
We can put a face in Stable Diffusion using LoRA and dreambooth checkpoint models. But both require training a new model, which can be time-consuming. What if you can inject a face instantly at sampling without training?
This ComfyUI workflow copies the face of a person from input images. It can be used like a custom LoRA and checkpoint model, but no training is required.
It is fast and convenient!
It takes input images like these (images from the LoRA training dataset):

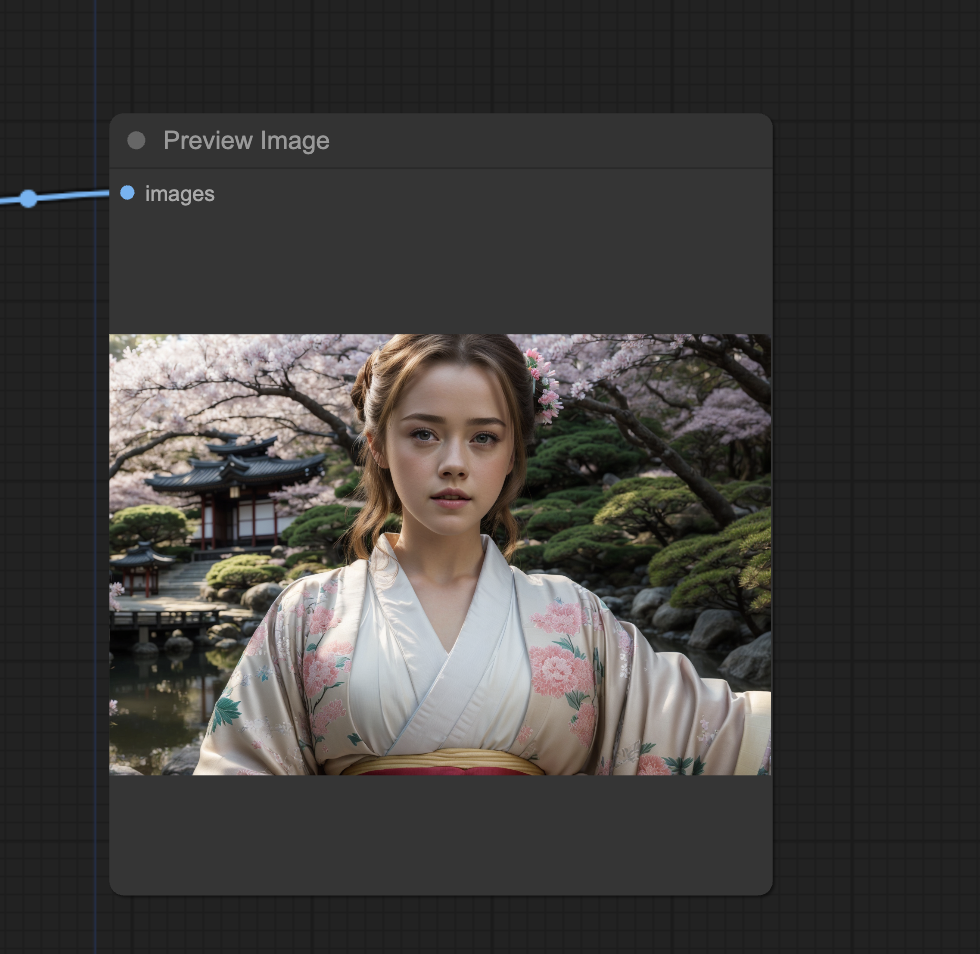
And you can generate images with any prompt.

You must be a member of this site to download the JSON workflow.
Table of Contents
Software
Stable Diffusion GUI
We will use ComfyUI, a node-based Stable Diffusion GUI. You can use ComfyUI on Window/Mac or Google Colab.
Check out Think Diffusion for a fully managed ComfyUI/A1111/Forge online service. They offer 20% extra credits to our readers. (and a small commission to support this site if you sign up)
See the beginner’s guide for ComfyUI if you haven’t used it.
How the generator works
It uses the IP-adapter with the Face ID Plus v2 model. It extracts the faces from the input images, converts them to embeddings, and feeds them to the IP-adapter. The IP-adapter conditions the image generation
Step-by-step guide
Step 0: Load the ComfyUI workflow
Download the workflow JSON file below.
