
The Classifier-Free Guidance (CFG) scale controls how closely a prompt should be followed during sampling in Stable Diffusion. It is a setting available in nearly all Stable Diffusion AI image generators.
This post will teach you everything about the CFG scale in Stable Diffusion.
Table of Contents
What does the CFG scale do?
Let’s use the following prompt and see the effect of changing the CFG scale.
breathtaking, cans, geometric patterns, dynamic pose, Eclectic, colorful, and outfit, full body portrait, portrait, close up of a Nerdy Cleopatra, she is embarrassed, surreal, Bokeh, Proud, Bardcore, Lens Flare, painting, pavel, sokov
Model: Protovision XL High Fidelity 3D
At a very low value of 1, the prompt is almost not followed. The image lacks vibrance.
At a higher value of 3, the style described by the prompt emerges.
At a typical value of 7, the image is similar to that of a larger CFG scale.
Higher CFG values tend to show similar images, with the colors becoming increasingly saturated.
We typically set the CFG value to be between 7 and 10. This allows the prompt to direct the image without saturation.
CFG scale for LCM and turbo models
The typical value of 7 to 10 does not apply to all models. When using fast-sampling models like LCM LoRA and SDXL Turbo, the typical values of the CFG scale are much lower.
The CFG scale is typically set to 1 to 2.
What is classifier-free guidance?
To understand classifier-free, you must first understand its predecessor, classifier guidance.
Classifier guidance
Classifier guidance is a way to put image labels in diffusion models. You can use a label to guide the diffusion process. For example, the label cat steers the model to generate cats.
The classifier guidance scale is a parameter for controlling how closely the diffusion process should follow the label.
Suppose there are 3 groups of images with labels cat, dog, and human. If the diffusion is unguided, the model will draw samples from each group’s total population, but sometimes, it may draw images that could fit two labels, e.g., a boy petting a dog.
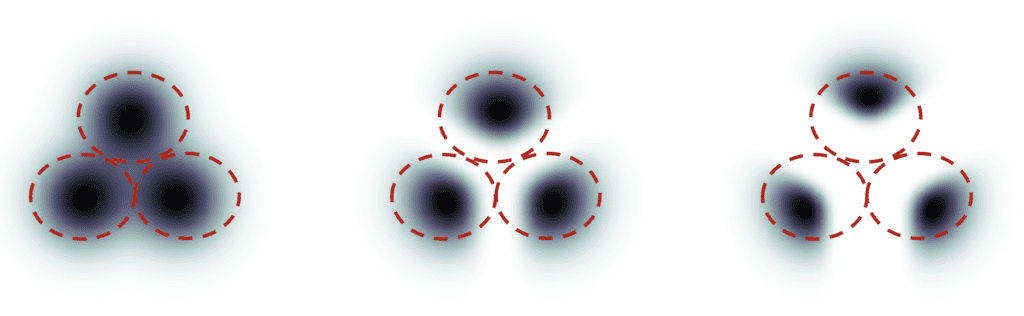
With high classifier guidance, the images produced by the diffusion model would be biased toward the extreme or unambiguous examples. If you ask the model for a cat, it will return an image that is unambiguously a cat and nothing else.
The classifier guidance scale controls how closely the guidance is followed. In the figure above, the sampling on the right has a higher classifier guidance scale than the one in the middle. In practice, this scale value is the multiplier to the drift term toward the data with that label.
Classifier-free guidance
Although classifier guidance achieved record-breaking performance, it needs an extra model to provide that guidance. This has presented some difficulties in training.
Classifier-free guidance, in its authors’ terms, is a way to achieve classifier guidance without a classifier. Instead of using a separate guidance model, they use image captions and train a conditional diffusion model.
They put the classifier part as conditioning of the noise predictor U-Net, achieving the so-called “classifier-free” (i.e., without a separate image classifier) guidance in image generation.
The text prompt provides this guidance in text-to-image.
Classifier-free guidance scale
Now, we have a classifier-free diffusion process using conditioning. How do we control how much the AI-generated images should follow the guidance?
The CFG scale controls how much the text prompt steers the diffusion process.
