
This workflow generates beautiful videos of mechanical insects from text prompts. You can run it locally or using a ComfyUI service. It uses Flux AI to generate a high-quality image, followed by Wan 2.1 Video for animation with Teacache speed up.
You must be a member of this site to download the following ComfyUI workflow.
Table of Contents
Software
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.
How does this workflow work?
The Flux text to image block generates a static image using the Flux.1 Dev model.
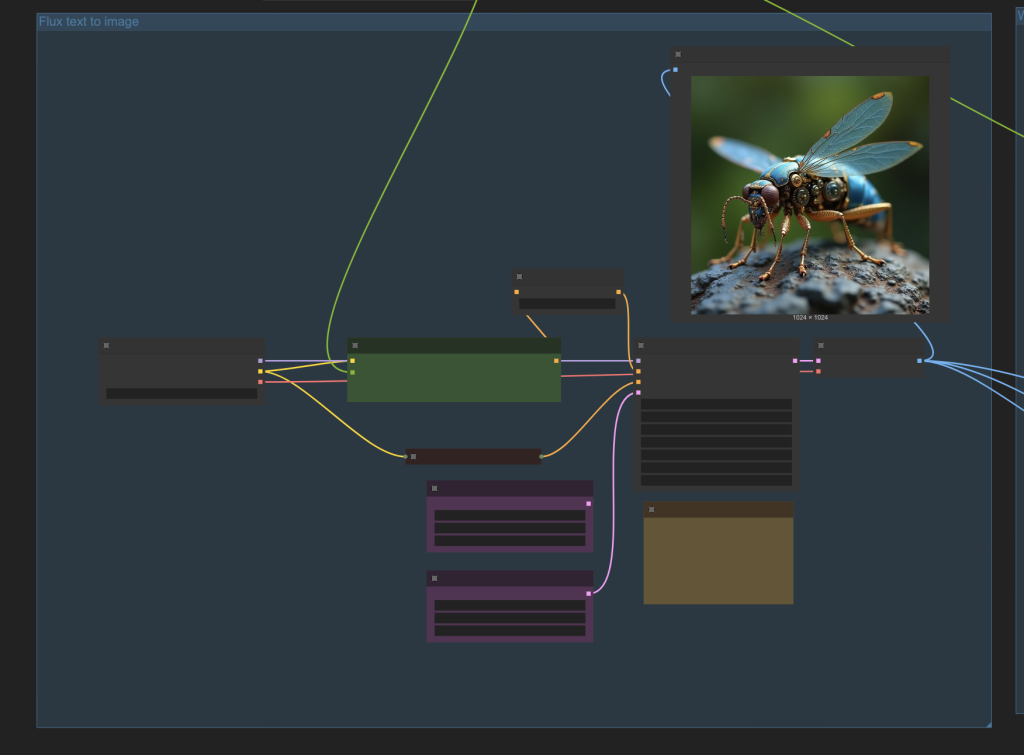
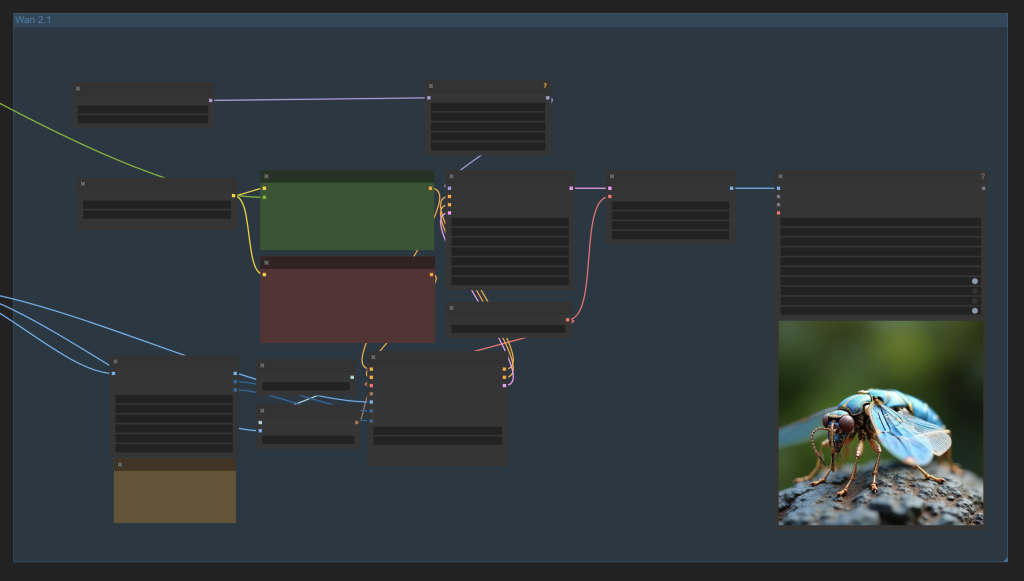
The Wan 2.1 block converts the static image to a video using the same prompt.
