
Lumina Image 2.0 is an open-source AI model that generates images from text descriptions. It excels in artistic styles and adhering to the prompt. In this tutorial, I will cover:
- What Lumina Image 2.0 is.
- How to use Lumina Image 2.0 in ComfyUI.
- Image comparison between Lumina, Flux, and SDXL.
Table of Contents
Software
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.

What is Lumina Image 2.0?
Lumina Image 2.0 generates images in 1024×1024 resolution with 2.6B parameters. It leverages the Gemma-2-2B text encoder to process natural language prompts and employs the FLUX-VAE-16CH as its variational autoencoder for image compression.
Run Lumina Image 2.0 on ComfyUI
Step 1: Download the Lumina model
Download the Lumina 2.0 checkpoint model. Put the model file in the folder ComfyUI > models > checkpoints.
Step 2: Update ComfyUI
The easiest way to update ComfyUI is through the ComfyUI Manager. Click Manager > Update All.
Reload the ComfyUI page after the update.
Step 3: Load the Lumina 2.0 workflow
Download the Lumina Image 2.0 JSON workflow below.
Drop it to your ComfyUI.
Step 4: Run the workflow
Revise the prompt.
Run the workflow by clicking the Queue button.

You should get the image below.

Comparing Lumina Image 2.0 with Flux.1 Dev and SDXL
With a native resolution of 1024 x 1024, the outputs of the Lumina Image 2.0 model is comparable to the Flux.1 Dev and SDXL models. Let’s do a comparison to study its performance.
Realistic images with text rendering
The first test is generating realistic images with text, which the Flux model is very good at. I will use the following prompt (The text varies).
a portrait photo of a 25-year old beautiful woman, busy street street, smiling, holding a sign “XXXX”
Lumina (Text: Lumina Image 2.0):



SDXL (Text: SDXL vs Flux):



Flux.1 Dev (Text: SDXL vs Flux):



The Lumina model lags behind the Flux model in text rendering and realistic image generation. The texts are not correct. The images are too polished to be realistic. Its quality is slightly worse than the SDXL model. Interestingly, Lumina generates almost the same image, indicating issues in the diversity of training images.
Prompt adherence
Prompt adherence is the ability of the model to follow the prompt closely.
I will challenge the models in the following areas:
- Controlling poses
- Object compositions
Controlling poses
Most people use AI models to generate… people. Let’s test the models’ ability to render correct poses.
Photo of a woman with pink hair raising her left hand above her head. Stand with one leg on a hardwood floor.
Lumina:



SDXL:



Flux.1 Dev:


