
Low-Rank Adaptation (LoRA) has emerged as a game-changing technique for finetuning image models like Flux and Stable Diffusion. By focusing on adjusting a subset of model parameters, LoRA enables efficient finetuning without the need to retrain the entire model.
For the first time, LoRA has come to a large video model. Now, you can use LoRA to finetune Hunyuan Video.
In this tutorial, I will show you how to use LoRAs with Hunyuan Video. You can use multiple LoRAs to create a consistent character in scenes like the ones below.
Software
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.
How does Hunyuan LoRA work?
A Hunyuan LoRA works like LoRA in Stable Diffusion and Flux. It is a small model file that stores the changes to some parts of the Hunyuan base model. A LoRA file is typically ~100x smaller than the Hunyuan base model.
They are ideal for specific video tasks, such as generating specific objects, styles, and characters.
Use cases
Style transfer
You can add a LoRA to achieve a new style.
Here’s the video from the Hunyuan base model:
Casting the video to an Anime style with the Makoto Shinkai Anime Style LoRA:
Consistent character
You can train a LoRA to put a new face in the Hunyuan Video. If you don’t have the resources to train a LoRA, you can always blend two face LoRAs on CivitAI to create a new one.
For example, we can use the Emma Watson LoRA:
And mix with the Emily Bloom LoRA:
To create a new person Emma-ly…:
By carefully selecting the faces and adjusting the LoRA weights, you can create the consistent face you need.
One LoRA workflow
This workflow uses the ComfyUI-HunyuanVideoWrapper custom nodes with the FastVideo model.
Step 0: Update ComfyUI
Before loading the workflow, make sure your ComfyUI is up-to-date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.

Select Update ComfyUI.
Restart ComfyUI.
Step 1: Download the video model
Download the hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors and put it in ComfyUI > models > diffusion_models.
Google Colab
If you use my ComfyUI Colab notebook, put the model in AI_PICS > models > diffusion_models.
Step 2: Download VAE
Download hunyuan_video_vae_bf16.safetensors.
This VAE file differs from the one released by ComfyUI and is used in the text-to-video tutorial. Rename it to hunyuan_video_vae_bf16-kj.safetensors
Put it in ComfyUI > models > vae.
Google Colab
If you use my ComfyUI Colab notebook, put the model in AI_PICS > models > VAE.
Step 3: Download LoRA model
Download the Makoto Shinkai Anime Style LoRA model. Put it in ComfyUI > models > loras > Hunyuan.
Google Colab
If you use my ComfyUI Colab notebook, put the model in AI_PICS > models > Lora.
Step 4: Load workflow
Download the Hunyuan video workflow JSON file below.
Drop it to ComfyUI.
Step 5: Install missing nodes
If you see red blocks, you don’t have the custom node that this workflow needs.
Click Manager > Install missing custom nodes and install the missing nodes.
Restart ComfyUI.
Step 6: Run the workflow
The LoRA is loaded before the Hunyuan Video base model. It modifies the base model’s weights in memory.
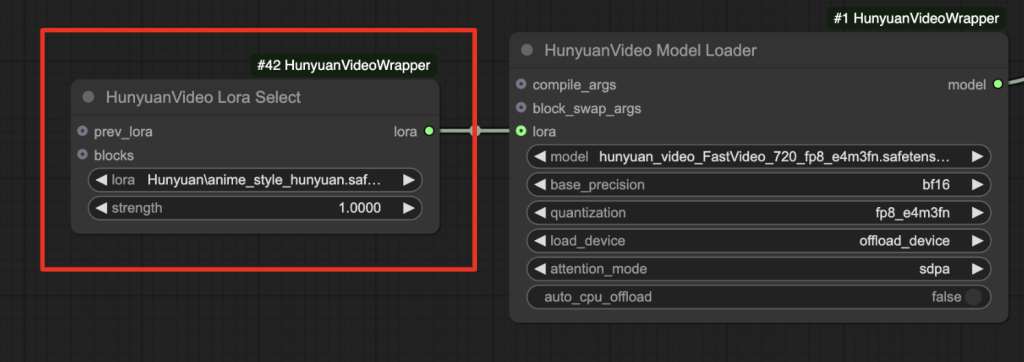
You can optionally revise the prompt. This LoRA needs the trigger keywords “anime style” in the prompt.
Click the Queue button to run the workflow.
You should get this video:
Two-LoRA workflow
A two-LoRA workflow uses two LoRAs to modify the Hunyuan base model. It is an excellent choice for creating a consistent character by blending two faces.
The following steps assume you have completed the setup of the One-LoRA workflow above.
Step 1: Download the LoRA models
Download the Emma Watson Hunyuan video Lora and put it in ComfyUI > models > loras > Hunyuan.
Download the Emily Bloom Hunyuan video Lora and put it in ComfyUI > models > loras > Hunyuan.
Step 2: Run the workflow
Download the JSON workflow file below.