Drag and drop it to ComfyUI to load.
Go through the drill
Every time you try to run a new workflow, you may need to do some or all of the following steps.
- Install ComfyUI Manager
- Install missing nodes
- Update everything
Install ComfyUI Manager
Install ComfyUI manager if you haven’t done so already. It provides an easy way to update ComfyUI and install missing nodes.
To install this custom node, go to the custom nodes folder in the PowerShell (Windows) or Terminal (Mac) App:
cd ComfyUI/custom_nodesInstall ComfyUI by cloning the repository under the custom_nodes folder.
git clone https://github.com/ltdrdata/ComfyUI-ManagerRestart ComfyUI completely. You should see a new Manager button appearing on the menu.
If you don’t see the Manager button, check the terminal for error messages. One common issue is GIT not installed. Installing it and repeat the steps should resolve the issue.
Install missing custom nodes
To install the custom nodes that are used by the workflow but you don’t have:
- Click Manager in the Menu.
- Click Install Missing custom Nodes.
- Restart ComfyUI completely.
Update everything
You can use ComfyUI manager to update custom nodes and ComfyUI itself.
- Click Manager in the Menu.
- Click Updates All. It may take a while to be done.
- Restart the ComfyUI and refresh the ComfyUI page.
Install Insight face
ComfyUI has recently updated the Python version. You first need to determine what Python version you are using.
Open the File Explorer App. Navigate to the ComfyUI_windows_portable folder. In the address bar, type cmd and press Enter.
A terminal should show up.
In the terminal, type the following command and press Enter.
.\python_embeded\python.exe --versionIt should show either Python 3.10.x or 3.11.x.
Download the InsightFace installation file.
Put the file in the ComfyUI_windows_portable folder.
Go back to the terminal.
If you use Python 3.10.x, run:
.\python_embeded\python.exe -m pip install .\insightface-0.7.3-cp310-cp310-win_amd64.whlIf you use Python 3.11.x, run:
.\python_embeded\python.exe -m pip install .\insightface-0.7.3-cp311-cp311-win_amd64.whlInsight Face should have been installed after running the command.
Step 1: Set input images
Set input images in the Load Image nodes. You can download the training images to follow this tutorial.
Realistic woman training dataset (1024×1024)
Step 2: Set checkpoint model
Download the Realistic Vision model. Put it in the Comfyui > models > checkpoints folder.
Refresh the page and select the Realistic model in the Load Checkpoint node.
Step 3: Set IP-adapter models
Install IPAdapter model
Download the Face ID Plus v2 IP-adapter model. Put the file in ComfyUI > models > ipadapter folder.
Install Clip Vision
Download the SD 1.5 CLIP vision model. Rename it to CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors. Put the file in ComfyUI > models > clip_vision folder.
Face ID Plus v2 LoRA
Download the LoRA. Put the file in ComfyUI > models > loras folder.
Restart ComfyUI
Restart ComfyUI completely by closing and reopening the terminal.
You should see the workflow like this:
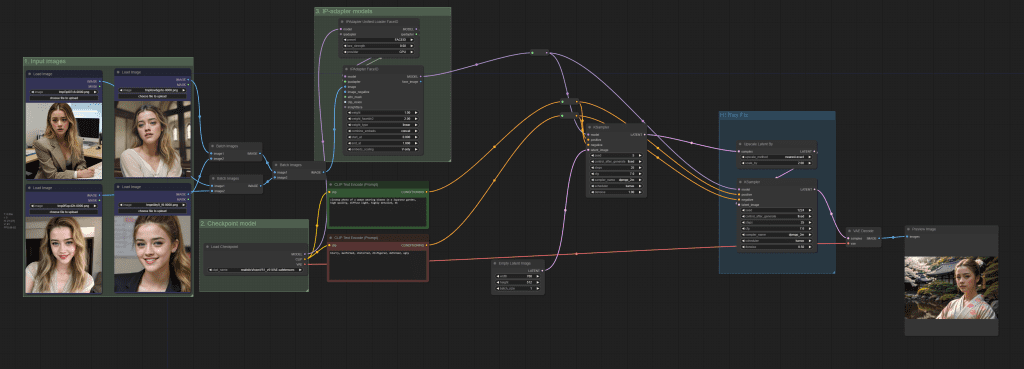
Step 4: Run the Instant LoRA workflow
Click Queue Prompt to run the workflow.
