
Wan 2.1 Video is a state-of-the-art AI model that you can use locally on your PC. However, it does take some time to generate a high-quality 720p video, and it can take a lot of time to refine a video through multiple generations.
This fast Wan 2.1 workflow uses Teache and Sage Attention to reduce generation time by 30%. It will help you iterate through multiple videos with significant time-saving.
Table of Contents
Software
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.
How does the speed-up work?
This workflow uses two speed-up techniques: Teacache and Sage Attention.
Teacache
TeaCache takes advantage of the observation that some neural network blocks don’t do much during sampling. Researchers have recognized that diffusion models generate image outlines in the initial sampling steps and fill in details in the late steps.

TeaCache intelligently determines when to use caches during sampling. It uses the cached output when the current input is similar to that produced the cache. It only recomputes the cache when the input becomes substantially different. You can control how often the cache is recomputed by a threshold value.
See also: TeaCache: 2x speed up in ComfyUI
Sage Attention
Sage Attention speeds up transformer attention operations by quantizing the computation. Instead of full precision, it uses lower precision (like 8-bit or 4-bit) in the key parts of the attention operation. It can speed up many AI models with nearly lossless accuracy.
Google Colab
If you use my ComfyUI Colab notebook, select the following before running the notebook.
- WAN_2_1 video models
- WAN_2_1 custom nodes
- VideoHelperSuite custom nodes


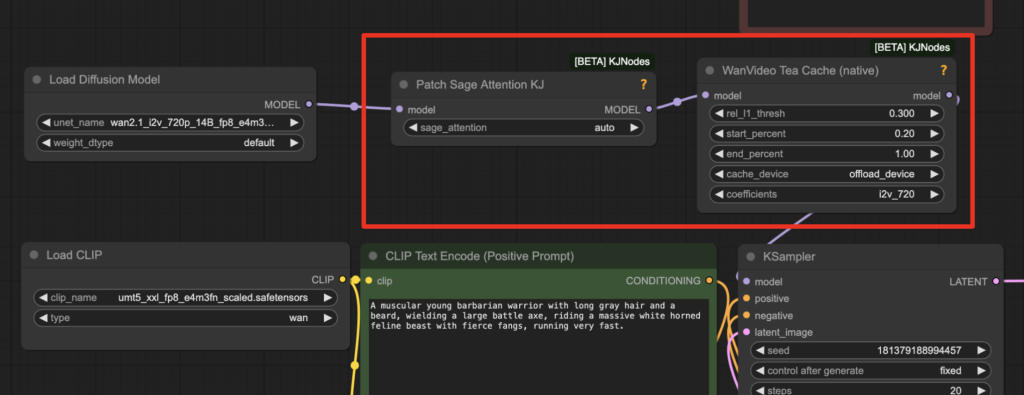
Fast Wan 2.1 Teacache and Sage Attention workflow
This fast Wan 2.1 workflow uses KJNodes‘ Sage Attention and Teacache nodes. It is ~30% faster than the standard Wan 2.1 workflow.
The two speed-up nodes are placed between the Load Diffusion Model and the KSampler node.
Step 1: Update ComfyUI
Before loading the workflow, make sure your ComfyUI is up to date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.

Select Update ComfyUI.
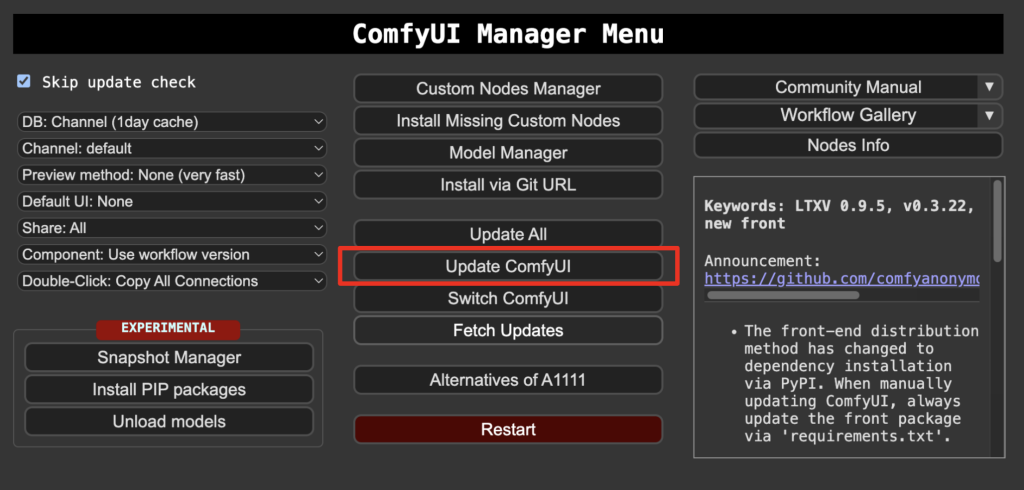
Restart ComfyUI.