Drop it to ComfyUI.
Click the Queue button to run the workflow.
You should get this video:
Changing the prompt casts the character to a different scene.
When I press Run, I see the following error.
DownloadAndLoadHyVideoTextEncoder
Error no file named pytorch_model.bin, model.safetensors, tf_model.h5, model.ckpt.index or flax_model.msgpack found in directory /Users/pahmed/Documents/GitHub/ComfyUI/models/clip/clip-vit-large-patch14.
looks like the auto download is complete. delete the clip-vit-large-patch14 folder and run again
In both this and the teacache tutorial, I just get a VAE-related error (I’ve done an “update all” from the Manager but no change). I have everything downloaded & installed, and updated. Using Google Chrome on Windows 10.
HyVideoVAELoader
Error(s) in loading state_dict for AutoencoderKLCausal3D:
Missing key(s) in state_dict: “encoder.down_blocks.0.resnets.0.norm1.weight”, “encoder.down_blocks.0.resnets.0.norm1.bias”, “encoder.down_blocks.0.resnets.0.conv1.conv.weight”, “encoder.down_blocks.0.resnets.0.conv1.conv.bias”, “encoder.down_blocks.0.resnets.0.norm2.weight”, “encoder.down_blocks.0.resnets.0.norm2.bias”, “encoder.down_blocks.0.resnets.0.conv2.conv.weight”, “encoder.down_blocks.0.resnets.0.conv2.conv.bias”, “encoder.down_blocks.0.resnets.1.norm1.weight”, “encoder.down_blocks.0.resnets.1.norm1.bias”, “encoder.down_blocks.0.resnets.1.conv1.conv.weight”, “encoder.down_blocks.0.resnets.1.conv1.conv.bias”, “encoder.down_blocks.0.resnets.1.norm2.weight”, “encoder.down_blocks.0.resnets.1.norm2.bias”, “encoder.down_blocks.0.resnets.1.conv2.conv.weight”, “encoder.down_blocks.0.resnets.1.conv2.conv.bias”, “encoder.down_blocks.0.downsamplers.0.conv.conv.weight”, “encoder.down_blocks.0.downsamplers.0.conv.conv.bias”, “encoder.down_blocks.1.resnets.0.norm1.weight”, “encoder.down_blocks.1.resnets.0.norm1.bias”, “encoder.down_blocks.1.resnets.0.conv1.conv.weight”, “encoder.down_blocks.1.resnets.0.conv1.co
… etc.
You used an incorrect VAE. You should redownload the VAE listed on this page and rename it accordingly. Although the filenames are the same, it is not the same file as the one released by the comfyui org.
Oh, I see – I had seen that the names were the same and didn’t re-download. Thank you for the quick reply, the process appears to be working now!
I am struggling to get this to work on colab. Should I be uploading the model to my drive like the vae and lora?
I added instructions for colab.
Thanks for the guides. I wanted to know the difference between this guide with LORAs and the other guide without Loras. As you mentioned this is using FastVideo FP8 and vae is different too. But is it possible to add Loras to the other guide or use bf16 model with this. The workflow nodes are quite different too.
No, the other guide uses comfyui’s native nodes. This one uses custom nodes. I think this custom nodes support a bf16 model. You may need to follow their README doc and download it.
To remove the LoRA, remove or disable the lora node.
Thank you for this thorough writeup and for the json workflow – huge help and very satisfying to be able to get this to run on Google Colab.
I have a Colab Pro plan and when attempting to generate a video that is 121 frames (24fps), 720×480, 1 lora, using the model + VAE you mentioned, it is taking approximately ~25 minutes per video on a A100 in Colab – is that to be expected? I would’ve thought the A100 would be churning these out in ~6 minutes or so. Any guidance on speeding this up would be appreciated if I perhaps have something configured incorrectly.
A100 is for training or massive generation. L4 should be a more cost effective option.
Unfortunately, the L4 runs out of memory (has happened pretty much every time) — Even without a lora in the workflow.
You can reduce the video size or length
Hi, I’ve drop Emma Watson Hunyuan video JSON workflow file to my desktop ComfyUI, but why i can’t search any missing nodes in custom nodes manager, missing custom nodes and model manager, when i drop the JSON file.
Make sure your comfyui and manager are up-to-date. Sometimes the manager cannot update itself…
unfortunately I just get this error: HyVideoModelLoader.loadmodel() got an unexpected keyword argument ‘lora’
looks like you need to update the nodes.
Thanks for sharing this article on how to use LoRA with Hunyuan, can’t wait to get stuck into it once I’ve got free time later today!
Are there any plans to share any tutorials or resources for creating LoRA that can be used as well?
I’m liking what I’ve created so far, but would love to bring some of my characters that I’ve created for SDXL, Flux, Pony, SD3.5 into this as well so that I can continue to explore it all.
Yes, I am planning to create a colab notebook for training.
Just curious, any update on the LoRa notebook?
Coming soon.