
Wan 2.1 Video is a series of open foundational video models. It supports a wide range of video-generation tasks. It can turn images or text descriptions into videos at 480p or 720p resolutions.
In this post:
- An overview of Wan 2.1 models
- How to use Wan 2.1 image-to-video in ComfyUI
- How to use Wan 2.1 text-to-video in ComfyUI
Table of Contents
Software
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.
Running on Google Colab
If you use my ComfyUI Colab notebook, you don’t need to install the model files. They will be downloaded automatically.
Select the WAN_2_1 models before starting the notebook.

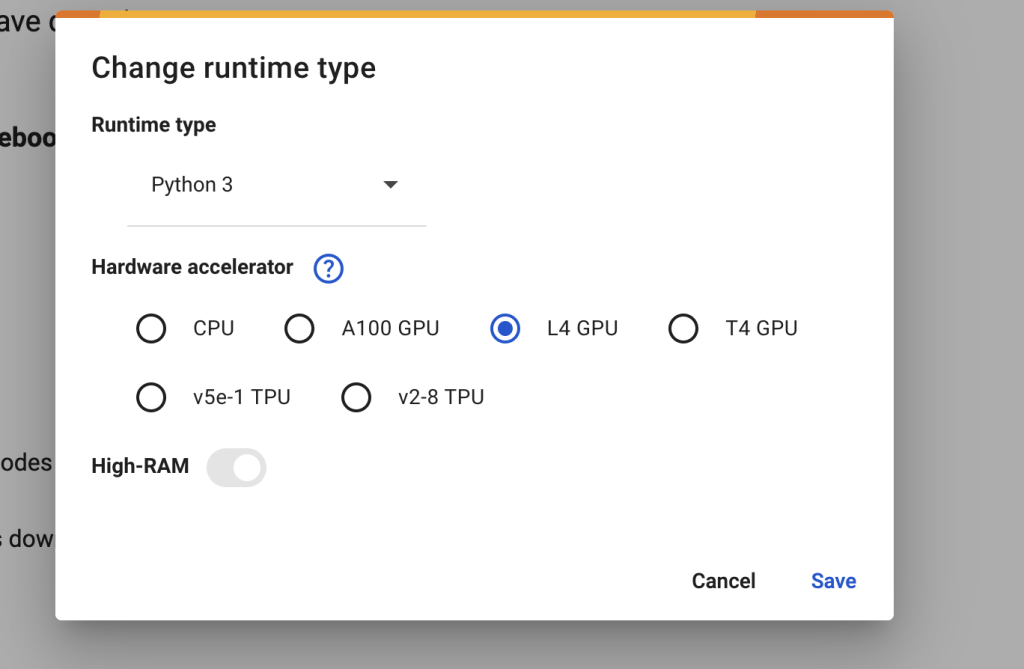
In the top menu, select Runtime > Change runtime type > L4 GPU. Save the settings.
Download a workflow JSON file from this tutorial and drop it to ComfyUI.
Wan 2.1 sample videos
Unsurprisingly, 720p videos are higher quality than 480p for both image-to-video and text-to-video. However, some 480p videos have glitch artifacts.
720p videos
480p videos
What are the Wan 2.1 models?
Released by Wan AI, the Wan 2.1 models are a collection of video models that can turn images or text descriptions into videos.
- Text-to-video 14B model: Supports both 480p and 720p
- Image-to-video 14B 720p model: Supports 720p
- Image-to-video 14B 480p model: Supports 480p
- Text-to-video 1.3B model: Supports 480p
The most interesting one is the image-to-video 720p model. We badly need a high-quality image-to-video model to use with a high-quality text-to-image video, such as Flux AI.
Model architecture
Not much technical information was released. I will update this section when they publish more.
Highlights
The bullet points below are taken from the Wan 2.1 GitHub page.
- State-of-the-art Performance. It is competitive to the best video models like Hunyuan Video.
- Supports consumer-grade GPUs: The smallest model T2V-1.3B requires only 8.19 GB VRAM, making it compatible with almost all GPUs.
- Multiple Tasks: supports text-to-video, image-to-video, video editing, text-to-image, and video-to-audio.
