
Stable Diffusion 3 is announced, followed by a research paper detailing the model. The model is not publicly available yet, but you can join the waitlist to get in line for an early preview. I will add the usage guide to this article once they are available.
But in this article, we will take a closer look at
- What is Stable Diffusion 3
- The improvements in Stable Diffusion 3
- Model changes
- Sample images
Table of Contents
What is the Stable Diffusion 3 model?
Stable Diffusion 3 is the latest generation of text-to-image AI models to be released by Stability AI.
It is not a single model but a family of models ranging from 800M to 8B parameters. In other words, the smallest model is a bit smaller than Stable Diffusion 1.5 (1B), and the largest model is a bit bigger than the Stable Diffusion XL model (6.6B for base + refiner).
The product design follows the industrial trend of large language models, where Google, Meta, and Antropic have released foundation models of different sizes for different use cases.
Stable Diffusion 3 allows commercial use, but it is not free. You must join their membership program for a fee. (Currently quite modest for small businesses)
Improvements
So what’s the big deal with Stable Diffusion 3? Here are some expected improvements.
Better text generation
Text rendering has long been a weakness for Stable Diffusion. Stable Diffusion 1.5 is really bad at it.
We see significant improvements in Stable Diffusion XL and Stable Cascade models but they are still hit or miss and need significant cherry-picking. And it is hopeless for long sentences.
See what SD 3 can generate:

From the sample images, we see some impressive long sentences with good font styles. I definitely think it is an improvement because we can never generate those images with SDXL or Stable Cascade.
Better prompt following
An outstanding issue with SDXL and Stable Cascade is that they do not follow the prompts as well as DALLE 3. One innovation of DALLE 3 is using highly accurate image captions in training to learn to follow prompts well.
I previously speculated that a new version of Stable Diffusion could use the same method to improve the model. Lo and behold, they did that in SD 3.
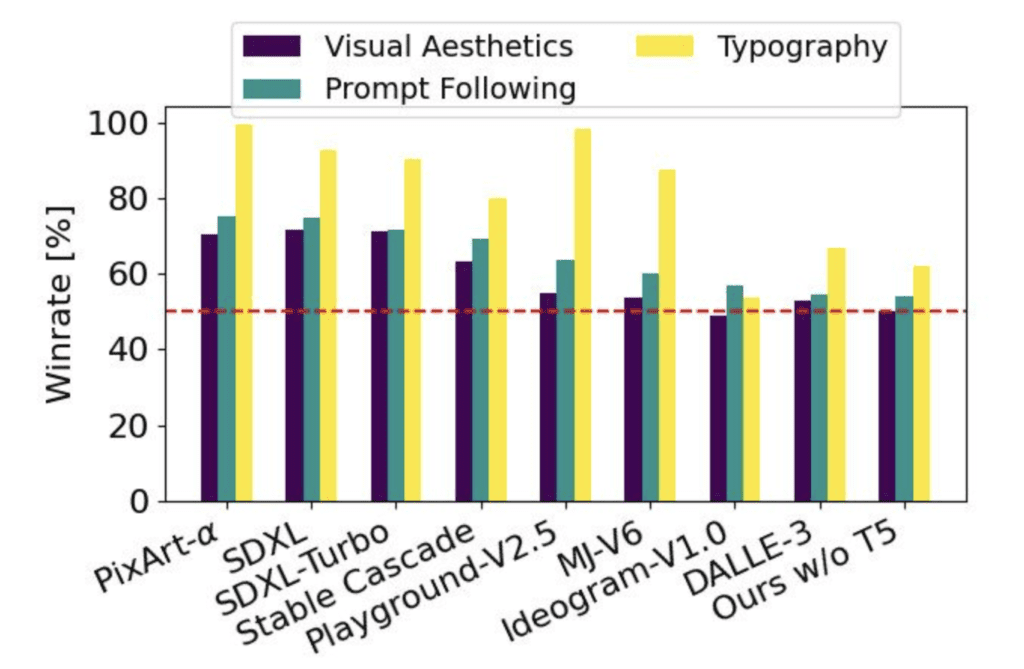
Stable Diffusion 3 should be at least as good as DALLE 3 in the following prompts. This is going to be exciting.


Speed and deployment
You will be able to run the largest SD3 locally if you have a video card with 24 GB RAM. The requirement will likely come down when it is released, and people will start to do all kinds of optimizations on consumer PCs.
The initial benchmark is 34 seconds for a 1024×1024 image on the RTX 4090 video card (50 steps). We should have a lot of room for improvement.

Safety…
Similar to newer Stable Diffusion models, Stable Diffusion 3 is likely to generate SFW images only.
In addition, Artists who did not want their work to be in the model could opt out. While this reduces the styles available for mix-and-match, it should make the model less prone to misuse.
