
Hunyuan Video is a local video model which turns a text description into a video. But what if you want to turn an image into a video? You need an image-to-video mdoel but Hunyuan has not released one (that would be game-changing). For now, you can use the Image-Prompt to Video (IP2V) workflow to achieve a similar effect.
This workflow converts an image and a prompt to a video. For example, you can give a background image, add a person with the prompt, and generate a video like the one below.

Table of Contents
Software
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.
How does it work?
This Hunyuan IP2V workflow uses the Hunyuan Video text-to-image model. How does it use the image? Hunyuan preprocesses the prompt using a Large Language and Vision Assistant (LLaVA) model, which reads text and images. This workflow taps into the unused power of Hunyuan’s text encoder to read an image to supplement the prompt.
Difference between img2vid and IP2V
An image-to-video workflow uses the input image as the first frame of the video. The image-prompt-to-video workflow uses an image as part of the prompt. It uses the image concept but does not use it as the first frame.
Use cases
Let’s test the Hunyuan IP2V workflow to see what it is good at.
Use an Image as the background
Let’s use the following image of a tunnel as the background and add a person to the video with the prompt.
Prompt:
A fashionable beautiful woman with long blonde hair, black short skirt, white blouse, high heel, walking towards the camera, <image>, camera zooming in.
Note that you need to insert the image token <image> to the prompt to specify where you want the image prompt to be inserted.
Here’s the output video.
The Hunyuan IP2V workflow does a good job of generating a person walking in a tunnel. I did not mention the tunnel in the prompt. The workflow uses the visual LLM to parse and put the background image into the video.
You may have noticed that the tunnels in the image and the video look alike but not the same. This is an essential point in mastering the IP2V workflow. The visual LLM reads the image and converts it to the image tokens. They describe the scene and, in turn, influence the video. Unlike the IP-adapter, it does not replicate the image in the video.
Animate an image
Hunyuan Video is an excellent tool for content creators. Its exceptional video quality has great potential for generating B-rolls, the supplementary footage to the main video.
Royalty-free B roll footage exists. You can find them on royalty-free video sites. But they are limited compared to royalty-free images. Why not use the Hunyuan IP2V workflow to animate a royalty-free image and make a unique B-roll?
Suppose you are making a video about financial planning. The following image is an excellent fit for a B-roll.

Use this image as the input and only the image token as the text prompt.
<image>
You get a B roll!
Step-by-step guide
The following instructions are for ComfyUI on your local computer. (Windows or Linux).
If you use my ComfyUI Colab notebook: You don’t need to download the models (steps 1 and 2). Select the HunyuanVideoWrapper and VideoHelperSuite custom nodes (See image below) when starting the notebook. Use an L4 runtime type (This workflow needs 20GB VRAM). Starts from step 3.

Step 0: Update ComfyUI
Before loading the workflow, make sure your ComfyUI is up-to-date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.

Select Update ComfyUI.
Restart ComfyUI.
Step 1: Download video model
Download the hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors and put it in ComfyUI > models > diffusion_models.
Step 2: Download VAE
Download hunyuan_video_vae_bf16.safetensors.
This VAE file differs from the one released by ComfyUI and is used in the text-to-video tutorial. Rename it to hunyuan_video_vae_bf16-kj.safetensors
Put it in ComfyUI > models > vae.
Step 3: Load workflow
Download the Hunyuan video workflow JSON file below.
Drop it to ComfyUI.
Step 4: Install missing nodes
If you see red blocks, you don’t have the custom node that this workflow needs.
Click Manager > Install missing custom nodes and install the missing nodes.
Restart ComfyUI.
Step 5: Run the workflow
Upload the following image to the Load Image node.
