
LTX Video 0.9.5 is an improved version of the LTX local video model. The model is very fast — it generates a 4-second video in 17 seconds on a consumer-grade GPU RTX4090. It’s not quite real-time, but very close.
In this article, I will cover:
- The improvements over the previous version.
- Text-to-video workflow
- Image-to-video workflow
- Fix the first and last frames in the video.
Table of Contents
Software
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.
Running on Google Colab
If you use my ComfyUI Colab notebook, you don’t need to install the model files. They will be downloaded automatically.
Select the LTX models before starting the notebook.

Download a workflow JSON file from this tutorial and drop it to ComfyUI.
LTXV 0.9.5 Improvements
License
The good news is that the LTXV 0.9.5 version has a new Open RAIL-M license, which allows commercial use. You can host the model and use the generated videos for commercial purposes.
Text-to-video
Like the previous version, LTX Video 0.9.5 supports text-to-video. The video quality has improved.
Image-to-video
LTX-Video can use an image as the first frame and turn it into a video.

Some videos from the image-to-video workflows can be quite hideous. I will give you some tips for generating good videos.
Fix the first and last frames
You can also set both the first and last frames of the video.


Text-to-image workflow
This workflow generates a 4-second video from a text description.
Step 0: Update ComfyUI
Before loading the workflow, make sure your ComfyUI is up-to-date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.

Select Update ComfyUI.
Restart ComfyUI.
Step 1: Download models
Download ltx-video-2b-v0.9.5.safetensors and put it in ComfyUI > models > checkpoints.
Download t5xxl_fp16.safetensors and put it in ComfyUI > models > text_encoders.
Step 2: Load the workflow
Download the workflow below.
Drop it in ComfyUI.
Step 3: Install missing nodes
This workflow uses the Video Combine node to save the video as MP4. If you see red blocks, you don’t have the custom node that this workflow needs.
Click Manager > Install missing custom nodes and install the missing nodes.
Restart ComfyUI.
Step 4: Revise the prompt
Change the prompt to what you want to generate. LTXV works better with long and descriptive prompts. (You can use ChatGPT to expand a prompt. Put in “Expand the following video AI prompt:…”)

Step 5: Generate a video
Click the Queue button to generate the video.