I’m not sure what they are doing with Deep Fake. Fictitious images of celebrities arguably do the most harm in spreading misinformation in the age of fast media consumption. DALLE 3 stays out of trouble by being not so good at generating photorealistic images. Stable Diffusion has been good at photorealistic images. I hope they won’t steer away from it.

What’s new in Stable Diffusion 3 model
Noise predictor
A notable change in Stable Diffusion 3 is the departure from the U-Net noise predictor architecture used in Stable Diffuson 1 and 2.
Stable Diffusion 3 uses a repeating stack of Diffusion Transformers. The benefit is similar to using transformers in large language models: You get predictable performance improvement as you increase the model size.
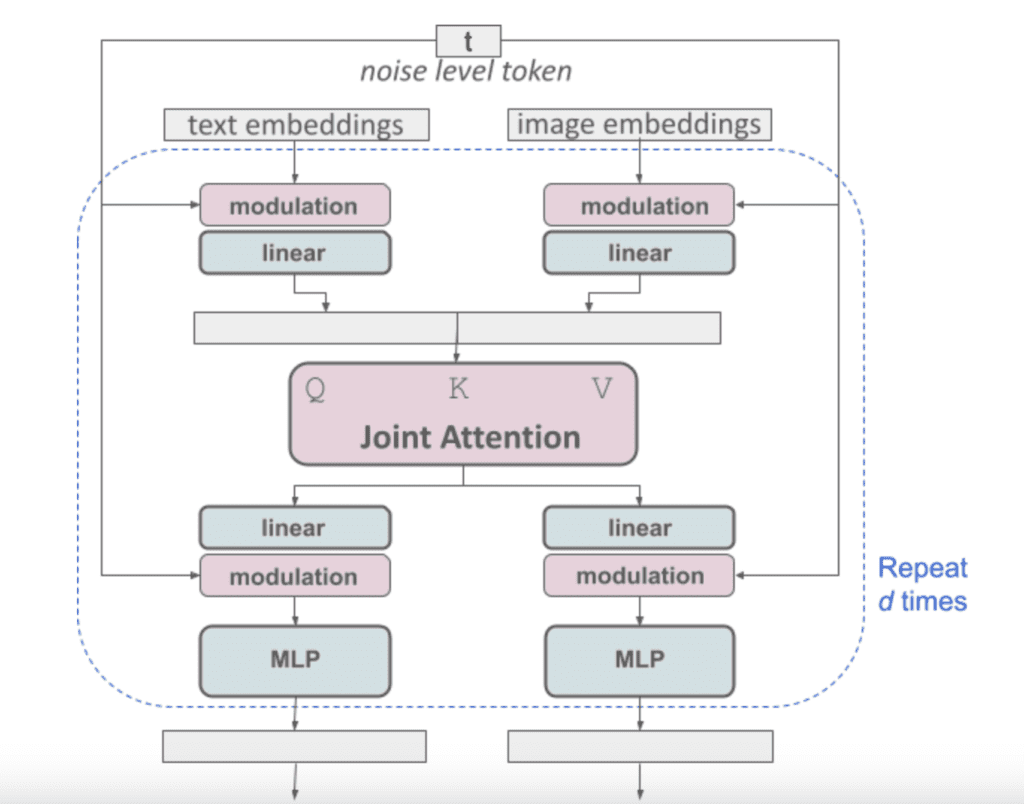
The block has an interesting structure that puts the text prompt and the latent image on the same footing. Looks like this architecture is well-positioned to add multimodal conditionings like image prompts.
Sampling
The Stability team has spent considerable effort studying sampling to make it fast and high-quality. Stable Diffusion 3 uses Retified Flow sampling. Basically, it is a straight path from noise to clear image—the fastest way to get there.
The team also found a noise schedule that sampled the middle part of the path more produced higher-quality images.
Well, looks like the sampling is going to be completely different. But from our experience, some existing samplers likely work well enough.
Text encoders
Stable Diffusion 1 uses 1 text encoder (CLIP), while Stable Diffusion XL uses 2 encoders (CLIP and OpenCLIP).
Guess what? Stable Diffusion 3 uses 3 encoders!
- OpenAI’s CLIP L/14
- OpenCLIP bigG/14
- T5-v1.1-XXL
The last one is pretty big and can be dropped if you are not generating text.
Better captions
One thing that DALLE 3 did was use highly accurate captions in training. That’s why it follows the prompt so well.
Stable Diffusion 3 also did that. You can expect good prompt-following like DALLE 3.
Reference
- Stable Diffusion 3 — Stability AI
- Stable Diffusion 3: Research Paper — Stability AI
- Scalable Diffusion Models with Transformers – Diffusion transformer architecture that SD 3 used.
- Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow – Rectified Flow sampling.
- Flow Matching for Generative Modeling – Flow matching.
