
The Hunyuan Video is the one of the highest quality video models that can be run on a local PC. The versatile model supports generating videos from text, direct the video using a reference image, LoRA finetuning, and image-to-video.
The only issue to most users is that it is quite slow. In this tutorial, I will show you how to speed up Hunyuan image-to-video 3 times with minimal loss in quality in ComfyUI.
Table of Contents
Software
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.
Running on Google Colab
If you use my ComfyUI Colab notebook, you don’t need to install the model files. They will be downloaded automatically.
Select the HunyuanVideo models before starting the notebook.

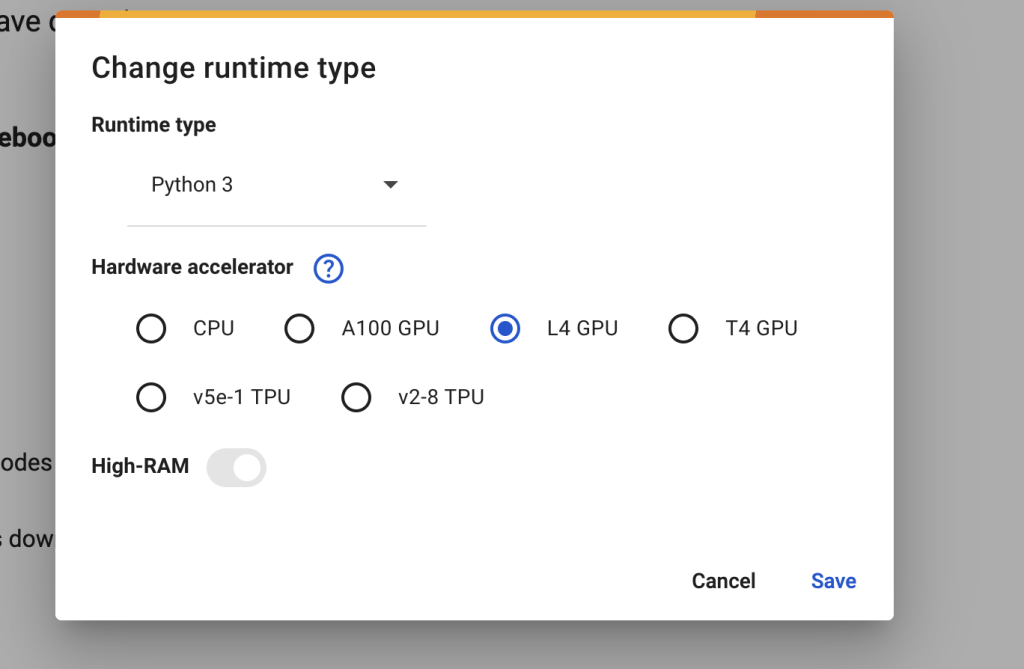
In the top menu, select Runtime > Change runtime type > L4 GPU. Save the settings.
Download the workflow JSON file from this tutorial and drop it to ComfyUI.
Teacache speedup
TeaCache takes advantage of the observation that some neural network blocks don’t do much during sampling. Researchers have recognized that diffusion models generate image outlines in the initial sampling steps and fill in details in the late steps.

TeaCache intelligently determines when to use caches during sampling. It uses the cached output when the current input is similar to that produced the cache. It only recomputes the cache when the input becomes substantially different. You can control how often the cache is recomputed by a threshold value.
Hunyuan image-to-video Teacache
This workflow uses an input image as the initial frame and generates an MP4 video.
