
Wan 2.2 is a local video model that can turn text or images into videos. In this article, I will focus on the popular image-to-video function. The new Wan 2.2 models are surprisingly capable in motion and camera movements. (But not necessarily controlling them)
This article will cover how to install and run the following image-to-video models:
- Wan 2.2 14B model – higher quality but needs more VRAM and takes longer.
- Wan 2.2 5B model – Slightly lower quality but is quicker and needs lower VRAM.
Table of Contents
Software needed
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.
Wan 2.2 model
Wan 2.2 is a multimodal AI model from Wan AI, a highly ancipated update to Wan 2.1. It uses a new “Mixture of Experts” model architecture, where different expert sub-models handle different levels of noise during video creation. The result is cleaner, sharper videos.
Main features:
- Movie‑quality visuals: You can adjust lighting, color, and framing using a prompt.
- Smooth complex motion: Good improvement in motion generation.
- Accurate scene understanding: Generating scenes with many objects and details.
You can create videos from text or images.
The models and the code are open-source and under the permissive Apache 2.0 license, making it open to commercial use.
ComfyUI Colab Notebook
If you use my ComfyUI Colab notebook, you don’t need to download the model as instructed below. Select the Wan_2_2 model before running the notebook.

image-to-video with the Wan 2.2 14B model
This workflow turns an input image into a video. It requires 20 GB VRAM and takes about 1 hr 20 mins on an RTX4090 GPU card.
Step 0: Update ComfyUI
Before loading the workflow, make sure your ComfyUI is up to date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.

Select Update ComfyUI.
Restart ComfyUI.
Step 1: Load the workflow
Download the workflow below.
Step 2: Download models
After loading the workflow JSON file, ComfyUI should prompt you to download the missing model files.
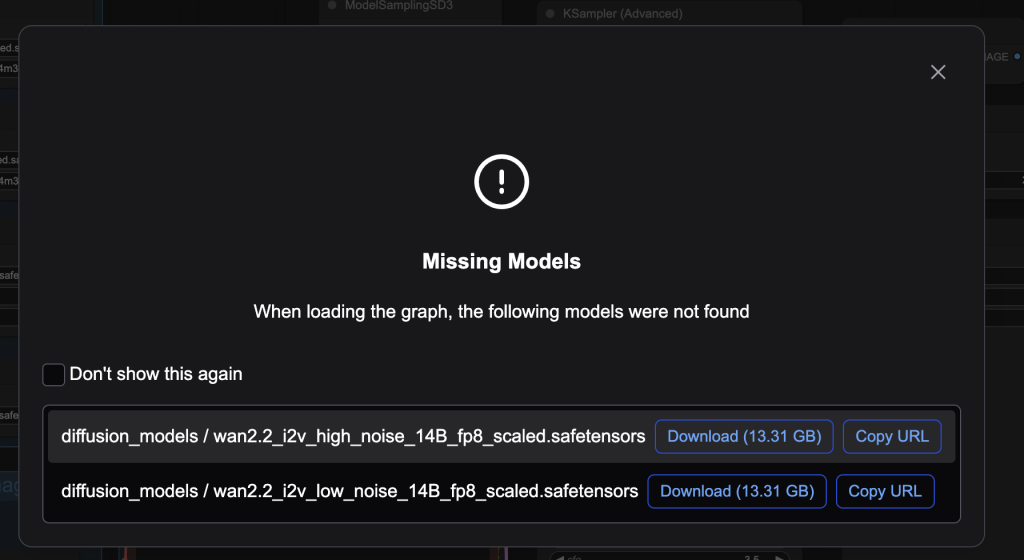
Here are what you need to download:
- Download wan2.2_i2v_high_noise_14B_fp8_scaled.safetensors and put it in ComfyUI > models > diffusion_models.
- Download wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors and put it in ComfyUI > models > diffusion_models.
- Download umt5_xxl_fp8_e4m3fn_scaled.safetensors and put it in ComfyUI > models > text_encoders.
- Download wan_2.1_vae.safetensors and put it in ComfyUI > models > vae.
Step 3: Upload an image for the start frame
Upload an image you wish to use as the first frame of the video.
You can use the test image below.

Step 4: Revise the prompt
Describe your video in the prompt. Use keywords to direct the camera.
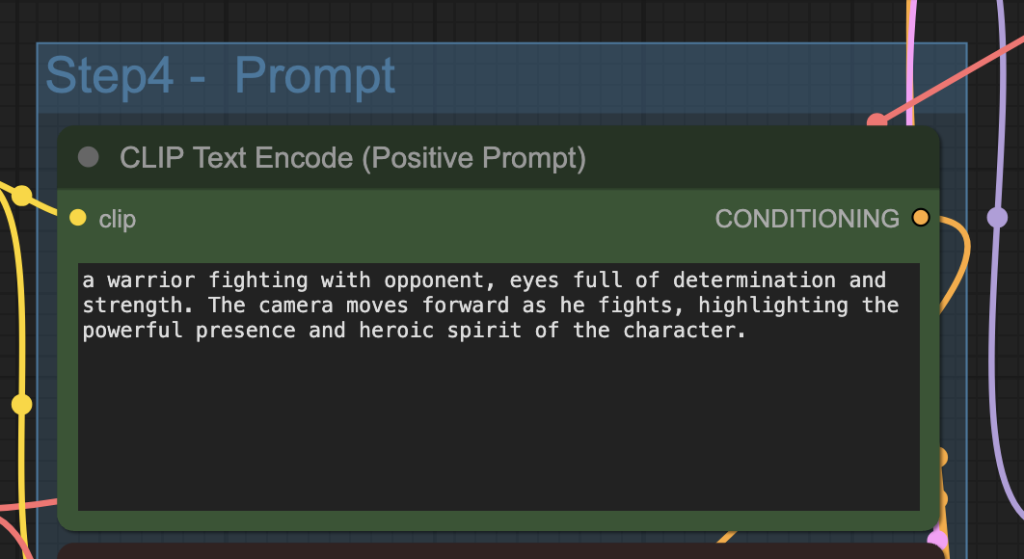
Step 5: Generate the video
Click the Run button to run the workflow.