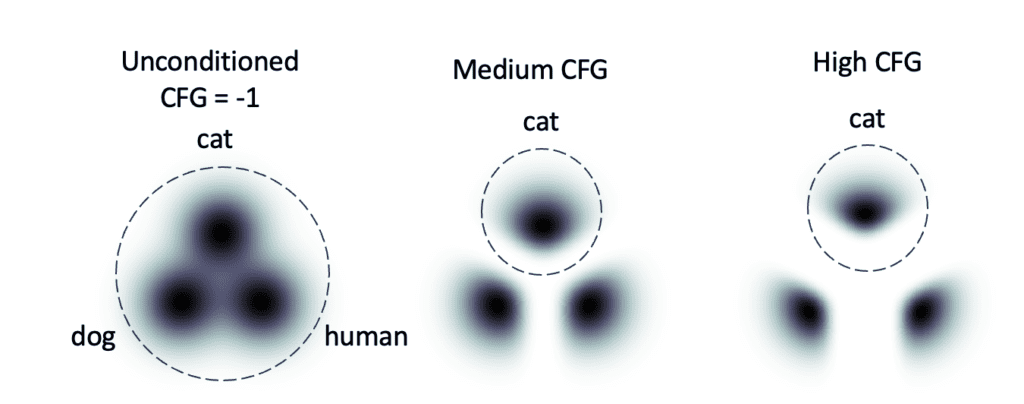
The effect is similar to the classifier guidance. Let’s consider three prompts: a cat, a dog, and a human, presented by the 3 groups of images below. You put in the prompt:
a cat.
- If the CFG scale is -1, the prompt is ignored. You have an equal chance of generating a cat, a dog, and a human.
- The prompt is followed if the CFG scale is moderate (7-10). You always get a cat.
- You get unambiguous images of cats at a high CFG scale.
Training of classifier-free guidance
The classifier-free guidance model needs to predict the noise with and without conditioning. So, in principle, you need to train a conditioned model and an unconditioned model.
You can greatly simplify things by training only ONE model that’s capable of doing both. This is done by occasionally dropping conditioning in training and replacing the conditional text with blank tokens.
What is the best CFG scale?
Now, you know how CFG works. You may wonder what the best CFG value is if there’s any.
The answer is there are reasonable values (7-10) but no best value.
The CFG scale sets the tradeoff between accuracy and diversity. You get more accurate images at a high CFG value and more diverse images at a low CFG value.
Sampling steps with CFG
So, how do we USE the CFG scale? It is used during the sampling steps.
- We first start with a random image.
- Estimate the noise of the image conditioned by the prompt and the totally unconditioned.
- The image moves in the direction of the between the conditioned and the unconditioned noise. The CFG scale is how big the step is.
- Adjust the noise of the image according to the noise schedule.
Repeat steps 2 to 4 until the end of the sampling steps.
So, you need to estimate noise two times when using CFG. One is conditioned with text, and the other is unconditioned.
Hijacking the CFG to enable the negative prompt
You may have wondered how the negative prompt enters the picture. In the training and sampling, negative prompts are not used!
The negative prompt is a hack: It is enabled by replacing the unconditioned noise with the noise predicted by the negative prompt in the sampling steps.
Without a negative prompt, you use blank tokens to predict the unconditioned noise. The image moves towards the prompt and away from random subjects.
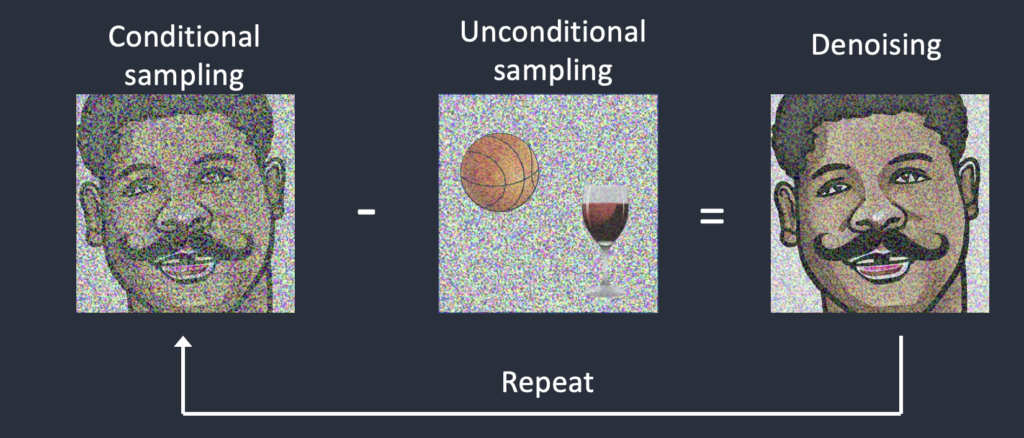
When using the negative prompt, you use it to predict the “unconditioned” noise. Now, the image moves towards the prompt and away from the negative prompt.

See how the negative prompt works for details.
The same technique can be used to enable negative image prompts.
Esto es genial