{kind=link}
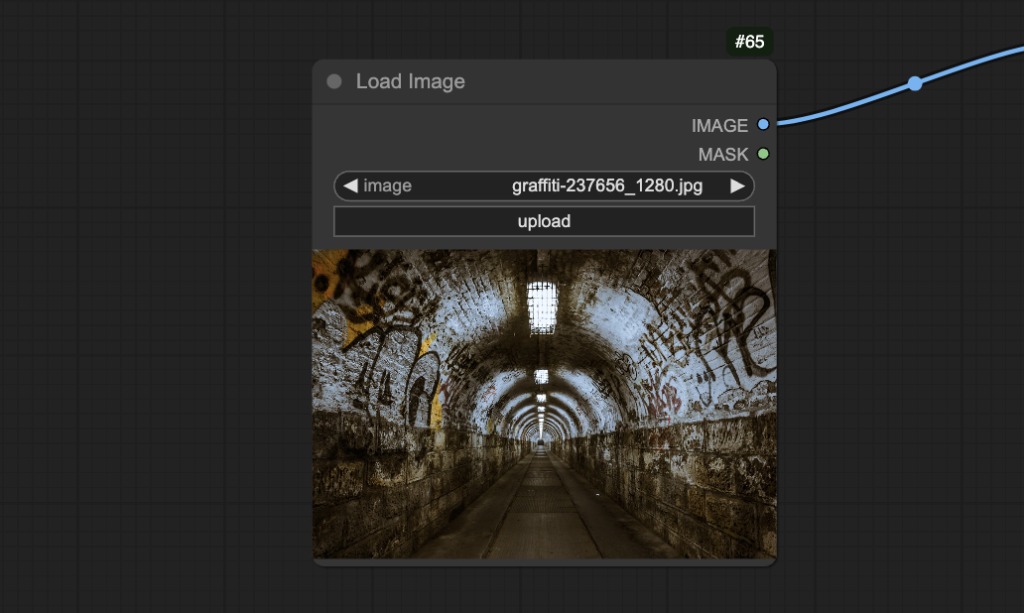
Click the Queue button to generate the video.
Running the workflow for the first time takes time because it will download some model files.
Tips: You can also speed up video generation with TeaCache.
Adjusting the image prompt
Downsampling image tokens
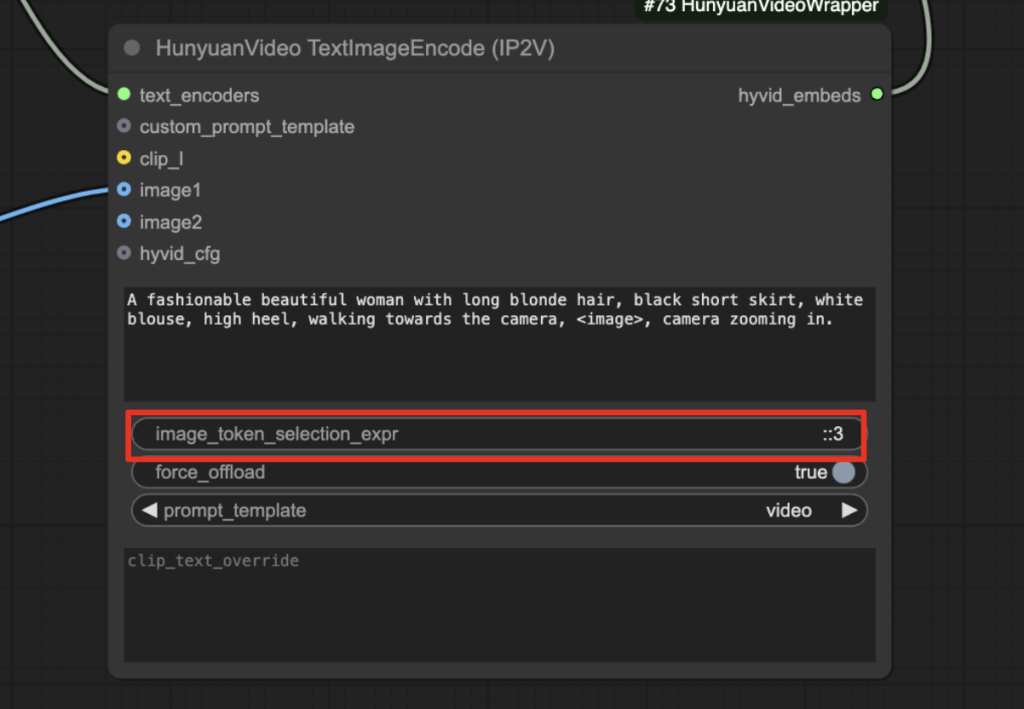
How much the image should influence the video is controlled by image_token_selection_expr. A value ::4 downsamples the image tokens so that only one out of four is used. Use a higher value to reduce the influence of the image, e.g. ::8 or ::16.
Increase the downsampling factor to ::16 changes the background to a outdoor torn building with graffiti. The tunnel becomes a similar hallway. The woman is controlled by the prompt so she’s still wearing the same outfit.
Increasing the downsampling to ::256 eliminates the tunnel pathway. She’s walking in an open space in a torn building, but the graffiti is still everywhere.
