
WAN 2.1 VACE (Video All-in-One Creation and Editing) is a video generation and editing model developed by the Alibaba team. It unifies text-to-video, reference-to-video (reference-guided generation), video-to-video (pose and depth control), inpainting, and outpainting under a single framework.
VACE supports the following core functions:
- Reference-to-Video (R2V): Generate a video sequence from reference images.
- Video-to-Video (V2V): Apply style transfer to an existing video.
- Masked Video Editing (MV2V): Inpaint or outpaint specific regions within each frame.
You can use the WAN VACE model in ComfyUI with the built-in nodes like WanVaceToVideo and TrimVideoLatent to process prompts, images, and control signals.
This tutorial covers the Reference-to-Video (R2V) workflow on ComfyUI, which uses a reference image to generate a video.

Note that this is NOT image-to-video, where the image is used as the first frame. Here, the video appears to be the same as the image, but it is different.
Table of Contents
Software
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.
Generation time
This workflow takes 57 minutes to generate a 3.3-second 720 x 1280 clip on my RTX4090. Reducing the resolution to 720 x 720 reduces the generation time to 23 minutes.
Google Colab notebook
My ComfyUI Google Colab notebook supports running this workflow. It comes in handy if you don’t have a fast GPU card.
If you use it, you can select L4 or A100 (fast) GPU to run this workflow. Select Wan 2.1 under Video models and skip the model download step below.
Other Wan 2.1 workflows
- Wan 2.1 Text-to-Video: Generate a video based on the text prompt.
- Wan 2.1 Image-to-Video: Generate a video with the initial frame’s image.
- Speeding up Wan 2.1 with Teacache and Sage Attention
- Flux-Wan 2.1 video workflow (ComfyUI)
- Flux-Wan 2.1 four-clip movie (ComfyUI)
Wan 2.1 VACE Reference-to-video on ComfyUI
Step 1: Update ComfyUI
Before loading the workflow, ensure your ComfyUI is up to date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.

Select Update ComfyUI.
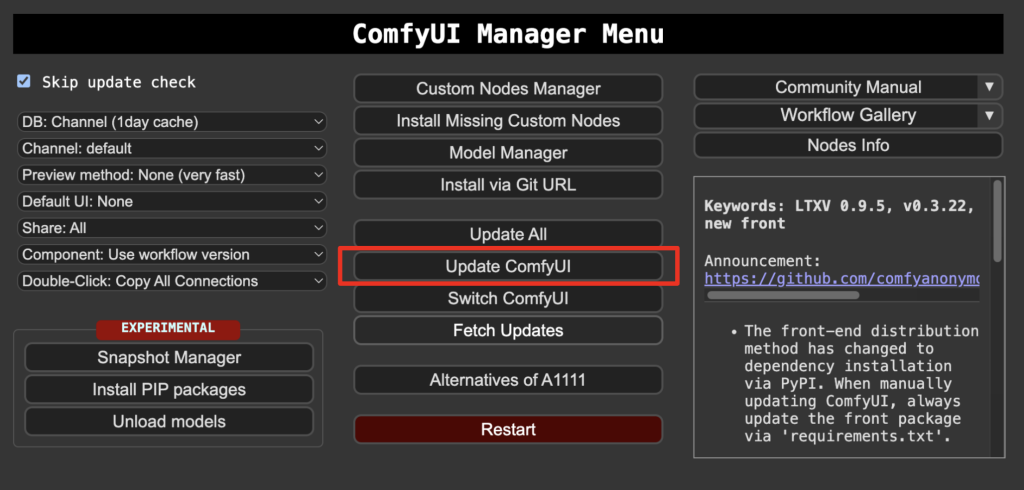
Restart ComfyUI.
Step 2: Download model files
Download the diffusion model wan2.1_vace_14B_fp16.safetensors and put it in ComfyUI > models > diffusion_models.
Download the text encoder model umt5_xxl_fp8_e4m3fn_scaled.safetensors and put it in ComfyUI > models > text_encoders.
Download the Wan VAE model wan_2.1_vae.safetensors and put it in ComfyUI > models > vae.
Step 3: Load the workflow
Download the workflow JSON file below and drop it into ComfyUI to load.
Step 4: Install missing nodes
If you see red blocks, you don’t have the custom node that this workflow needs.
Click Manager > Install missing custom nodes, and install the missing nodes.
Restart ComfyUI.
Step 5: Set the input reference image
The Wan VACE workflow requires an input reference image. The reference image guides the video generation, but it won’t appear exactly.
Upload the reference image to the Load Image node.
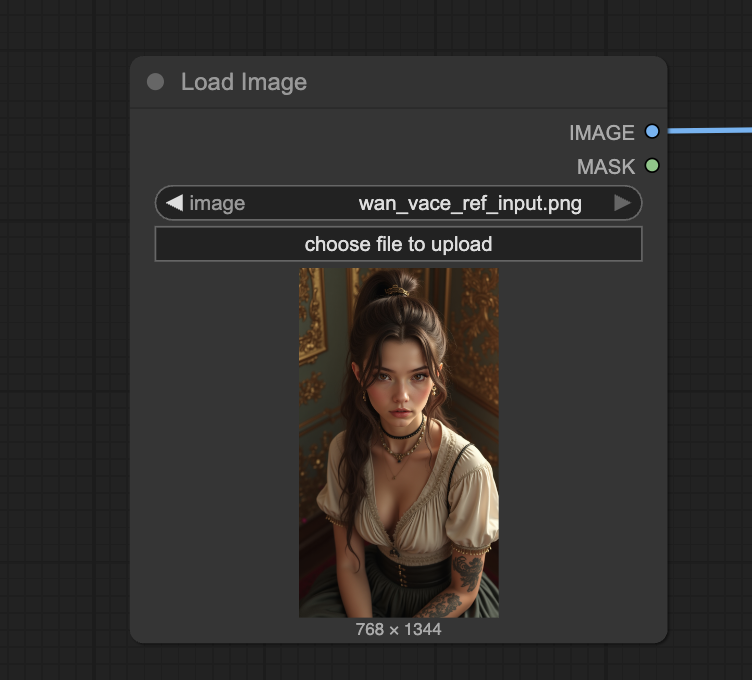
The image was generated using the Flux.1 Dev model with the following prompt.
Animate of a highly detailed portrait of a rebellious in victorian age but feminine young woman. She has long, brown hair tied in a high ponytail, with a few loose strands framing her face. Her skin is smooth with a slight glow, She has an intense, confident gaze directed at the viewer.
She dress conservatively yet showing her rebellious tattoo on her arm.
Her hairdress and outfit reveals her noble origin.
Her pose is casual yet assertive, She leans slightly forward, resting one arm on her knee.
The setting has warm, natural lighting that casts soft shadows on her face and outfit, emphasizing depth and realism. The textures of the fabric, metal accessories.
The background is a victorian palace, with golden wall decors and patterns.
Or you can use the image below.