Step-by-step guide
Step 1: Load workflow
Download the ComfyUI JSON workflow below.
Drag and drop the JSON file to ComfyUI.
Step 2: Install missing nodes
If you see nodes with red borders, you don’t have the custom nodes required for this workflow. You should have ComfyUI Manager installed before performing this step.
Click Manager > Install Missing Custom Nodes.
Install the nodes that are missing.
Restart ComfyUI.
Refresh the ComfyUI page.
Step 3: Download models
Flux
Download the flux1.Dev model flux1-dev-fp8.safetensors. Put it in ComfyUI > models > checkpoints.
Wan 2.1
Download the diffusion model wan2.1_i2v_720p_14B_fp8_e4m3fn.safetensors and put it in ComfyUI > models > diffusion_models.
Download the text encoder model umt5_xxl_fp8_e4m3fn_scaled.safetensors and put it in ComfyUI > models > text_encoders.
Download the CLIP vision model clip_vision_h.safetensors and put it in ComfyUI > models > clip_vision.
Download the Wan VAE model wan_2.1_vae.safetensors and put it in ComfyUI > models > vae.
Google Colab
If you use my ComfyUI Colab notebook, you don’t need to download the model. Select
- the Flux1_dev model
- WAN_2_1 video models
- WAN_2_1 custom nodes
- VideoHelperSuite custom nodes


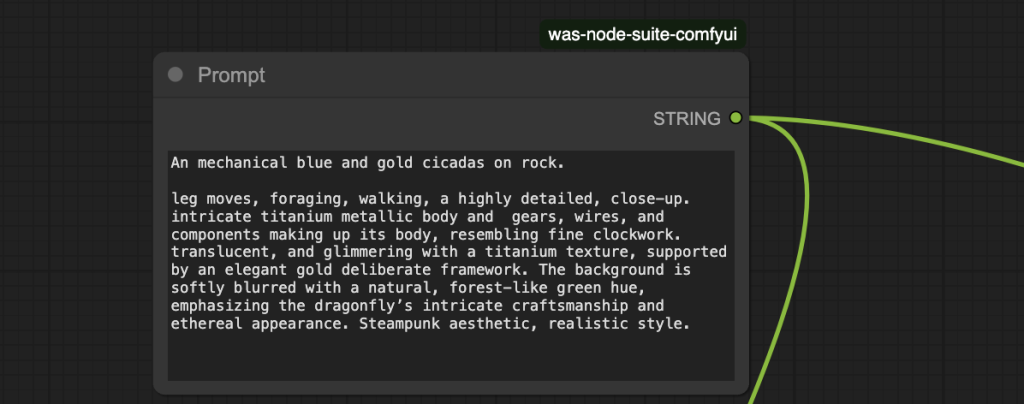
Step 4: Revise the prompt
Revise the prompt above the groups.
Step 5: Run the workflow
Click the Run button to run the workflow.

2-step workflow
You can use the Fast Groups Muter node to control the video generation process more. You can first focus on the initial image generation. Once you are happy with it, go ahead and turn on the video generation.
Generate image only
Turn off the Wan 2.1 group in the Fast Groups Muter.
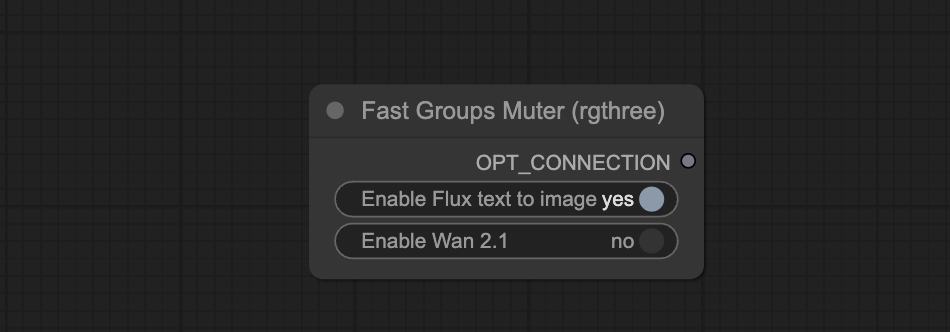
Click the Run button to run the workflow.