Step 2: Download model files
Download the diffusion model wan2.1_i2v_720p_14B_fp8_e4m3fn.safetensors and put it in ComfyUI > models > diffusion_models.
Download the text encoder model umt5_xxl_fp8_e4m3fn_scaled.safetensors and put it in ComfyUI > models > text_encoders.
Download the CLIP vision model clip_vision_h.safetensors and put it in ComfyUI > models > clip_vision.
Download the Wan VAE model wan_2.1_vae.safetensors and put it in ComfyUI > models > vae.
Step 3: Load the fast Wan 2.1 workflow
Download the workflow JSON file below and drop it to ComfyUI to load.
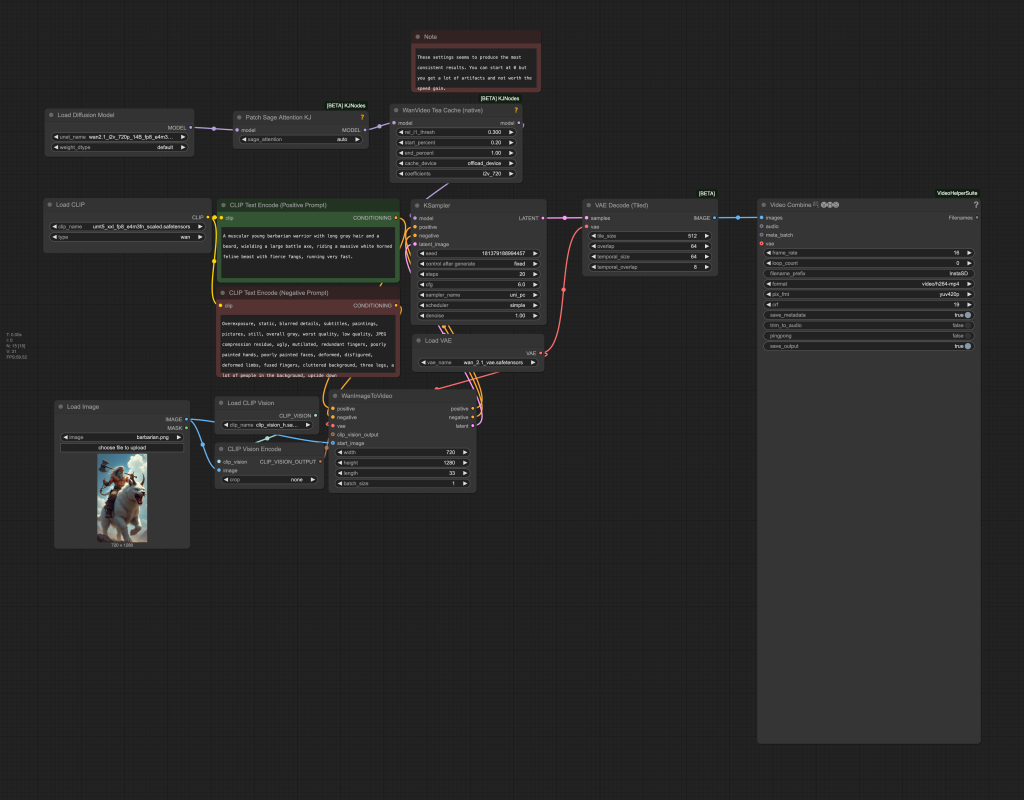
Step 4: Install missing nodes
If you see red blocks, you don’t have the custom node that this workflow needs.
Click Manager > Install missing custom nodes and install the missing nodes.
Restart ComfyUI.
Step 5: Install trition and sage attention
The Sage Attention node requires the trition and sage attention packages that do not come with the JK Nodes.
For Windows users, navigate to the Python folder of your ComfyUI.
For the Windows portable version, it is ComfyUI_windows_portable > ComfyUI_windows_portable.