Other options for passing the image tokens
The llava-llama-3 model has 576 image tokens. Instead of downsampling, you can experiment with passing only a portion of the tokens.
:128– First 128 tokens.-128:– Last 128 tokens.:128, -128:– First 128 tokens and last 128 tokens.
Hello Andrew,
I already downgraded the transformers version but i still having error during the process:
Expanding inputs for image tokens in LLaVa should be done in processing. Please add `patch_size` and `vision_feature_select_strategy` to the model’s processing config or set directly with `processor.patch_size = {{patch_size}}` and processor.vision_feature_select_strategy = {{vision_feature_select_strategy}}`. Using processors without these attributes in the config is deprecated and will throw an error in v4.50.
Expanding inputs for image tokens in LLaVa should be done in processing. Please add `patch_size` and `vision_feature_select_strategy` to the model’s processing config or set directly with `processor.patch_size = {{patch_size}}` and processor.vision_feature_select_strategy = {{vision_feature_select_strategy}}`. Using processors without these attributes in the config is deprecated and will throw an error in v4.50.
It sends this message and the process is still running forever so i have to stop it, any clue about this?
Thanks in advance
Thank you Andrew for your guidance tools. I followed them and they are helpfull structured and easy to follow and really worked.
Getting the following error on M3 Max Macbook Pro. Already did the transformers downgrade.
HyVideoSampler
MPS device does not support linear for non-float weights
I don’t think the model works on mac.
Hello wondering if it s normal that it takes that long to generate, for a 240×240 resolution and only 20steps it takes me about 20/30mns to generate, I m using a 4080rtx with 32gb ram
It should be much faster. It’s likely that your VRAM maxed out.
Hi Andrew, more Comfy video issues. I’m getting multiple errors with the VAE loader using the Colab notebook, having installed the Hunyuan model. I renamed the VAE as you suggested but that didn’t help.
You may have used the VAE from the ComfyUI org. Please download the one on the page and rename accordingly. They are different.
Thanks, Andrew, that cured that problem. I also installed the video model in the unet folder and selected it.
But I’m now getting an error in the TextImageEncode node:
!!! Exception during processing !!! unsupported operand type(s) for //: ‘int’ and ‘NoneType’
Traceback (most recent call last):
File “/content/ComfyUI/execution.py”, line 327, in execute
output_data, output_ui, has_subgraph = get_output_data(obj, input_data_all, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/content/ComfyUI/execution.py”, line 202, in get_output_data
return_values = _map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/content/ComfyUI/execution.py”, line 174, in _map_node_over_list
process_inputs(input_dict, i)
File “/content/ComfyUI/execution.py”, line 163, in process_inputs
results.append(getattr(obj, func)(**inputs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/content/ComfyUI/custom_nodes/comfyui-hunyuanvideowrapper/nodes.py”, line 884, in process
prompt_embeds, negative_prompt_embeds, attention_mask, negative_attention_mask = encode_prompt(self,
^^^^^^^^^^^^^^^^^^^
File “/content/ComfyUI/custom_nodes/comfyui-hunyuanvideowrapper/nodes.py”, line 809, in encode_prompt
text_inputs = text_encoder.text2tokens(prompt,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/content/ComfyUI/custom_nodes/comfyui-hunyuanvideowrapper/hyvideo/text_encoder/__init__.py”, line 253, in text2tokens
text_tokens = self.processor(
^^^^^^^^^^^^^^^
File “/usr/local/lib/python3.11/dist-packages/transformers/models/llava/processing_llava.py”, line 160, in __call__
num_image_tokens = (height // self.patch_size) * (
~~~~~~~^^~~~~~~~~~~~~~~~~
TypeError: unsupported operand type(s) for //: ‘int’ and ‘NoneType’
I didn’t touch the node before running the workflow and this happened if I started the notebook either with or without ticking Hunyuan so I guess it’s not the downloaded models that are the problem?
I see this is the same issue that Bizaro had on a local installation. Is there also a fix for Colab?
It is fixed.
Thanks, Andrew.
I was able to generate up to 81 frames, about 3 secs, before I ran out of memory on the L4 GPU. Have you/others managed longer than that?
The model seems to give realistic movement and as you indicated, it is adaptable depending on how much of the background image is dialled in. But it’s hard to test with such a short clip how well it follows the prompt with motion.
Longer requires more memory. Or you can reduce the video resolution.
You say it’s fixed but I still get the same error following the tutorial. How did you fix it?
Fixed on 2/12. You should see the HunyuanVideoWrapper selection box. Use it.