- Visual Text Generation: It can generate Chinese and English text.
- Powerful Video VAE: The Wan-VAE can encode and decode 1080p videos of any length while preserving temporal information, making it an ideal foundation for video and image generation.
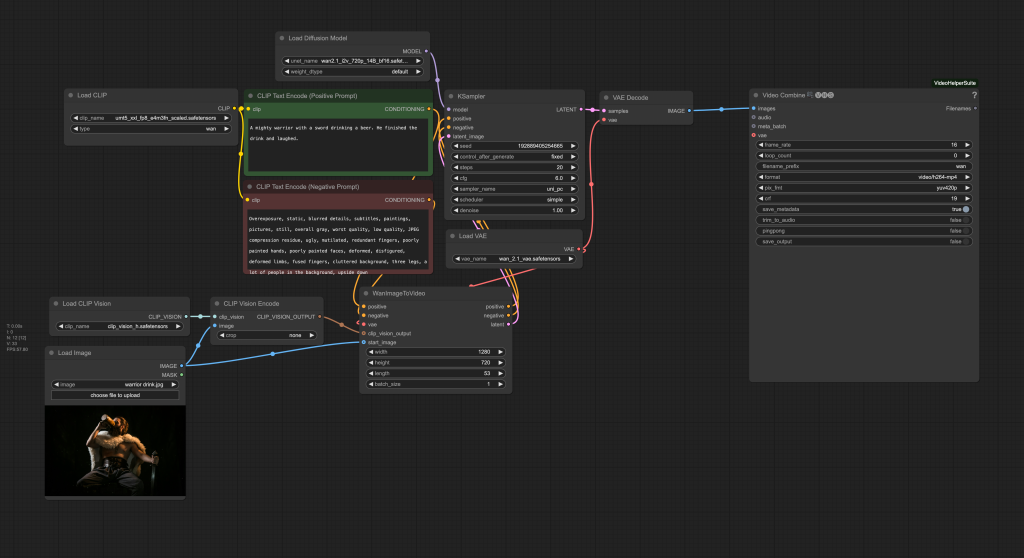
Wan 2.1 Image-to-video workflow
This workflow turns an image into a 2.3-second video with 720p resolution (1280 x 720 pixels) in the MP4 format. To use it, you must supply an image and a text prompt.
It takes 23 mins on my RTX4090 (24GB VRAM).
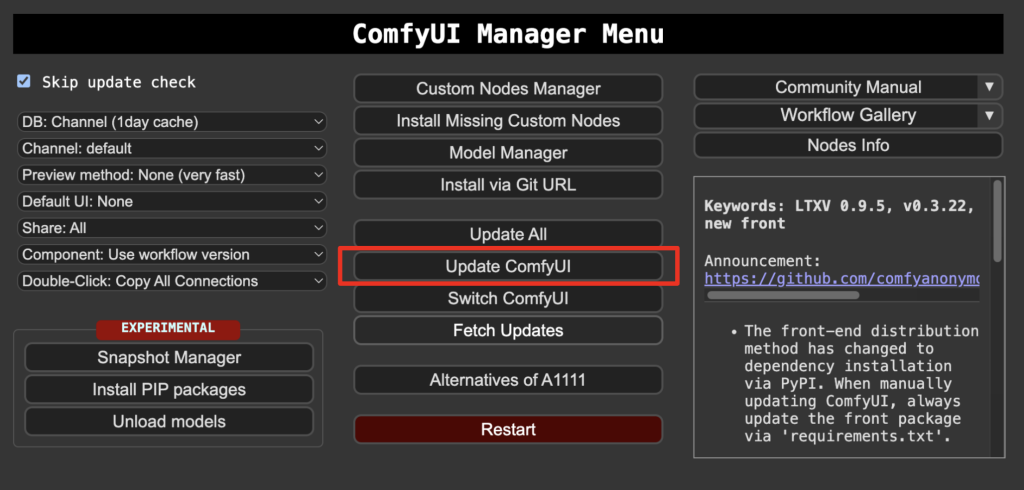
Step 1: Update ComfyUI
Before loading the workflow, make sure your ComfyUI is up-to-date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.

