
LTX Video is a fast, local video AI model full of potential. The Diffusion Transformer (DiT) Video model supports generating videos from text alone or with an input image. The model is small, with only 2 billion parameters. As a result, it only requires 6 GB VRAM and generates a 4-second video in 20 secs on RTX4090. The quality is surprisingly good for its size.
In this article, I will show you how to set up and run LTX Video in ComfyUI with text-to-video and image-to-video modes.
Table of Contents
Software
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.
LTX Text-to-video
This text-to-video LTX-Video workflow turns a text prompt into an mp4 video. The default video size is 768×512.
Step 0: Update ComfyUI
Before loading the workflow, make sure your ComfyUI is up-to-date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.

Select Update ComfyUI.
Restart ComfyUI.
Step 1: Download models
Download the LTX checkpoint model and put it in ComfyUI > models > checkpoints.
Download the T5XXL text encoder and put it in ComfyUI > models > clips.
Note: If you use my ComfyUI Colab Notebook, you don’t need to download the models. Simply select LTX before launching the notebook.

Step 2: Load workflow
Download the following workflow JSON file and drop it to ComfyUI.
Step 3: Install missing custom nodes
You may not have all the custom nodes in this workflow. If you see red boxes, click Manager > Install missing custom nodes.
Restart ComfyUI.
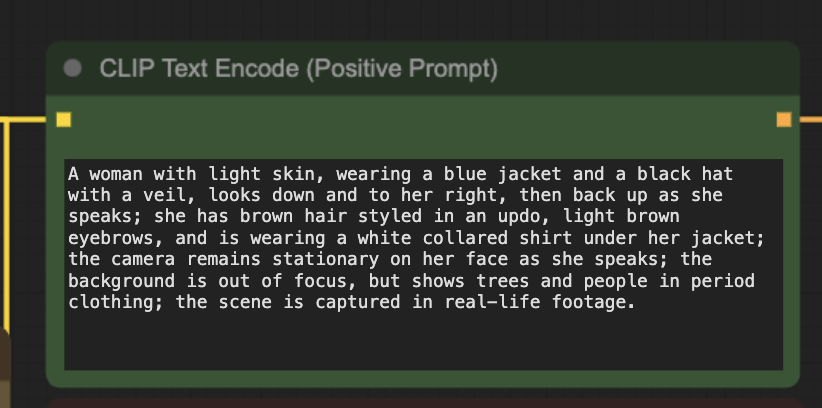
Step 4: Revise the prompt
Write a description of the video you want to generate.
Step 5: Generate a video
Click Queue to generate a video.
LTX Image-to-video
An image-to-video workflow takes an input image and a text prompt to generate a video.
However, if you use ComfyUI’s default image-to-video LTX video workflow, you will find the generated videos lack motion. Discussions on Reddit pointed to the model being trained with videos with motions, so images that are a bit blurry work best. I tested two methods suggested in the thread: (1) Compress the image to a single frame video to reduce its quality, and (2) Slightly blur the input image. The first method works better and is what I used in the following workflow.
Step 1: Download models
Follow the text-to-image section to download models.
Step 2: Load workflow
Download the image-to-video workflow below and drop it to ComfyUI.
Step 3: Upload an input
Upload an input image to the Load Image node. You can use the image below.

Step 4: Revise prompt
Write a prompt that matches the input image plus some motion.
Step 5: Generate video
Click Queue to generate a video.
Tips for using LTX-Video model
- Long prompt works better for LTX-video. Write more to describe the scene and the camera motion.
- Seed value matters. If a video doesn’t look good, try a different seed value.
Related workflows
Further readings
- Lightricks/LTX-Video: Official repository for LTX-Video
- NEW VIDEO MODEL: LTXV day-1 Native Support in ComfyUI
great guide. How to set the length of the video ? I provided an image and the outputs is 0.1 seconds which is practically an image.
Change the length in the EmptyLTXVLatentVideo node. The default setting should generate a ~3.5 second video.
does it work without dedicated GPU and with only CPU 16GB RAM?
It could but I haven’t tried.
Yup, ran LTX 0.9.6 on i5 CPU and 16GB RAM. Took about 10 mins for 10 steps with the dev version and results looked real good. I tried the distilled version as well (8 steps), it was slightly faster but I found the speed vs quality trade-of wasn’t really worth it in a CPU only environment. On my GPU PC it’s a whole other beast though 🙂 You can also try running the new 0.9.6 distilled version as well as that is 8 steps. I tried it but found that dev version produced slightly better results at 10 steps. Lemme know if you need help running on CPU.
Thanks Andrew, I’d been using the SwarmUI front end but used the Comfy workflow backend within Swarm instead. The difference was like night and day!
Thank you for the detailed setup instructions. Everything seems to work except that my results (txt2video or img2video) looks like this:
https://youtu.be/bND2C8s-5gs
I’m on a Mac (apple silicone), no generation errors in the python console. Please let me know if there’s something you could suggest?
Mmm… its likely due to compatibility with mac.
What do you prefer now – gen by LTX or Mochi?
LTX because of faster iteration 🙂
Ok, now I expect review about Hunyaun gen from you.
You read my mind!