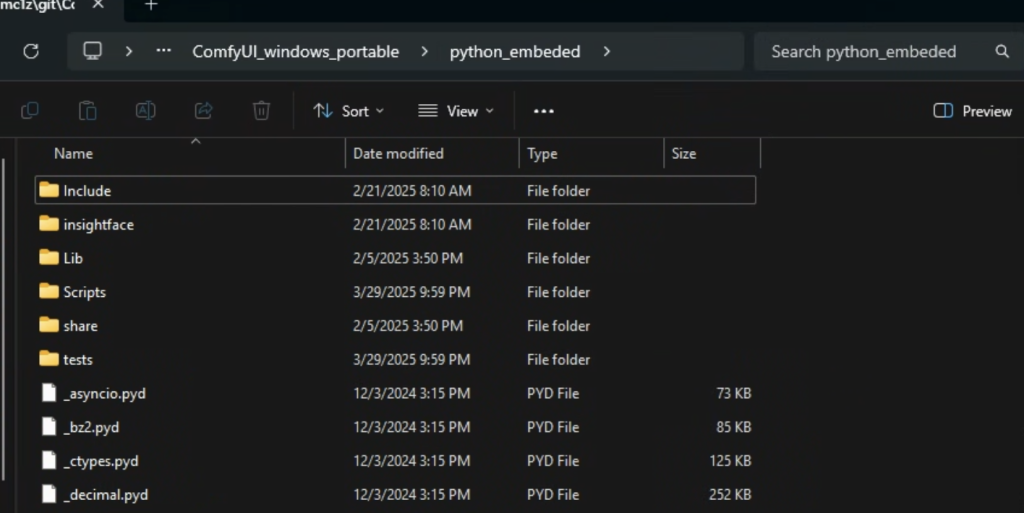
Enter cmd in the address bar and press Enter.
You should see the command prompt.
Enter the following command to install triton.
python -m pip install triton-windowsEnter the following command to install sage attention.
python -m pip install sageattentionStep 6: Set the image image
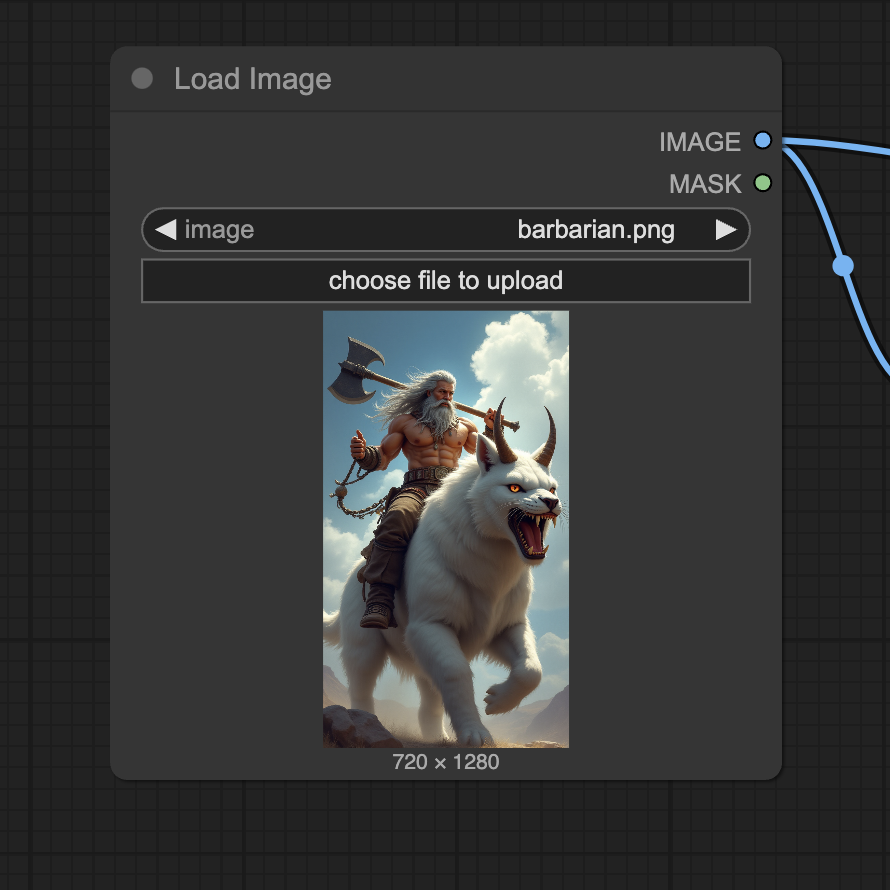
Upload an image you wish to use as the video’s initial frame. You can download my test image for testing.
{kind=link}
Step 7: Revise the prompt
Revise the positive prompt to describe the video you want to generate.