Select Update ComfyUI.
Restart ComfyUI.
Step 2: Download model files
Download the diffusion model wan2.1_i2v_720p_14B_fp8_e4m3fn.safetensors and put it in ComfyUI > models > diffusion_models.
Download the text encoder model umt5_xxl_fp8_e4m3fn_scaled.safetensors and put it in ComfyUI > models > text_encoders.
Download the CLIP vision model clip_vision_h.safetensors and put it in ComfyUI > models > clip_vision.
Download the Wan VAE model wan_2.1_vae.safetensors and put it in ComfyUI > models > vae.
Step 3: Load the Wan 2.1 img2vid workflow
Download the workflow JSON file below and drop it to ComfyUI to load.
Step 4: Install missing nodes
If you see red blocks, you don’t have the custom node that this workflow needs.
Click Manager > Install missing custom nodes and install the missing nodes.
Restart ComfyUI.
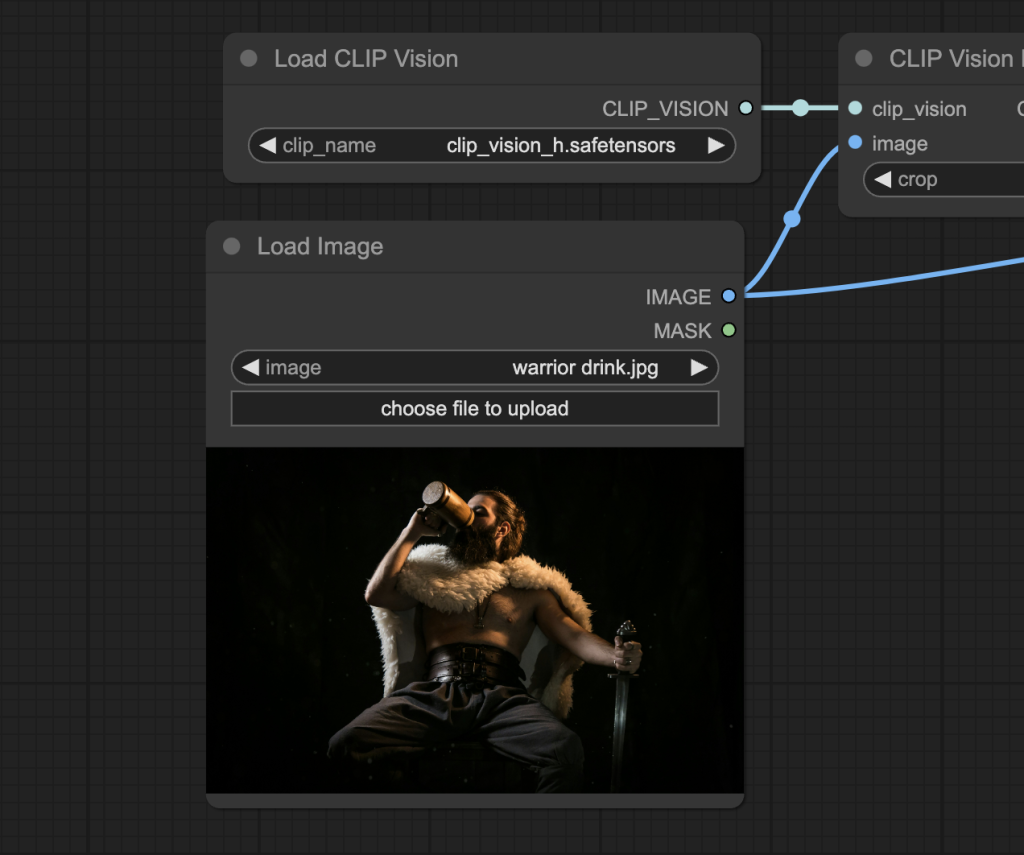
Step 5: Set the input image
Upload an image you wish to use as the video’s initial frame. You can download my test image for testing.
{kind=link}

Step 6: Revise the prompt
Revise the positive prompt to describe the video you want to generate. Some tips:
- Don’t just describe your input image. Describe what the later part of the video should do.
- Add action words, e.g., laugh, run, fight, etc.