Step 6: Revise the prompt
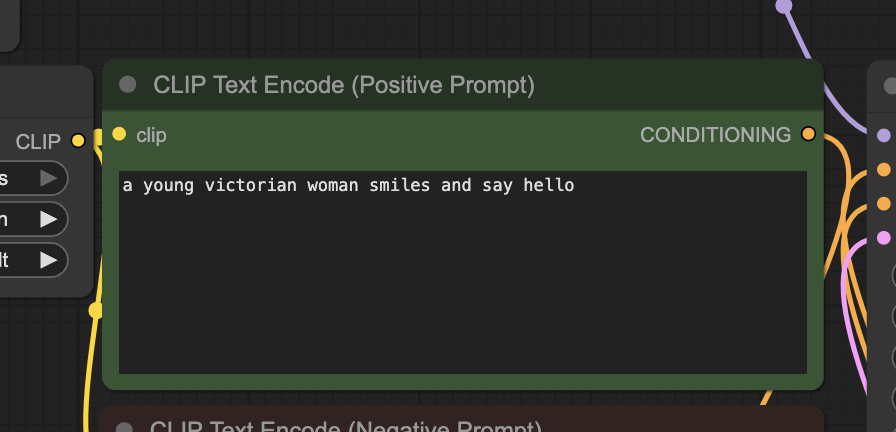
Revise the prompt to describe the video you want to generate. In the workflow, I have:
a young victorian woman smiles and say hello
Some tips:
- Describe what the subject is doing.
- Add action words, e.g., laugh, run, fight, etc.
Step 7: Generate the video
Click the Run button to run the workflow.

Tips for using Wan VACE model
Video resolution
The Wan 2.1 VACE 14B model supports resolution from 480p to 720p.
Here are some commonly used resolutions:
- 480 p (SD)
- 640 × 480 (4:3)
- 854× 480 (16:9)
- 720p (HD)
- 960 x 720 (4:3)
- 1280 × 720 (16:9)
To set the video resolution, change the width and height of the WanVaceToVideo node.
Reducing the resolution is an effective way to speed up image generation.
Seed
Change the seed value in the KSampler node to generate a new video.
Hello Andrew, when downloading the workflow this message is coming:
Missing Models
When loading the graph, the following models were not found
text_encoders / umt5_xxl_fp16.safetensors
(Download 10,59GB)
And then during the work, on some point it stops.
Download the umt5 model in step 2.
Thanks, Andrew, I think the model is interesting in the way it creates a new scene from the reference and the image quality seems very good. On Colab A100, a 720×1280 3 sec video takes 36 mins, 20 mins at 720×960 and just 6 mins at 480×640. The reduced resolution is noticeable at 480×640 but it’s still pretty good and worth it for a reasonable generation time.
But I found the model doesn’t adhere to the prompt, even simple prompts such as having the woman stand up or the camera pull back. A shame as the creativity element is interesting.
yeah, controlling the camera motion is hit or miss. It seems that the model is not well trained. Leaving the camera keywords out results in better videos.
This is nice, but frankly I don’t really see much advantage to R2V over I2V workflows. Of the three core features you mentioned at the start, I’m much more interested in the V2V and MV2V modes.
Yes they are coming.