Post the error message if you still see it.
Error:
Traceback (most recent call last):
File “H:\ComfyUI_windows_portable 1\ComfyUI\execution.py”, line 327, in execute
output_data, output_ui, has_subgraph = get_output_data(obj, input_data_all, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “H:\ComfyUI_windows_portable 1\ComfyUI\execution.py”, line 202, in get_output_data
return_values = _map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “H:\ComfyUI_windows_portable 1\ComfyUI\execution.py”, line 174, in _map_node_over_list
process_inputs(input_dict, i)
File “H:\ComfyUI_windows_portable 1\ComfyUI\execution.py”, line 163, in process_inputs
results.append(getattr(obj, func)(**inputs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “H:\ComfyUI_windows_portable 1\ComfyUI\custom_nodes\comfyui-hunyuanvideowrapper\nodes.py”, line 684, in loadmodel text_encoder = TextEncoder(
^^^^^^^^^^^^
File “H:\ComfyUI_windows_portable 1\ComfyUI\custom_nodes\comfyui-hunyuanvideowrapper\hyvideo\text_encoder\__init__.py”, line 167, in __init__
self.model, self.model_path = load_text_encoder(
^^^^^^^^^^^^^^^^^^
File “H:\ComfyUI_windows_portable 1\ComfyUI\custom_nodes\comfyui-hunyuanvideowrapper\hyvideo\text_encoder\__init__.py”, line 64, in load_text_encoder
text_encoder = text_encoder.to(device)
^^^^^^^^^^^^^^^^^^^^^^^
File “H:\ComfyUI_windows_portable 1\python_embeded\Lib\site-packages\transformers\modeling_utils.py”, line 3162, in to return super().to(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “H:\ComfyUI_windows_portable 1\python_embeded\Lib\site-packages\torch\nn\modules\module.py”, line 1343, in to
return self._apply(convert)
^^^^^^^^^^^^^^^^^^^^
File “H:\ComfyUI_windows_portable 1\python_embeded\Lib\site-packages\torch\nn\modules\module.py”, line 903, in _apply
module._apply(fn)
File “H:\ComfyUI_windows_portable 1\python_embeded\Lib\site-packages\torch\nn\modules\module.py”, line 903, in _apply
module._apply(fn)
File “H:\ComfyUI_windows_portable 1\python_embeded\Lib\site-packages\torch\nn\modules\module.py”, line 903, in _apply
module._apply(fn)
[Previous line repeated 3 more times]
File “H:\ComfyUI_windows_portable 1\python_embeded\Lib\site-packages\torch\nn\modules\module.py”, line 930, in _apply
param_applied = fn(param)
^^^^^^^^^
File “H:\ComfyUI_windows_portable 1\python_embeded\Lib\site-packages\torch\nn\modules\module.py”, line 1329, in convert
return t.to(
^^^^^
torch.OutOfMemoryError: Allocation on device
Got an OOM, unloading all loaded models.
Prompt executed in 28.55 seconds
got prompt
Loading text encoder model (clipL) from: H:\ComfyUI_windows_portable 1\ComfyUI\models\clip\clip-vit-large-patch14
Text encoder to dtype: torch.float16
Loading tokenizer (clipL) from: H:\ComfyUI_windows_portable 1\ComfyUI\models\clip\clip-vit-large-patch14
Loading text encoder model (vlm) from: H:\ComfyUI_windows_portable 1\ComfyUI\models\LLM\llava-llama-3-8b-v1_1-transformers
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████| 4/4 [00:04<00:00, 1.22s/it]
Text encoder to dtype: torch.bfloat16
Loading tokenizer (vlm) from: H:\ComfyUI_windows_portable 1\ComfyUI\models\LLM\llava-llama-3-8b-v1_1-transformers
Unused or unrecognized kwargs: device.