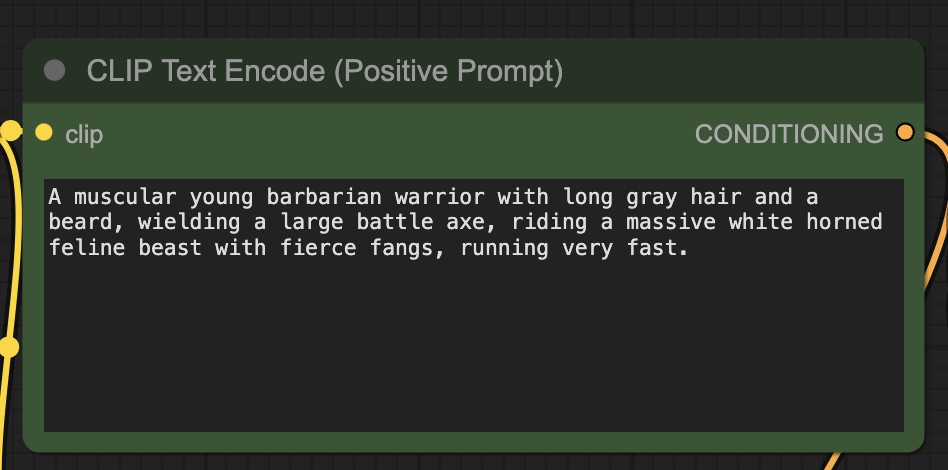
Don’t forget to add motion keywords, e.g. Running.
Step 8: Generate the video
Click the Queue button to run the workflow.

You should get this video.
KSampler
[Errno 22] Invalid argument
never mind not your fault
when running your provided workflow in the step at KSampler, an error message ‘no module named Sageattention’ is shown t. Can you help?
Install the packages in step 5.
aready done, the problem still exists
Same problem.
I ran step 5 in my Documents\ComfyUI\.venv directory.
I got the same error message as Joeseph.
It should be run in .venv\scripts so that you are calling the python that comfyui uses
when running your provided workflow, an error message ‘no module named Sageattention’ is shown. Can you help?
KSampler
DLL load failed while importing libtriton: Eine DLL-Initialisierungsroutine ist fehlgeschlagen.
in Version ComfyUI v0.3.40 maybe someone have an idea 🙂
if lora has to be plugged in your workflow where you will actually connect the node
right after the load checkpoint. See https://stable-diffusion-art.com/wan-2-1-lora/#Adding_a_LoRA_to_the_Wan_21_model
Such a nice workflow, I like it very much. It started right away, all nodes known.
But I wish my external linux server would support it. It has a Tesla V100 with 32 GB VRAM. The problem comes from triton or sageattention, it reads:
PassManager::run failed
Is there any hope to fix that? Tesla V100 too old?
V100 doesn’t support reduced precisions like fp8. You can see if there are fp16 versions of the model files.
Thanks, Andrew, this looks like it will be a significant improvement. But on Colab, Comfy isn’t finding the sage attention module.
Hi David, I added the KJNodes. See the updated instruction on this page.
Thanks, Andrew, that got it working and I was able to generate one 720×1280 video on L4 with your workflow at length 33 – a 2 sec video took 17 mins which is a lot quicker than before. But subsequently, I kept getting out of memory errors on the KSampler. I could get round this by reducing the length eg to 25 or 1 sec (generation time 11 mins) and the quality looks very good.
With the 480 model, the memory problems didn’t recur and a 480×848 video of length 25 took 7 mins and a length 49 video, 3 secs, took 10 mins. The quality was much worse than the 720 model, however, and subjectively worse than the equivalent without TeaCache.
Are there any other settings I can tweak to get longer 720 videos using Colab?
Same issue on the notebook with L4.
actually have the same OOM issue with a100 as well, I thought it was working but now its not, I must have been using the original workflow.
It seems some nodes have memory leak. You can try using the buttons next to the Manager button to unload the model and node caches.
Thanks, Andrew, that helped as did reducing the resolution to 720×720 with the 720 model, following a suggestion you made in the comments to your Hunyuan TeaCache post.
I was able to generate a 4 sec video in 17 mins. It also worked at 4:3, 720×960, but it took much longer – 30 mins for 3 secs.
Interestingly, the frame rate seemed natural at the initial resolution but when I increased it, the video was in slowmo, as also happened with Hunyuan. Your suggestion there about increasing the frame rate fixed that – in this case from 16 to 21 fps.
I gave that a shot but still got the OOM error on L4. Works fine with the A100 though.
I’m having the same issue, but with a local windows install
If triton fails for you check this: https://github.com/woct0rdho/triton-windows/issues/83
Thanks for sharing this – that did the trick for me as well!