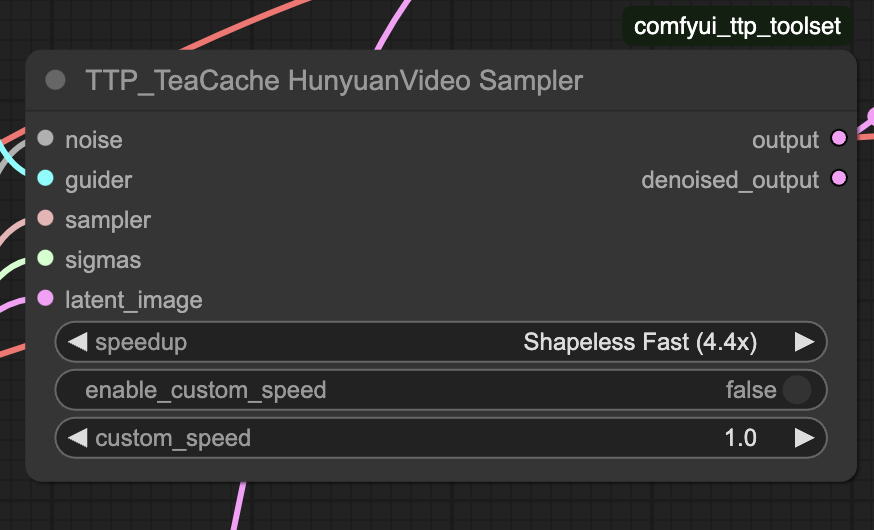
It uses the ComfyUI TTP Toolset to speed up Hunyuan Video. Time to generate a 720p (1280×720 pixels) video on my RTX 4090 (24 GB VRAM) are:
| Teacache Setting | Generation time |
|---|---|
| 1.0x | 16 mins |
| 1.6x | 11 mins |
| 4.4x | 5 mins |
The quality loss is minimal. See the videos generated in different speed-up settings below.
Teacache 1.0x (No speed up):
Teacache 1.6x:
Teacache 4.4x:
Step 0: Update ComfyUI
Before loading the workflow, make sure your ComfyUI is up-to-date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.

Select Update ComfyUI.
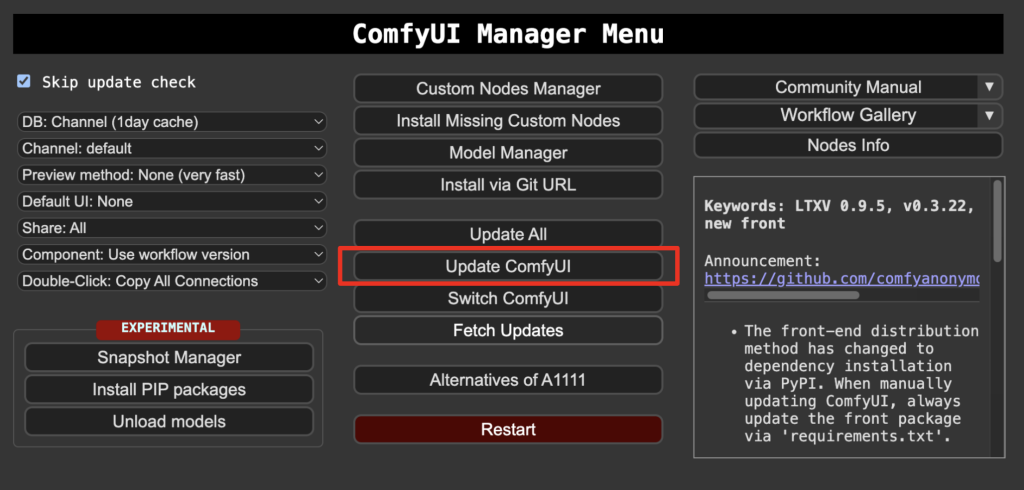
Restart ComfyUI.
Step 1: Download models
You already have these models if you followed my previous Hunyuan image-to-video tutorial.
Download hunyuan_video_image_to_video_720p_bf16.safetensors and put it in ComfyUI > models > diffusion_models.
Download clip_l.safetensors and llava_llama3_fp8_scaled.safetensors. Put them in ComfyUI > models > text_encoders.
Download hunyuan_video_vae_bf16.safetensors and put it in ComfyUI > models > vae.
Download llava_llama3_vision.safetensors and put it in ComfyUI > models > clip_vision.
Step 2: Load workflow
Download the Hunyuan video workflow JSON file below.
Drop it to ComfyUI.
Update: If you experience issues installing the missing nodes, try the following workflow. The only difference is that the Teacache sampling node has a more limited range of speed-up.
Step 3: Install missing nodes
If you see red blocks, you don’t have the custom node that this workflow needs.
Click Manager > Install missing custom nodes and install the missing nodes.
Restart ComfyUI.