image-to-video with the Wan 2.2 5B model
This workflow turns an input image into a video. Unlike the 14B model, this smaller model requires only 8 GB VRAM and takes about 6 mins on an RTX4090 GPU card.
Step 1: Download the workflow
Download the workflow below and drop it into ComfyUI to load.
Step 2: Install models
Here are the model files you need to install:
- Download wan2.2_ti2v_5B_fp16.safetensors and put it in ComfyUI > models > diffusion_models.
- Download umt5_xxl_fp8_e4m3fn_scaled.safetensors and put it in ComfyUI > models > text_encoders.
- Download wan2.2_vae.safetensors and put it in ComfyUI > models > vae.
Step 3: Upload an image for the start frame
Upload an image you wish to use as the first frame of the video.
You can use the test image below.
Step 4: Revise the prompt
Describe your video in the prompt. Use keywords to direct the camera.
Step 5: Generate the video
Click the Run button to run the workflow.
Testing camera keywords on Wan 2.2
The Wan AI team touted a significant improvement in the model’s ability to follow camera instructions. Let’s put it to the test. I will stick with the 5B model due to the generation time.
Zoom
Zooming out from a character is working pretty well:
Sometimes, it confuses zooming in and out.
The solution is to generate a few more videos and pick the best one.
But it is not clear whether the zoom is working when the character is doing something at the same time.
Pan
Panning right works pretty well:
Panning left is still producing a video of panning right (and zooming out).
I think what happens is that the initial image is more natural for the video to pan right than left. The model produces likely videos rather than following the prompt.
Useful links
Wan2.2 Day-0 Support in ComfyUI – Release press from ComfyUI
Wan-Video/Wan2.2 – Github page hosting the source code
Wan-AI/Wan2.2-I2V-A14B · Hugging Face – Model weights of the 14B I2V model
Wan-AI/Wan2.2-TI2V-5B · Hugging Face – Model weights of the 5B I2V model
Wan2.2 Video Generation – ComfyUI’s official documentation
Is it possible to run Wan 2.2 completely on Google Colab without using ComfyUI?
Certainly, if you are good with python. The original repos has example code.
Hi! just wondering since i am new to this, if i used colab, will i be able to add new checkpoints or loras in it? and would it limit our creation (such as NSFW banned or not)
Please kindly reply!
Thankyou
Yes, you can add models and loras by placing them in your google drive.
There’s no censorship on colab.
Hello man, thank you for ur guides, idk but im doin all the same as u and video from image doesnt created like from the beginning, i mean finish video is just like a does not depend on the image I upload, mb can u recorded from 0 to finish how u create video from image in comfy, anyway thanx *_*
I see the following error in Mac M2.
Missing Node Types
When loading the graph, the following node types were not found
CreateVideo
Wan22ImageToVideoLatent
Great article, as always! Thanks for sharing! Apologies for the noob question, but I got a bit confused and couldn’t really find a clear explanation that lays it all out. I do understand the differences between the T2V, I2V, and FLF2V models, and I’m also familiar with the GGUF models. But what are these other variants like Fun, X, Fusion, VACE, MultiTalk, and possibly others? What exactly do they do?
I don’t know what I’m doing wrong, but all I can manage to generate is a brown fog video. Nothing else is visible. I followed the instructions for WAN 2.2 5B and everything seems fine, everything placed and installed but the result is the same. Does anyone have any idea what could be going on? 🙁
Hi there! Thanks again for these useful tutorials and ComfyUI tips. Greatly appreciated. Question, how to use LORA in this set-up? As we’re now using two “diffusion models” how to use LORA’s ? I can’t wrap my mind into doubling the LORA boxes? Thanks for further help!
Why download wan_2.1_vae.safetensors (2.1) for 14B instructions instead of wan2.2_vae.safetensors as it is in the 5B instructions?
Good question. I simply follows the lead of official example workflows.
AFAIK 2.2 vae is only compatible with 5B, 14B should use 2.1 vae
Thanks , Andrew, the quality looks great in your examples and I look forward to trying this. I see Comfy also make Wan2.2 available through an API.
You know what I’m going to ask 🙂 please could you put the links to upload the models into the Colab notebook.
Yes +1 on this please. I figure by the time I’m done downloading the models and uploading them into drive the Colab notebook will be updated before then lol.
Joe, there are ways to use Colab to copy models, Loras etc directly to the relevant sub-folder in your AI_PICS folder stack which avoids the slow upload problem. Andrew recently offered to develop a notebook to do this (sorry that I can’t find the post) and I used Gemini to write code for me to use in my own notebooks.
But to use large models like Wan2.2, it is much (!) easier to be able to tick a box in Andrew’s Comfy notebook and have Colab manage it all which avoids using one’s personal storage allocation for the files. I always seem to be coming up against my storage limit.
Great to know! Thanks. Ended up downloading the files and got a test done last night. Movement is fantastic, added a weird vfx in the video and the generation takes forever but wow, impressed so far.
I forgot about that… will do.