Customization
You can disable the high-resolution fix by right-clicking the Hi Res Fix group > By Pass Group Node.
You can easily duplicate the batch images and load image nodes to increase the number of input images. 4 seems to be enough for a good face.
Very, very cool. Thank you Andrew =)
Hey Andrew,
I want to create my own instagram fashion models and post them on social media. I’ve had a workflow before joining your course. It’s simple but I want to optimize it for my use case with your help: Generating my initial face -> IPAdapter (initial face) + random body (Depth) and generating those pictures. As model I use realvisV5.0 and no lora.
I want extremely photorealistic images and want to be faster as I have to search for identical body types in different positions. Would you recommend using a Lora and how would you optimize this workflow?
Really looking forwards for your answer.
Flux is the way to go with you want realism. But it won’t be fast.
A SDXL model should have a good balance between speed and quality.
Andrew, not sure if you allow this on your site, but I made a post on Civitai which may be of use to people here, especially those who are getting errors with Unified Loader.
I called it ‘IP Adapter Bundle’, all models/ViT/LoRAs in one place. If nothing else, at least it shows the tree structure, so people know exactly where each file needs to be placed (as of 2024):
https://civitai.com/models/907545/ip-adapter-bundle
I don’t mean to self-promote, this is just a small contribution from me to the AI community. In saying that, feel free to delete this comment if it breaks your T&C. 👍
I learned how to use IP Adapter thanks to you, by reading your IP Adapter tutorial, so thank you for the work you do. 👍
Hello Andrew,
I am sure I downloaded all the files correctly and put them into right folder. however I am still getting error “IPAdapterUnifiedLoaderFaceID
LoRA model not found.”
any idea why this is happening?
thanks
Pavel
Everything works great! Thank you!
Hi all.
Unfortunately, an error occurred while executing IPAdapterUnifiedLoaderFaceID:
IP adapter model not found. Does anyone know a solution?
It’s complaining about not finding the ip adapter model. Can you confirm you have done the step below?
Install IPAdapter model
Download the Face ID Plus v2 IP-adapter model. Put the file in ComfyUI > models > ipadapter folder.
“E:\Comfy\ComfyUI_windows_portable\ComfyUI\models\ipadapter\ip-adapter-faceid-plusv2_sd15.bin” Yes, the model is loaded.
Mmm.. I just tested the workflow and it is working correctly. Have you installed all 3 model files? You should see three files loaded in the console output (The paths can be different)
INFO: Clip Vision model loaded from stable-diffusion-webui\models/clip_vision\CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors
INFO: IPAdapter model loaded from ComfyUI\models\ipadapter\ip-adapter-faceid_sd15.bin
INFO: LoRA model loaded from stable-diffusion-webui\models/Lora\ip-adapter-faceid_sd15_lora.safetensors
Even after doing a new install it can not find it. I installed Python 3.11.9
C:\Users\signu>.\python_embeded\python.exe –version
The system cannot find the path specified.
I re-installed py AND I GET THIOS NOW
C:\Users\signu>.\python_embeded\python.exe -m pip install .\insightface-0.7.3-cp311-cp311-win_amd64.whl
The system cannot find the path specified.
You may have missed this step: Open the File Explorer App. Navigate to the ComfyUI_windows_portable folder. In the address bar, type cmd and press Enter.
You should see C:\Users\…\ComfyUI_windows_portable> before running the pip install command.
I can not find the IPAdapterApplyFaceID i fine many other but not the IPAdapterApplyFaceID.
So i am not able to get this working missing two things the IPAdapterApplyFaceID and the Insight face all other are instaled.
You should be able to download the json file and drop it to comfyui. The workflow is updated to use IPAdapter unified loader. You need to use ComfyUI manager to install the missing nodes: Manager > Install missing custom nodes.
i get .\python_embeded\python.exe –version
The system cannot find the path specified.
ComfyUI workflow does not work. Probably because of recent changes IPAdapter. It will be great if you could update and provide a working one
Hi, updated.