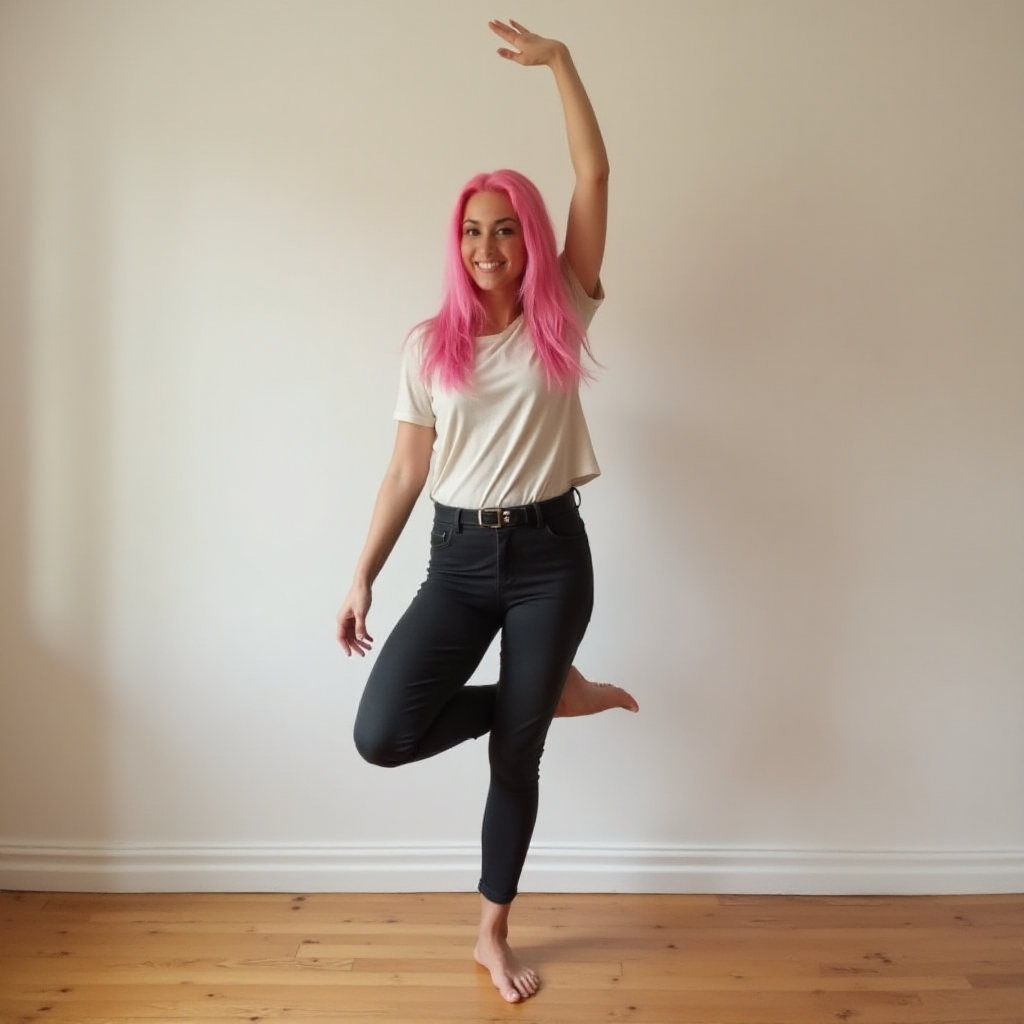
Again, Flux generates the most accurate images. Lumina’s images are slightly more correct than SDXL’s, but one leg is curiously missing…
Object composition
The test of objection composition is to see how well the model follows the object placement in the prompt.
Prompt:
Still life painting of a skull above a book, with an orange on the right and an apple on the left
Lumina:



SDXL:



Flux.1 Dev:



Lumina’s object composition is pretty good, only slightly worse than Flux. It is better than SDXL.
Hands
Rendering hands has long been a weakness in Stable Diffusion AI image models. Flux is a significant improvement. Would Lumina do better?
photo of open palms, detailed fingers, beach, sea
Lumina:



SDXL:



Flux:



While not as good as Flux, Lumina generates better hands than SDXL.
Faces
This is a common task: Generating a big face.
photo of a 85 year old Syrian man, detailed face, eyes, lips, nose, hair, realistic skin tone, freckles, skin texture
Lumina:



SDXL:



Flux:



Unfortunately, Lumina produces the least realistic images of the face.
Styles
I will use prompts from the SDXL style reference to test Lumina’s ability to generate styles.
Expressionist style
expressionist woman. raw, emotional, dynamic, distortion for emotional effect, vibrant, use of unusual colors, detailed
Lumina:



SDXL:



Flux:



The art style from Lumina is surprisingly decent! The interpretation of the prompt is different from the SDXL model, but both are correct.
Pixel art
pixel art of a dragon. low-res, blocky, pixel art style, 8-bit graphics, pixelated, 90s video game
Lumina:



SDXL:



Flux:



Another accurate art style from Lumina! It’s even more precise than SDXL (I said low res). Flux is only good at realistic styles.
Ad Poster
advertising poster style sneaker. Professional, modern, product-focused, commercial, eye-catching, highly detailed
Lumina:



SDXL:



Flux:



Lumina produces decent poster images, but the excessive text ruins them.
Conclusions
Lumina is good at generating artistic styles and following the prompt well. The base model generates subpar realistic images, but, as in the case of Stable Diffusion 1.5, it can likely be improved with finetuning.
Reference
- ComfyUI Blog: Lumina Image 2.0 Native Support in ComfyUI
- GitHub page: Alpha-VLLM/Lumina-Image-2.0
- ComfyUI’s official example workflow
@grow a garden I like this post!!
Thanks for another exciting article Andrew.
I just gave the workflow a try on Ubuntu with ComfyUI 0.3.9; the server complained “Could not detect model type of: …/ComfyUI/models/checkpoints/FLUX/lumina_2.safetensors”. The res_multistep sampler wasn’t available either. Any thoughts gratefully received!
You are welcome! Your comfyui is too old and needs to be updated.
Do you know if Lora models developed for Flux are compatible with the model?
Not compatible.