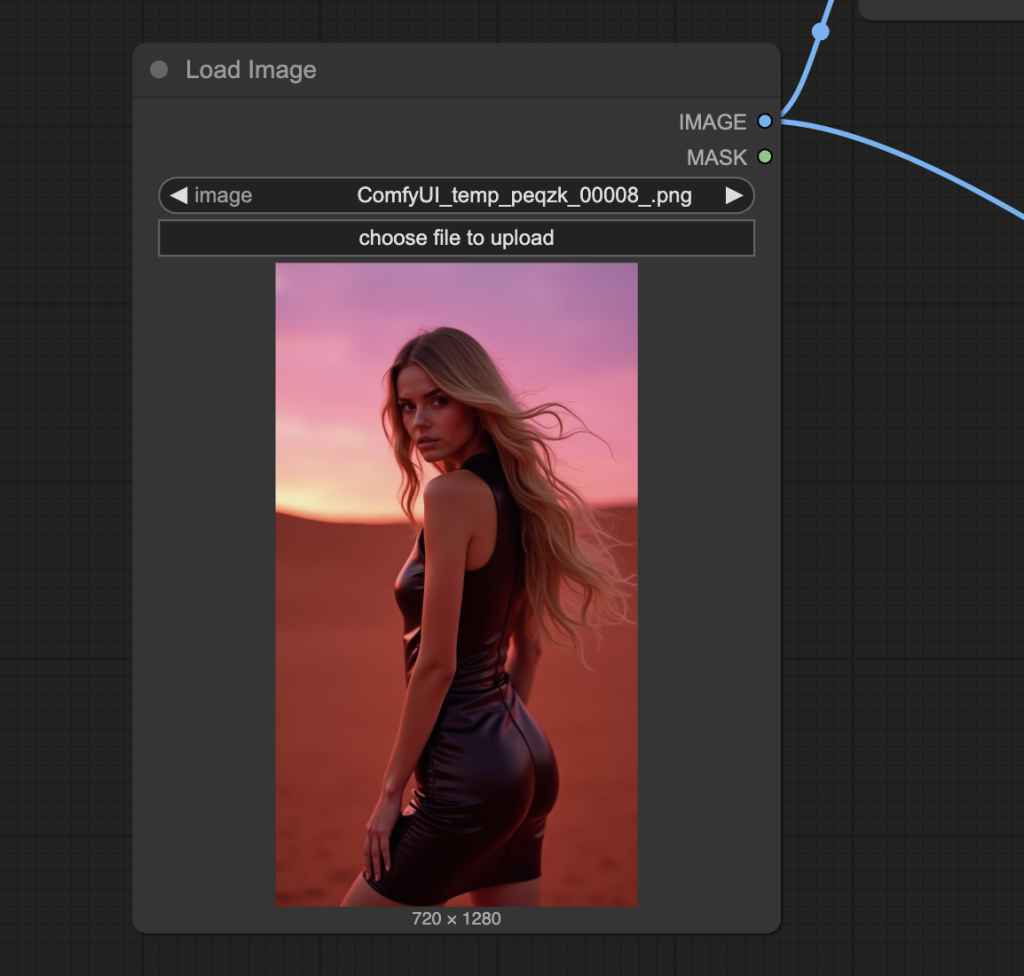
Step 4: Upload the input image
Upload an image you wish to use as the video’s initial frame. You can download my test image for testing.
{kind=link}
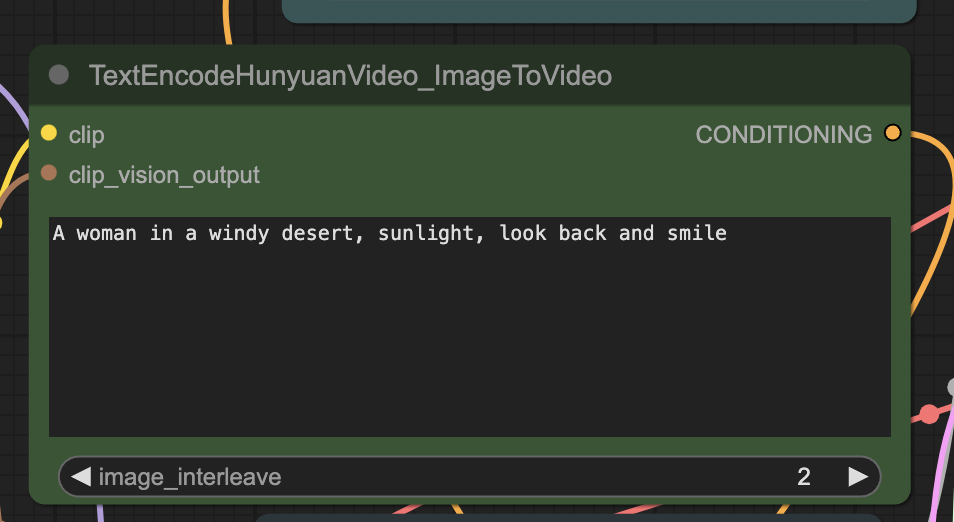
Step 5: Revise prompt
Revise the prompt to what you want to generate.