Got this when I tried. Error on Unified Loader Box. May be some explanation of how workflow works ?
======================
Error occurred when executing IPAdapterUnifiedLoaderFaceID:
IPAdapter model not found.
File “C:\Users\satis\OneDrive\Documents\ComfyUI_windows_portable\ComfyUI\execution.py”, line 151, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\satis\OneDrive\Documents\ComfyUI_windows_portable\ComfyUI\execution.py”, line 81, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\satis\OneDrive\Documents\ComfyUI_windows_portable\ComfyUI\execution.py”, line 74, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “C:\Users\satis\OneDrive\Documents\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI_IPAdapter_plus\IPAdapterPlus.py”, line 468, in load_models
raise Exception(“IPAdapter model not found.”)
Looks like it couldn’t find the IP adapter model. It uses “ip-adapter-faceid-plusv2_sd15.bin”. Make sure you have it in your ip-adapters folder with exactly the same name.
Hello all,
I have the message: No module named ‘insightface’
I treid to install:
pip install insightface==0.7.3
but problem stays.
Any ideas?
Thanx a lot
If anybody has problem with insight. I found this solustion works:
Put there insightface-0.7.3-cp311-cp311-win_amd64.whl
( https://github.com/Gourieff/Assets/raw/main/Insightface/insightface-0.7.3-cp311-cp311-win_amd64.whl )
Create bat file:
@echo off
..\python_embeded\python.exe -m pip install insightface-0.7.3-cp311-cp311-win_amd64.whl
pause
I tried reinstalling everything. My first issue has been resolved. Now I am seeing this error.
————————
Error occurred when executing InsightFaceLoader:
module ‘google’ has no attribute ‘protobuf’
File “C:\Users\rajes\ComfyUI_windows_portable\ComfyUI\execution.py”, line 152, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
File “C:\Users\rajes\ComfyUI_windows_portable\ComfyUI\execution.py”, line 82, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
File “C:\Users\rajes\ComfyUI_windows_portable\ComfyUI\execution.py”, line 75, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
File “C:\Users\rajes\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI_IPAdapter_plus\IPAdapterPlus.py”, line 535, in load_insight_face
from insightface.app import FaceAnalysis
File “C:\Users\rajes\ComfyUI_windows_portable\python_embeded\lib\site-packages\insightface\__init__.py”, line 16, in
from . import model_zoo
File “C:\Users\rajes\ComfyUI_windows_portable\python_embeded\lib\site-packages\insightface\model_zoo\__init__.py”, line 1, in
from .model_zoo import get_model
File “C:\Users\rajes\ComfyUI_windows_portable\python_embeded\lib\site-packages\insightface\model_zoo\model_zoo.py”, line 11, in
from .arcface_onnx import *
File “C:\Users\rajes\ComfyUI_windows_portable\python_embeded\lib\site-packages\insightface\model_zoo\arcface_onnx.py”, line 10, in
import onnx
File “C:\Users\rajes\ComfyUI_windows_portable\python_embeded\lib\site-packages\onnx\__init__.py”, line 75, in
from onnx import serialization
File “C:\Users\rajes\ComfyUI_windows_portable\python_embeded\lib\site-packages\onnx\serialization.py”, line 22, in
_Proto = TypeVar(“_Proto”, bound=google.protobuf.message.Message)
Please help me fix this.
You can try running the bat file “update_comfyui_and_python_dependencies.bat” in the update folder.
Hi Andrew,
I followed the procedure as it is.
I get the following error.
—————————————————–
Prompt outputs failed validation.
IPAdapterModelLoader:
– Value not in list: ipadapter_file: ‘None’ not in []
——————————————————–
I am unable to update the ipadapter_file from null to the desired file in UI. I see that I have the file present at the correct location.
“C:\Users\XXX\ComfyUI_windows_portable\ComfyUI\models\ipadapter\ip-adapter-faceid-plusv2_sd15.bin”
How can I fix this issue?
Yes the location looks correct.
Try restarting comfyui completely.
If I’m understanding this correctly you aren’t actually making a LORA but instead something that acts similar for photos correct? I assume this is photomaker?
That’s correct, face via conditioning. Apparently this is a thing now with multiple techs to choose from. photomaker is nice but it’s not the first one. this is from a slightly older one.