I have tried 2 of the SD3M models for 3 days now and it is unfortunately a deception, there should be something broken in the checkpoint logic, if I ask on a street in Los Angeles the palm trees are not on the ground but floating or on the balconies, and not a single person on the street is anatomically correct. If I ask for a crowded market street in the morning, I have a photo of the back of a street vendor… I’m sorry to say that apart from some beach photos, all the other photos contained far too many hallucinations and distortions…. some people even blown into puzzles pieces -_-
It is quite an unfinished product. To be fair, they called it beta but we haven’t seen a beta that bad lately…
I do think it has potential, just needs to be finetuned.
https://stable-diffusion-art.com/stable-diffusion-3-local/
wow I can’t wait!!! GO GO GO
Dead on arrival.
Even if you are not going to use for nsfw images most of people dev’ing tools, reporting bugs, doing fine-tuning and such are, most of the userbase will stay on sdxl
Also, 24 vram without even using control nets? Damn
Most people do not use the refiner with current SOTA fine-tuned models. So you should be comparing SD3’s 8B parameters to SDXL base’s 3.5B.
That’s more than twice the size, which means that the model is way more powerful. But it also means that it will require twice as much VRAM to use.
yes that’s another way to look at it
Censorship will be their downfall. Misuse is something that can’t be entirely avoided and at the end of the day it is always an individual’s intention that turns a tool into a weapon. Preemptively punishing everyone by limiting its capabilities is a short-sighted move. Using that argument would also justify forbidding pen and paper as people have written smut and drawn porn before. While at it, why not cut out reading and writing entirely out of school systems, so the next generations will be safe illiterates. Ignorance is bliss, I’ve heard.
Completed agree. This a new art form. Imagine if a painter or a writer could never produce erotic sentences or images… that’s censorship and banning of free speech, which great for autocratic or fascist societies, but in a democratic society it is death of free thinking. It is also eventually the death of the technology itself.
The death of free thought. Hong Kong is a good example
👍👍
A bit like when they used the bad people that were on the internet twenty years ago, when it was a little bit wild west out there, to justify controlling everything.
Now they arrest little old grannies for a Facebook post that offended someone, while people on Instagram trade children for sex.
Call me crazy, but I’m not seeing an improvement there.
I agree. The Ottoman empire banned printing for three centuries, with dire consequences and that resulted in their decline. And the Church was also opposed printing and censored books in its Index Librorum Prohibitorum until the 20th century.
The ridiculously high guardrails on AI art prevent artists from expressing all but the most banal ideas. If you want images of sorcerers, robot mice or cyberpunk heroines than you should have no complaints. But I don’t see why the companies behind AI image generation should spend billions on something that is little more than an admittedly amusing toy.
I suppose the reason for these high guardrails is what they imagine to be the bottom line. Big tech don’t want to be sued for the images created on their platforms. I can’t see how they could be held any more liable for those images than Nikon or Cannon could be held liable for pictures taken with their cameras or Microsoft could be held liable for documents produced on Word.
👍
CAN’T WAIT!!!!!
I like stable diffusion and I have opted in for the SD3 waitlist from their blog post last month. I use their APi alot for my app and it’s now available on Amazon appstore and it’s wonderful 👍. Just check what you can create with the app.
Do you also know that Stability AI has an Image-to-video model. You may want to install the app on your android phone to see it in action.
I combined my own model with Stable Diffusion to get a remarkable video generation result on the app. You can try it out and see for yourself too.
Create animations for free with GlaucaAI app to tell a story.
Convert your image to animated video using AI for free. Search for “GlaucaAI” app for Android on Amazon appstore now!!!
Or visit the following link to enjoy free text-to-image & video generation using AI:
https://www.amazon.com/dp/B0CVW52TTY/ref=apps_sf_sta
Nice!
One big issue with Dall-E3 is, that the software has no idea about perspektive and space. It even doesn‘t know the meaning of „left / right“ in prompts, and you can‘t work further on details of your image (no inpainting, even no accurate regenaration possible with the same seed).
I ran there a lot of tests and found that (as often) the advertising for Dall-E is very misleading and overpromising… but for quick first drafts it is okay.
So perspective adjustments (point of view a bit higher or 1m towards left without loosing the „scene“) are right now missing. Maybe something coming in SD3?
They optimized SD3 with metrics that include those derived from visual question answering. Those systems can score compositional accuracy. I expect it will be improved.
The thing is, it didn’t use to be like that. The advertisement was correct at the start. When Dall-E 3 first came out, it was much better and much accurate. They lobotomized it for ‘safety’ in time and now we have the shell of it.
You mentioned, artists can now easily opt out from training, but it is still the same tedious process where you have to upload each individual image and manually search (it takes weeks for my portfolio of two decades). Or has anything changed?
I would expect to just enter my name and website and automatically they compare and take it out.
Although I‘m working and learning AI to keep pace with latest developments, I have to say this way of building data bases is still unbeleavable and beyond any fairness for artists. None of my artist friends would say something different.
But of course Stable Diffusion has way better politics than Midjourney, who block any kind of opt-out, privacy or transparency.
Thanks!