Change the noise_seed value in the SamplerCustom node to generate a different video.
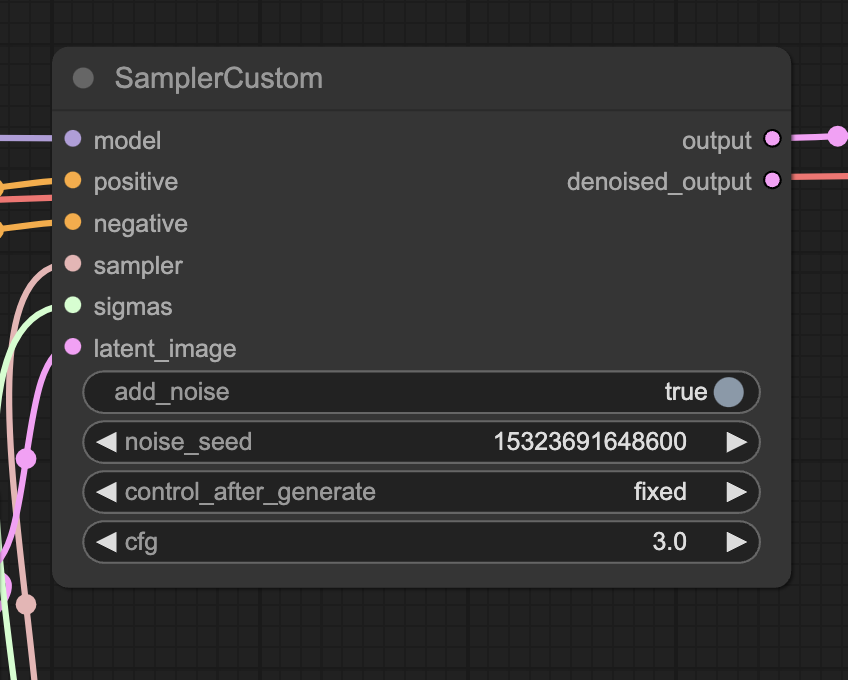
Image-to-video workflow
This workflow takes an input image and uses it as the first frame to generate a video. You also need to describe the video in the prompt.
Step 0: Update ComfyUI
Before loading the workflow, make sure your ComfyUI is up-to-date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.
Select Update ComfyUI.
Restart ComfyUI.
Step 1: Download models
Download ltx-video-2b-v0.9.5.safetensors and put it in ComfyUI > models > checkpoints.
Download t5xxl_fp16.safetensors and put it in ComfyUI > models > text_encoders.
Step 2: Load the workflow
Download the workflow below.
Drop it in ComfyUI.
Step 3: Install missing nodes
This workflow uses the Video Combine node to save the video as MP4. If you see red blocks, you don’t have the custom node that this workflow needs.
Click Manager > Install missing custom nodes and install the missing nodes.
Restart ComfyUI.
Step 4: Upload an image
Upload an image in the Load Image node. The image will be used as the first frame of the video.
{kind=link}
Step 5: Revise the prompt
Change the prompt to what you want to generate. The prompt should match the uploaded image and describe what will happen in the next 4 seconds.
LTXV works better with long and descriptive prompts. (You can use ChatGPT to expand a prompt. Put in “Expand the following video AI prompt:…”)
Step 6: Generate a video
Click the Queue button to generate the video.
Fix the first and last frames in the video
This workflow fixes the first and last frames of the video. To use it, you need two input images and a prompt.
Step 0: Update ComfyUI
Before loading the workflow, make sure your ComfyUI is up-to-date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.
Select Update ComfyUI.
Restart ComfyUI.
Step 1: Download models
Download ltx-video-2b-v0.9.5.safetensors and put it in ComfyUI > models > checkpoints.
Download t5xxl_fp16.safetensors and put it in ComfyUI > models > text_encoders.
Step 2: Load the workflow
Download the workflow below.
Drop it in ComfyUI.
Step 3: Install missing nodes
This workflow uses the Video Combine node to save the video as MP4. If you see red blocks, you don’t have the custom node that this workflow needs.
Click Manager > Install missing custom nodes and install the missing nodes.
Restart ComfyUI.
Step 4: Upload an image
Upload the image of the first frame in the upper Load Image node and teh image of the last frame in the lower Load Image node.
{kind=link}
Step 5: Revise the prompt
Change the prompt to what you want to generate. The prompt should match the uploaded images and describe what will happen in the next 4 seconds.
LTXV works better with long and descriptive prompts. (You can use ChatGPT to expand a prompt. Put in “Expand the following video AI prompt:…”)
Step 6: Generate a video
Click the Queue button to generate the video.
Tips
Generate a new video
Change the noise_seed in the SamplerCustom node to generate a new video.
Change video size
The default resolution is 768 x 512.
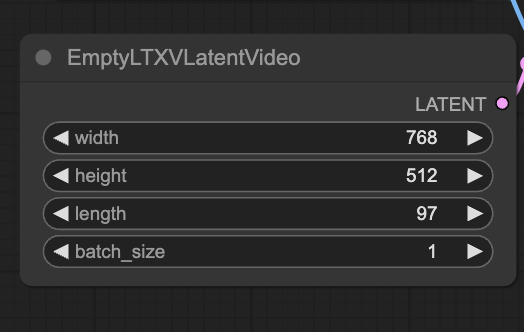
You can swap the width and height to generate a portrait video.
I don’t recommend changing the resolution. You will get lower-quality videos.
Video length
Change the length setting (measured in frames) to adjust the length of the video.
Generate more than 1 video at a time
The batch_size setting in the EmptyLTXVLatentVideo node controls how many videos are generated at a time. Change it to generate multiple videos.
Avoid difficult motions
It is too much to ask the LTXV 0.9.5 model to generate motions like a person putting on a jacket or videos with large body part movement. You will be disappointed!
Long prompts work better
The more you write in the prompt, the better the video. Use ChatGPT to expand the prompt with something like:
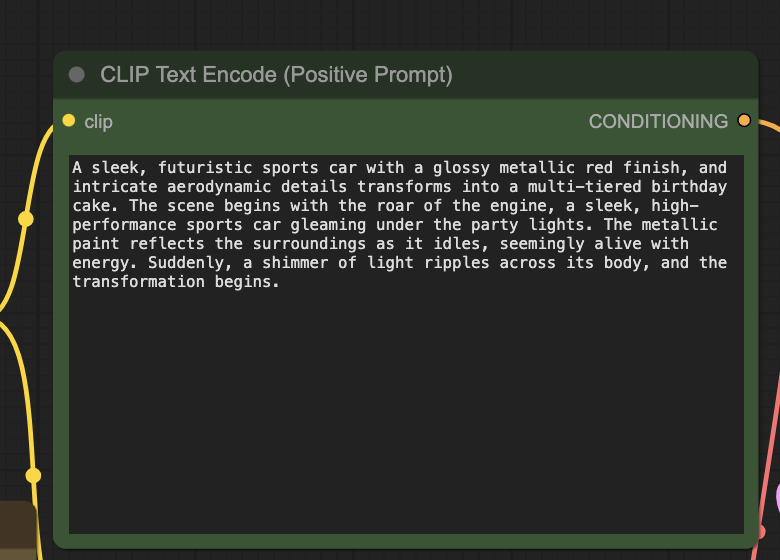
Expand the following AI video prompt: A very cool car transforms to a birthday cake
You may get details that do not match the input image, e.g., a blue car instead of a red one. Adjust accordingly.
Generate a few videos and pick the best one
Sometimes, the video is just bad. It is not your fault. Change the seed and generate a new one. It is fast.
Use FP8 text encoders to save space
If you use an Nvidia GPU card with RTX 4000 series or higher, you can use the text encoder in the FP8 format to save storage space. It is 5 GB instead of 10.
t5xxl_fp8_e4m3fn_scaled.safetensors
Impressive! LTX 0.9.5 takes +- 1 min 16 sec for 4 seconds @30 steps (768×512) on RTX3060 laptop GPU (6GB VRAM). Seriously impressive!
btw, on Colab, the workflow expects the t5xxl file to be in the clip folder rather than the text encoders folder
The two folders should be equivalent.
Hmm, when I put the file in the text encoders folder it wasn’t available in the clip loader node. But when I moved it to the clip folder it was.
Okay, I didn’t link the text_encoder folder in google drive. It is now fixed.
Hi Andrew, I agree LTX 0.9.5 is definitely an improvement in terms of resolution and speed on the previous version. I found it takes about 60 secs to generate an image on Colab L4.
But I struggled to get it to do anything with camera prompts – very hit and miss – and as you say, asking it to do anything complex or, I found, fast moving doesn’t give good results. Nice results on slow scenes, though.
Thanks for reporting the runtime. Surprise that L4 is so much slower than 4090.