!!! Exception during processing !!! unsupported operand type(s) for //: 'int' and 'NoneType'
Traceback (most recent call last):
File "H:\ComfyUI_windows_portable 1\ComfyUI\execution.py", line 327, in execute
output_data, output_ui, has_subgraph = get_output_data(obj, input_data_all, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\ComfyUI_windows_portable 1\ComfyUI\execution.py", line 202, in get_output_data
return_values = _map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\ComfyUI_windows_portable 1\ComfyUI\execution.py", line 174, in _map_node_over_list
process_inputs(input_dict, i)
File "H:\ComfyUI_windows_portable 1\ComfyUI\execution.py", line 163, in process_inputs
results.append(getattr(obj, func)(**inputs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\ComfyUI_windows_portable 1\ComfyUI\custom_nodes\comfyui-hunyuanvideowrapper\nodes.py", line 884, in process
prompt_embeds, negative_prompt_embeds, attention_mask, negative_attention_mask = encode_prompt(self,
^^^^^^^^^^^^^^^^^^^
File "H:\ComfyUI_windows_portable 1\ComfyUI\custom_nodes\comfyui-hunyuanvideowrapper\nodes.py", line 809, in encode_prompt
text_inputs = text_encoder.text2tokens(prompt,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "H:\ComfyUI_windows_portable 1\ComfyUI\custom_nodes\comfyui-hunyuanvideowrapper\hyvideo\text_encoder\__init__.py", line 253, in text2tokens
text_tokens = self.processor(
^^^^^^^^^^^^^^^
File "H:\ComfyUI_windows_portable 1\python_embeded\Lib\site-packages\transformers\models\llava\processing_llava.py", line 160, in __call__
num_image_tokens = (height // self.patch_size) * (
~~~~~~~^^~~~~~~~~~~~~~~~~
TypeError: unsupported operand type(s) for //: 'int' and 'NoneType'
Follow the install transformer command in other comments to fix it in your local computer…
Where exactly to copy the models. I downloaded the files (renamed the one file) an copied to my gdrive in AI_PICS/models into the corresponding folders. What confuses me that you write into ComfyUI/Models/… as in the AI_PICS folder is also a a ComfyUI folder. Could you help.
When I launch your notebook, the Manager doesn’t show them available for install. What am I doing wrong here 🙂
Solved. Sorry for bothering. Forgotten to upload files to session storage 🙂
I got this Issue :
HyVideoTextImageEncode
unsupported operand type(s) for //: ‘int’ and ‘NoneType’
I downgraded transformers from 4.48.0 to 4.47.0. from E:\ComfyUI\ComfyUI_windows_portable\python_embeded folder
I also deleted the llm llava folders.
But I got the same issue., do you have any idea, what’s wrong?
I had the same issue and used the below command to get it to work
# pip install transformers==4.47.0
I already did it. It doesn’t change anything for me.
Note that in Lib\site-packages\
There are directories
transformers and transformers-4.48.2.dist-info
which are requested by ComfyUI and that it automatically reinstalls them on startup.
if portable ComfyUI try this to install it correctly:
.\python_embeded\python.exe -m pip install transformers==4.47.0
worked for me
Ok this command finally works.
.\python_embeded\python.exe -m pip install transformers==4.47.0
Only on the portable version.
Thank you very much.
Ok, having the same issue when running on Colab. Any ideas how to fix this?
ComfyUI Error Report
## Error Details
– **Node ID:** 73
– **Node Type:** HyVideoTextImageEncode
– **Exception Type:** TypeError
– **Exception Message:** unsupported operand type(s) for //: ‘int’ and ‘NoneType’
## Stack Trace
“`
File “/content/ComfyUI/execution.py”, line 327, in execute
output_data, output_ui, has_subgraph = get_output_data(obj, input_data_all, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/content/ComfyUI/execution.py”, line 202, in get_output_data
return_values = _map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/content/ComfyUI/execution.py”, line 174, in _map_node_over_list
process_inputs(input_dict, i)
File “/content/ComfyUI/execution.py”, line 163, in process_inputs
results.append(getattr(obj, func)(**inputs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/content/ComfyUI/custom_nodes/comfyui-hunyuanvideowrapper/nodes.py”, line 884, in process
prompt_embeds, negative_prompt_embeds, attention_mask, negative_attention_mask = encode_prompt(self,
It is fixed. See new instructions in the step-by-step guide section for colab.
I am using the desktop version of comfyUI on windows, and i’m getting the:
[…] TypeError: unsupported operand type(s) for //: ‘int’ and ‘NoneType’
I’ve run the command ‘python.exe -m pip install transformers==4.47.0’
while I’m in the \@comfyorgcomfyui-electron\ folder with termina but this does not fix the error.
I’m not sure I’m executing this command in the correct folder.
Thank you for more instruction how to downgrade with desctop version on windows.