Step 6: Generate a video
Click the Queue button to generate the video.

Tips
Change the noise_seed value to generate a different video.
If you see quality issues, reduce the speedup value in TeaCache HunyuanVideo Sampler.
Thanks for all the Tutorials and workflows, Andrew. They’re a huge help. One quick question, though. Using this workflow, my 4090 is able to generate up to 113 frames without running out of memory. However, using your older TeaCache HunYuan workflow for Text2Video (found here: https://stable-diffusion-art.com/teacache/), I’m lucky if I can get it to do 73 frames at the same resolution. Any more than that, and I run out of memory.
Are there some memory optimizations that can be added to that older workflow to allow for longer videos to be generated?
Thanks again. Hoping to see a tutorial/workflow for the just released Wan 2.1 FLF2V model soon.
Forgot to include the resolution I’m trying to generate in the above post. Its 512×768.
Thanks for this speed boost, Andrew. On Colab L4 using the Shapeless Fast setting, a length 44 video took under 5 minutes – a huge improvement on the 17 mins previously.
I had to use a fp8 dtype to avoid running out of memory on the video sampler and both the fp8_e4m3fn and fp8_e5m2 worked. But even with fp8, I don’t seem to be able to generate more than length 44 without running out of memory on the sampler. Presumably the quality also suffers with fp8 of this – videos seem less detailed than the Wan2.1 720p model (I’ve not tried the fp8 dtype there yet)
Also, I’ve found videos often appear to be in slow motion. I’ve not changed any settings in the workflow.
Is there anything I can do about to extend the length and speed up the video action?
For video length, it is limited by VRAM. You can try reducing the video resolution to, e.g. 720×720 or lower.
For video speed, you can increase the frame_rate of the video in the Video Combine ndoes.
I tried this with the Colab A100 GPU and wow, what a difference (the GPU memory allocation is 40Gb) – I got 2 sec videos in under 2 minutes!
I added a comfy essentials resize node to keep the input image the right size. I had to experiment with the frame rate to avoid blurry motion in hands and arms while getting a naturalistic speed of motion and 20 or 21 seemed to work most of the time. I also reduced the TeaCache sampler speedup setting by a notch which seemed to help quality.
It’s great to have a fast and high quality open-source video option as an alternative to Kling.
Thanks for reporting. The speed is impressive. Looks like the nodes are moving weights around to fit the model on smaller VRAM.
I updated the manager and also switched versions of TTP toolset from “nightly” to “latest” (not sure the distinction). This didn’t work either. The manager tells me there are 3 conflicts with this TTP Toolset, 2 from “Clothing Migration Kit” and one from “for comfyui image proprocessor”, none of which I have installed. I see the TeaCacheHunyanVideoSampler withing the toolset as number 11 without any conflicts, maybe its in the wong folder? I can click on Comfyui_TTP_Toolset and it takes me to the Github page but I have no idea where to install it manually. COmfyUI is still very new to me and its very confusing
Mmm, I am surprised by the difficulty installing the missing node. I have added an alternative workflow json in the post. See if you are able to install that.
Thank you
Thank you very much, too.
I got it to install just now using the nightly version of TTP Toolset – perhaps it is still being tweaked.
The SAMPLER version does not seem to exist anywhee, I;’ve just spent hours looking for it for another workflow when I stumbled across this page :/
When installing missing nodes in the workflow, I cant seem to install TeaCacheHunyuanVideoSampler. Its not listed in the Manager under nodes.
Searched under Custom Node Manager as well.
Me too.
I installed the comfyui_ttp_toolset cutome node via ComfyUI_Manager, and it seems it is imported successfully, base on the terminal.
However, There’s no “TeaCacheHunyanVideoSampler”
You have installed the correct custom node. The node is called “TTP_Teacache HunyuanVideo Sampler”
The node is called Comfyui_TTP_Toolset.
I tested on a fresh installation of ComfyUI and was able to install through missing nodes. Perhaps updating your comfyui/comfyui manager.