You should have run the Flux text-to-image group and seen the preview image.
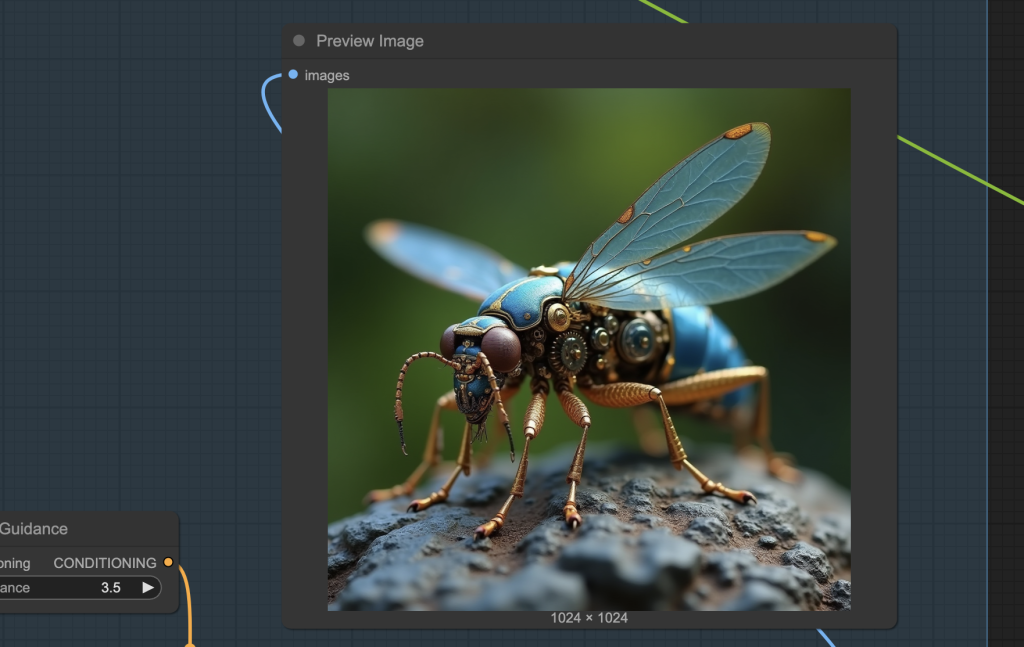
Revise the prompt and seed value until you are happy with the result.
Enable the video generation
Now, turn the Wan 2.1 group back on.
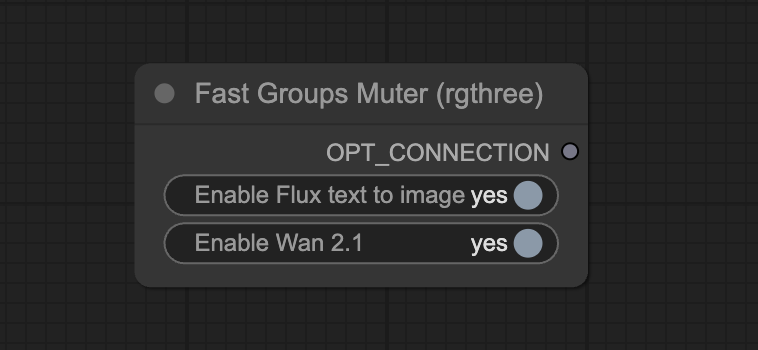
Click the Run button to run the workflow.
You now also get the video.
Change the seed value of the KSampler in the Wan 2.1 group to generate a new video.
Thanks, Andrew, I’ve had great results from your elegant workflow. The insect image lends itself to a short clip and I could generate a 2 sec video in under 8 mins and a 4 sec video in 17 mins on Colab L4. I added a TeaCache node to the Flux image generation group which also sped that stage up nicely.
I notice you didn’t link a sage attention node to the Wan TeaCache node as in your earlier post but it doesn’t seem to affect the speed of generation.
Good observation :)! On windows, many users have issue installing the necessary libraries for sage attention. I tested removing it and the increase the rendering time is not that much.