You have to be in the comfyui context in powershell, I had to enable unsigned script running to get it to work as well. This description solved it for me once I had the correct settings for priveleges: https://github.com/kijai/ComfyUI-HunyuanVideoWrapper/issues/269#issuecomment-2676839785
1) Open powershell at your comfyUI folder with admin priveleges
2) Execute all these steps (just setting the transformer version in powershell doesn’t apply it to the comfyui env) ::
.\venv\Scripts\Activate.ps1
python -m ensurepip
python.exe -m pip install transformers==4.47.0
any recommended setting for a 12gb 4070 TI? i get OOM trying a 240×240 30 frame render.
what about , i see it can be used , but how correct map images to tags?
Getting error. The file path exists but not the file in the folder.
– **Node ID:** 71
– **Node Type:** DownloadAndLoadHyVideoTextEncoder
– **Exception Type:** FileNotFoundError
– **Exception Message:** No such file or directory: “C:\\directory\\ComfyUI_windows_portable_nvidia_cu118_or_cpu\\ComfyUI_windows_portable\\ComfyUI\\models\\LLM\\llava-llama-3-8b-v1_1-transformers\\model-00001-of-00004.safetensors”
delete the llava-llama-3-8b-v1_1-transformers folder in LLM and try again.
Hello,
I have this exception during generation :
“Only vision_languague models support image input”
I am using all the specified models and have no clue…
Thank you for your help !
You can try deleting the xtuner text encoder and let it auto-download agin.
deleting the xtuner dont working..
Hello,
I have the following issue while trying your workflow :
HyVideoTextImageEncode
## Error Details
– **Node ID:** 73
– **Node Type:** HyVideoTextImageEncode
– **Exception Type:** TypeError
– **Exception Message:** unsupported operand type(s) for //: ‘int’ and ‘NoneType’
Any idea ?
Thanks in advance
See the solution in the other comment.
Thank you for your answer.
I did but nothing better.
Any other idea ?
Can you try reinstall ‘python.exe -m pip install transformers==4.47.0’, and then clear dependency lib.
I confirm the problem is fixed for me by reinstall ‘python.exe -m pip install transformers==4.47.0’. Thanks a lot !
Same issue here, I tried re-downloading the llava thing numerous times.
Downgrading transformers to version 4.47.0 does the trick.
What is the recommended VRAM to run this? I’m getting a `torch.OutOfMemoryError` exception in the (Down)load TextEncoder node on 12GB.
You can reduce the video size and the number of frames until it fits. The default setting in the json file uses 20GB VRAM.
Привет! Ошибка в узле ВАЕ загрузчик. Ошибка занимает весь экран монитора.
You need to download the VAE using the link in this tutorial. The VAE for this custom nodes is not the same as the one released by comfyui org.
Hi! Please excuse my mistake. I created a Hunyuan folder in the VAE folder. I moved the file to the VAE folder and everything worked!
thankyou. very helpful tutorial.
Hi! i got this issue:
HyVideoTextImageEncode
unsupported operand type(s) for //: ‘int’ and ‘NoneType’
Same here
This is a known issue: https://github.com/kijai/ComfyUI-HunyuanVideoWrapper/issues/269
Downgrade the transformers library to fix it.
Run “python.exe -m pip install transformers==4.47.0” in the python_embedded folder.
Downgraded to 4.47.0 and still getting the error.
# ComfyUI Error Report
## Error Details
– **Node ID:** 73
– **Node Type:** HyVideoTextImageEncode
– **Exception Type:** TypeError
– **Exception Message:** unsupported operand type(s) for //: ‘int’ and ‘NoneType’
Getting a “‘TextEncoder’ object has no attribute ‘is_fp8′” noticed there is no Clip connected to the TextImageEncode Node. Does it need to have an input?
Thanks for this breakdown!
There’s no clip connection to the textencoder node. Try updating all in comfyui manager.
File “D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\transformers\models\llava\processing_llava.py”, line 160, in __call__
num_image_tokens = (height // self.patch_size) * (
~~~~~~~^^~~~~~~~~~~~~~~~~
TypeError: unsupported operand type(s) for //: ‘int’ and ‘NoneType’
Update:
The problem has gone after I downgraded transformers from 4.48.0 to 4.47.0.
What is the best option currently available if I want to create anime/cartoon video. Is it text to video or image to video ? Also which models would be best to achieve that. Any recommended workflow would be much appreciated.
Hunyuan and Mochi are the local models currently with the highest quality. Try prompting the model for style. If you don’t like them,train LoRAs for Hunyuan to finetune it.
I got this issue : HyVideoTextImageEncode
The input provided to the model are wrong. The number of image tokens is 0 while the number of image given to the model is 1. This prevents correct indexing and breaks batch generation.
You need the an image token in the prompt.