to induce the darkening effect.
Better Portrait lighting

Better Portrait Lighting LoRA adds good lighting to images. It’s worth a shot if you are working on portrait-style photorealistic images.
Interesting LoRA models
Here’s my biased selection of interesting LoRA models.
Shukezouma
Shukezouma LoRA model brings out a stylish Chinese ink painting theme. Shukezouma means the negative space (commonly seen in Chinese paintings) of the painting is so ample that a horse can pass through it.
Use this LoRA with the Chinese-style model Guo Feng.
Trigger keyword: shukezouma
Prompt:
(shukezouma:0.5) ,<lora:Moxin_Shukezouma:1> , chinese painting, half body, female, perfect symmetric face, detailed chinese dress, mountains, flowers, 1girl, tiger
Negative Prompt:
disfigured, ugly, bad, immature




Akemi Takada (1980s) Style
Akemi Takada is a Japanese manga illustrator. This is for you if you like Japanese anime in the 1980s and 1990s.
Use with AbyssOrangeMix2 model.
Prompt:
takada akemi, Tifa lockhart as magician, Final Fantasy VII, 1girl, small breast, beautiful eyes, brown hair, smiling, red eyes, highres, diamond earring, long hair, side parted hair, hair behind ear, upper body, stylish dress, indoors, bar 1980s (style), painting (medium), retro artstyle, watercolor (medium) <lora:akemiTakada1980sStyle_1:0.6>
Negative prompt:
(worst quality, low quality:1.4), (painting by bad-artist-anime:0.9), (painting by bad-artist:0.9), watermark, text, error, blurry, jpeg artifacts, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, artist name, bad anatomy




Cyberpunk 2077 Tarot card
This LoRA model generates cyborgs and cities with a futuristic cyberpunk style.
Used with Anything v5
Prompt:
cyberpunk, tarot card, close up, portrait, bionic body, cat, young man, perfect human symmetric face, leather metallic jacket, circuit, city street in background, natural lighting, masterpiece <lora:cyberpunk2077Tarot_tarotCard512x1024:0.6>
Negative prompt:
(worst quality, low quality:1.4), (painting by bad-artist-anime:0.9), (painting by bad-artist:0.9), watermark, text, error, blurry, jpeg artifacts, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, artist name, bad anatomy, big breast




Summary
LoRA models are small modifiers of checkpoint models. You can easily use them in AUTOMATIC1111 by including a phrase in the prompt.
That’s it for today! I will tell you how to train LoRA models in a future article.
Below are some additional readings for curious minds.
- Using LoRA for Efficient Stable Diffusion Fine-Tuning (Hugging Face blog). A good overview of how LoRA is applied to Stable Diffusion.
- LoRA: Low-Rank Adaptation of Large Language Models (2021). The research article first proposed the LoRA technique. (for language models)
- Github: Low-rank Adaptation for Fast Text-to-Image Diffusion Fine-tuning. This is the initial work applying LoRA to Stable Diffusion. You will find an excellent technical description of LoRA.
Hi Andrew! Great info as always…
I used the LoRas months ago successfully but from some time ago… they stopped working for me. No matter what I do, increase or decrease the weight. (I installed them via the Civitai Helper).
I currently use Realistic_Vision, but when I try with other checkpoints… nothing.
Am I missing something here? Is a setting on/off?
Thanks!
Magnificent information, thanks a lot Andrew (My namesake 😂)
I hope this is a complement to me LOL
Do Lora models work only with certain other models? for example your cyberpunk 2077 lora model says it was trained with deliberate. Does it mean one has tu use it with deliberate model? or it can be used with anything?
Use with the base model for the expected effect.
You can use with any model but YMMV.
Andrew, very informative! Do you ever work on projects with LoRa training?
Yes, and a tutorial is in the queue!
Thank you for sharing this precious knowledge! It really saved our time a lot.
Liked you pfp! Mind sharing it? 🙂
I am confused as to what type of information is included in a LoRA specifically. I can see many Loras on CivitAI that have specific poses, for example sitting with crossed arms. But why would I need a Lora for that? Couldn’t I just type ‘sitting, crossed arms’ in my prompt with a regular model 1.5?
Also, if a Lora is NSFW and it shows examples of nude characters, does that mean that every time I apply such Lora my output will ALWAYS be of naked characters? I guess I don’t understand what parameters get automatically applied by using a Lora.
Thanks btw, your guides are awesome, I read them all! Good job
Lora is simply a method to store small modifications to a SD model. It is no different from custom checkpoint models, except it has additional constraint in how the model can be changed. So it is less powerful.
Lora usually stores a distinct style (e.g. anime, realistic people) or facial feature (e.g. a celebrity). It’s true that you could achieve them through prompting the v1.5 model. But the result is often not as good as it could be. So people finetune the v1.5 model with a lot of images with similar content so that the lora can do ONE thing really well.
Thank you for reading 🙂
How do we make our own lora?
Tutorial: https://stable-diffusion-art.com/train-lora/
What about another loras that isn’t in huggins face – Civitai? Where can i find them? for example, i can find lora:CyberpunkStyleV3:0.8, , . Where can i find this lora? Thanks
Those are two main sources. try use google search. If you cannot find it, it is no longer available.
Use a similar one. Lora is rarely irreplaceable.
Thank you!
I’m stumped. When I installed the web ui there was no Lora folder in the model directory. I made my own Lora folder and directed it the ui to that one but it still can’t recognize the files. I put some of the files in the SD model folder to see if they were detected by the ui (they were), the Lora models themselves don’t seem to be the issue.
Mmm… You should not need to make your own. It is under stable-diffusion-webui > models > Lora.
See if you have put the Lora in the right place.
If I wanted to train my products to generate images of them in environments, am I better off using a different Lora for each of my products? I’m new and not sure how to approach since there’s so much information around creating images of people versus product photography.
Love your articles! You’ve been super helpful so far.
Training a special model gives you the best result.
Yes, best practice is to train one model for one product.
Some people simply use inpainting for this.
Hey dude, been going through all your tutorials and they are all great. Really good job at balancing keeping it simple and delving into the more complex aspects. Keep up the good work!
Thanks!
nice, thanks!
How can I apply a LoRA model to an existing image? ie not going through txt2img
That’s not possible.
If the image is generated by SD, you can try to see if the generation params are written in the PNG info. Then use them to generate a new image with LoRA.
Several Loras listed on Civitai offer several trigger words, for example MoXin lists wuchangshuo, shuimobysim, bonian, zhenbanqiao, badashanren. How would i get the prompt to use only only one style?
They may have put several models on one page. you will need to try one at a time, ideally with the prompt with the example picture they provided.
Why I’am getting black image when trying to generate something with lora model?
I extracted LORAs from models I made with Dreambooth and they work great with the SD 1.5 checkpoint, but seem to do nothing at all if I use any other checkpoint. Can you explain this to me? Thanks.
Lora is simply a compressed data storage method. Your lora model is stored with respect to the SD 1.5 model. There’s no guarantee it would work the same when you apply it to another model. In principle, the closer the other model it is to 1.5, the better it works. Perhaps you can test it on 1.4 or other 1.5 derivatives.
I would like to know why LoRA can adjust weights using and use multiple models at the same time. What is the principle behind this?
It applies two delta weights.
See
https://github.com/cloneofsimo/lora#merging-full-model-with-lora
and
https://github.com/cloneofsimo/lora#merging-lora-with-lora
which file should i download from LORA?
Hi, if you go to civitai, filter the model type and show only LoRA. Then use the download button to download.