
Stable Video 3D (SV3D) is a generative AI model that creates a 3D orbital view using a single image input. Stability AI released the model under a non-commercial use license.
Below is an example of an orbital view video based on the input image.


In this article, I will talk about
- How to run SV3D locally with ComfyUI
- How does SV3D work
Table of Contents
Software
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.
Alternative to SV3D
SV3D is not the only game in town for video generation with Stable Diffusion. You can also use the following methods.
- Stable Video Diffusion generates a short video clip with an input image. The video quality is quite good.
- TripoSR generates a 3D model from an input image. You can try the demo. The generation is very fast.
- AnimateDiff generates a short video clip with Stable Diffusion and a text prompt.
- Deforum generates a visually stunning video with text prompts and camera control settings.
SV3D is unique because it generates a spinning object with a single image input. The model can guess quite accurately how the object looks from different angles.
How to run SV3D on ComfyUI
The workflow takes about 16 GB of RAM on my PC to run. Yours may be different.
Step 1: Load the SV3D workflow
Download the Stable Video 3D ComfyUI workflow below.
Drag and drop it to ComfyUI to load the workflow.
Step 2: Install missing nodes
Every time you try to run a new workflow, you may need to do some or all of the following steps.
- Install ComfyUI Manager
- Install missing nodes
- Update everything
Install ComfyUI Manager
Install ComfyUI manager if you haven’t done so already. It provides an easy way to update ComfyUI and install missing nodes.
To install this custom node, go to the custom nodes folder in the PowerShell (Windows) or Terminal (Mac) App:
cd ComfyUI/custom_nodesInstall ComfyUI by cloning the repository under the custom_nodes folder.
git clone https://github.com/ltdrdata/ComfyUI-ManagerRestart ComfyUI completely. You should see a new Manager button appearing on the menu.
If you don’t see the Manager button, check the terminal for error messages. One common issue is GIT not installed. Installing it and repeat the steps should resolve the issue.
Install missing custom nodes
To install the custom nodes that are used by the workflow but you don’t have:
- Click Manager in the Menu.
- Click Install Missing custom Nodes.
- Restart ComfyUI completely.
Update everything
You can use ComfyUI manager to update custom nodes and ComfyUI itself.
- Click Manager in the Menu.
- Click Updates All. It may take a while to be done.
- Restart the ComfyUI and refresh the ComfyUI page.
Step 3: Download the SV3D model
Go to the Hugging Face page of the SV3D model. Log in or sign up. You must accept the user agreement to download the model.
Download the SV3D_p model and put it in the folder ComfyUI > models > checkpoints.
Step 4: Run the workflow
Upload an image without a background to the Load Image node.
You can use the test images below from the TripoSR demo.





Click Queue Prompt to run the workflow.
This is a more ambitious input image. It’s far from perfect, but still reasonable!


How does SV3D work
You can find the details of the model in the research article SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion.
SV3D Model
The SV3D model is based on the Stable Video Diffusion model, which generates video with multi-view consistency. SV3D takes advantage of the capability of the model to generate novel views, such as the back view of the input image.
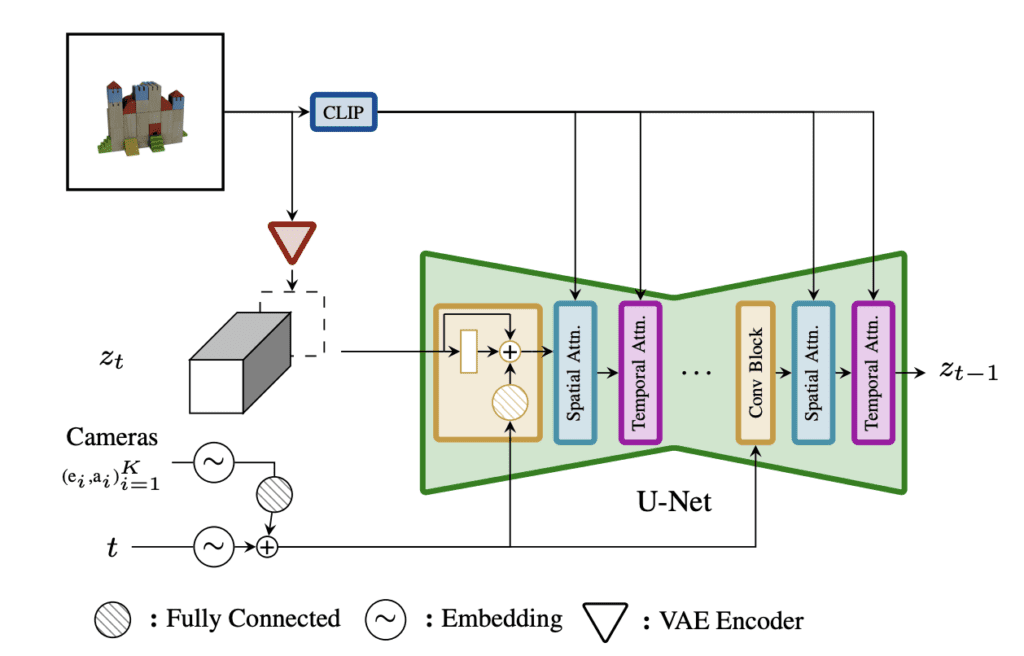
The model generates an orbital video of an object based on the input image. The input image is converted to a latent image using SVD’s VAE.
The noise predictor is conditioned with:
- The input image processed with CLIP Vision.
- The view angle of the canmera.
The series of images are denoised in a way similar to other Stable Diffusion models.
Training data
The model is trained with the synthesized 3D objects in the Objaverse dataset.
Pretrained models
All pretrained models are finetuned from the SVD model. Three models were trained.
- SVD-u (unconditioned): Only conditioned with the input image but unconditioned with the camera angle.
- SVD-c (conditioned): Conditionings with both the input image and the camera angle.
- SVD-p (progressive): First trained unconditioned with the camera angle, followed by dynamic orbits of camera pose.
The SVD-p is the best-performing model. So get the p model if you only want to download one!
Hi, Andrew. Congrats on your work.
About your latest email on Stable Diffusion. I am creating a graphic novel using AI and I used Mage with CivitAI trained models. The result was good, but I see that Mage is a little bit stalled, they are promising a new interface for ages and nothing so far. Do you think Leonardo would be a better choice? Thank you.
I don’t see them and cannot comment.