- You can leave the boilerplate negative prompt unchanged.

Step 7: Generate the video
Click the Queue button to run the workflow.

You should get this video.
480p image-to-video workflow
You can use the workflow above to generate 480p videos (640×480 pixels).
Download the diffusion model wan2.1_i2v_480p_14B_bf16.safetensors and put it in ComfyUI > models > diffusion_models.
Set the video resolution to something close to 480p:
- Width: 848
- Height: 480
Wan 2.1 text-to-video workflow
This workflow turns a text description into a 2.3-second video with 720p resolution (1280 x 720 pixels) in the MP4 format.
Step 1: Update ComfyUI
Before loading the workflow, make sure your ComfyUI is up-to-date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.
Select Update ComfyUI.
Restart ComfyUI.
Step 2: Download model files
Download the diffusion model wan2.1_t2v_14B_fp8_e4m3fn.safetensors and put it in ComfyUI > models > diffusion_models.
Download the text encoder model umt5_xxl_fp8_e4m3fn_scaled.safetensors and put it in ComfyUI > models > text_encoders.
Download the CLIP vision model clip_vision_h.safetensors and put it in ComfyUI > models > clip_vision.
Download the Wan VAE model wan_2.1_vae.safetensors and put it in ComfyUI > models > vae.
Step 3: Load the Wan 2.1 txt2vid workflow
Download the workflow JSON file below and drop it to ComfyUI to load.
Step 4: Install missing nodes
If you see red blocks, you don’t have the custom node that this workflow needs.
Click Manager > Install missing custom nodes and install the missing nodes.
Restart ComfyUI.
Step 5: Revise the prompt
Revise the positive prompt to describe the video you want to generate.
Step 6: Generate the video
Click the Queue button to run the workflow.
You should get a video like this:
480p text-to-video workflow
Here you go. This workflow uses the same model files above.
Fast 480p text-to-video workflow
This workflow uses a smaller diffusion model.
Download the diffusion model wan2.1_t2v_1.3B_bf16.safetensors and put it in ComfyUI > models > diffusion_models.
The result is interesting… But it only takes a minute.
Reference
ComfyUI Blog: Wan2.1 Video Model Native Support in ComfyUI!
Model file page: Comfy-Org/Wan_2.1_ComfyUI_repackaged · Hugging Face
GitHub page: Wan-Video/Wan2.1: Wan: Open and Advanced Large-Scale Video Generative Models
Thank you for this! I was unable to get the Hunyuan image-to-video workflow working on my lower-end system (3060 12GB VRAM, 16GB RAM) but this Wan I2V works! I was even able to add a couple of Lora nodes and switch the VAE decode to use the tiled one.
I can only make low-res videos (limited to about 4 sec at 608×400) I’m using an fp8 version of the model, but it’s awesome to be able to create what I want as an image first and then make it into a video with motion loras.
Thanks for showing us this video model, Andrew. I’d say it rivals the quality of some commercial ones like Kling but I found it takes a very long time to generate content – nearly 2 hours on Colab L4 for a 4 min video at 720p. The 480p img2vid model was considerably quicker but still took about 40 mins for a 4 min video. The quality was clearly less but using an high quality, upscaled starting image helps with that.
Perhaps future versions will be quicker.
This is longer than I thought. I will publish a faster version with teacache.
That would be great. If you could do a teacache version of the Hunyuan workflow too, even better!
Thanks
Does the input image need to be same resolution as whatever model you run? Just the same aspect ratio? Yes, I see the crop center, but if you don’t use it will it scale it down? break? do weird things?
Only need to be the same aspect ratio. It will crop the image if the ratio is not the same.
hey, im in mimicpc and i dont know how to use wan2.1 because i allready put the workflow in comfyui and it shows me missing nodes then all something start with”Wan” i go to Install missing nodes and nothing appears in there? i tried also with github but it dosent show it couldnt install…why?
I don’t know, with the same seeds I could only get your last video. The rest are not even close.
I’m missing the WanImagetoVideo Node when uploading the workflow. Any solves?
Nevermind. I was using the portable program. I figured out all problems.
I had the same result too, WAN21 easy change all to animation.(