
Wan 2.2 is a high-quality video AI model you can run locally on your computer. In this tutorial, I will cover:
- Using the high-quality Wan 2.2 14B video model
- Using the fast Wan 2.2 5B video model
- Prompt tips for Wan 2.2 models
Table of Contents
Software needed
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.
ComfyUI Colab Notebook
If you use my ComfyUI Colab notebook, you don’t need to download the model as instructed below. Select the Wan_2_2 model before running the notebook.

Text-to-video with the Wan 2.2 14B model
This workflow generates a video based on a text prompt. It requires 20 GB VRAM and takes about 50 minutes on an RTX4090 GPU card.
Step 0: Update ComfyUI
Before loading the workflow, make sure your ComfyUI is up to date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.

Select Update ComfyUI.
Restart ComfyUI.
Step 1: Load the workflow
Download the workflow below.
Step 2: Download models
After loading the workflow JSON file, ComfyUI should prompt you to download the missing model files. Here are what you need to download:
- Download wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors and put it in ComfyUI > models > diffusion_models.
- Download wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors and put it in ComfyUI > models > diffusion_models.
- Download umt5_xxl_fp8_e4m3fn_scaled.safetensors and put it in ComfyUI > models > text_encoders.
- Download wan_2.1_vae.safetensors and put it in ComfyUI > models > vae.
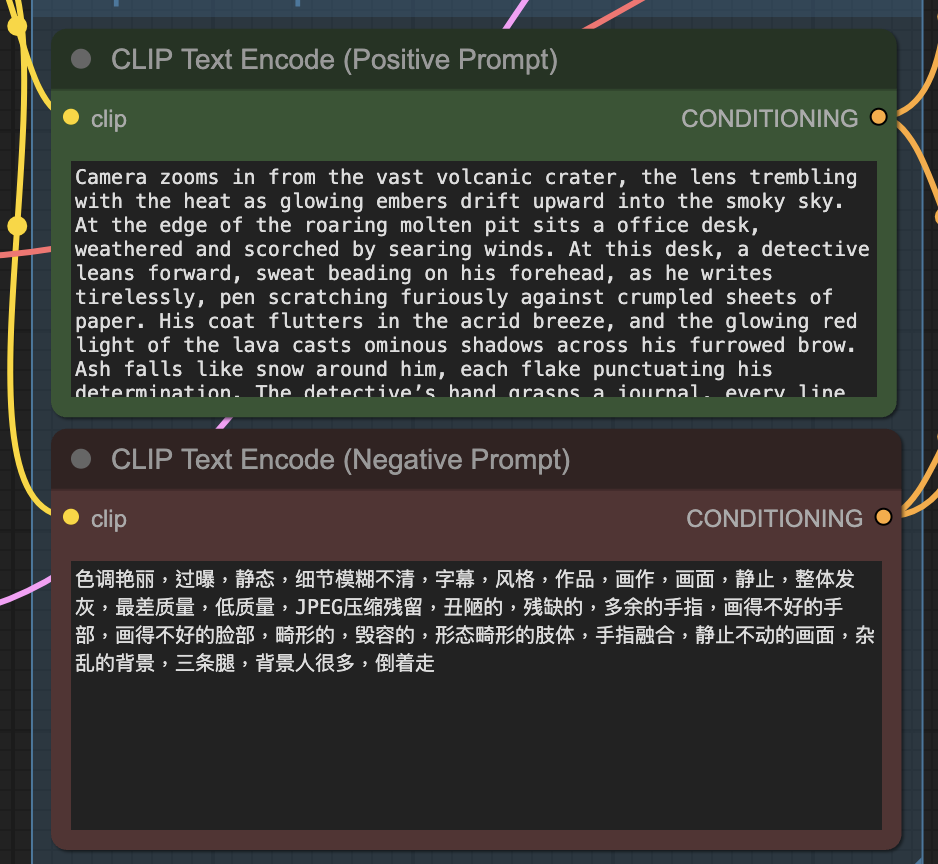
Step 3: Revise the prompt
Describe your video in the prompt. Use keywords to direct the camera.
Step 4: Generate the video
Click the Run button to run the workflow.

Text-to-video with the Wan 2.2 5B model
This workflow turns an input image into a video. Unlike the 14B model, this smaller 5B model requires only 8 GB VRAM and takes about 6 minutes on an RTX4090 GPU card.
Step 1: Download the workflow
Download the workflow below and drop it into ComfyUI to load.
Step 2: Install models
Here are the model files you need to install:
- Download wan2.2_ti2v_5B_fp16.safetensors and put it in ComfyUI > models > diffusion_models.
- Download umt5_xxl_fp8_e4m3fn_scaled.safetensors and put it in ComfyUI > models > text_encoders.
- Download wan2.2_vae.safetensors and put it in ComfyUI > models > vae.
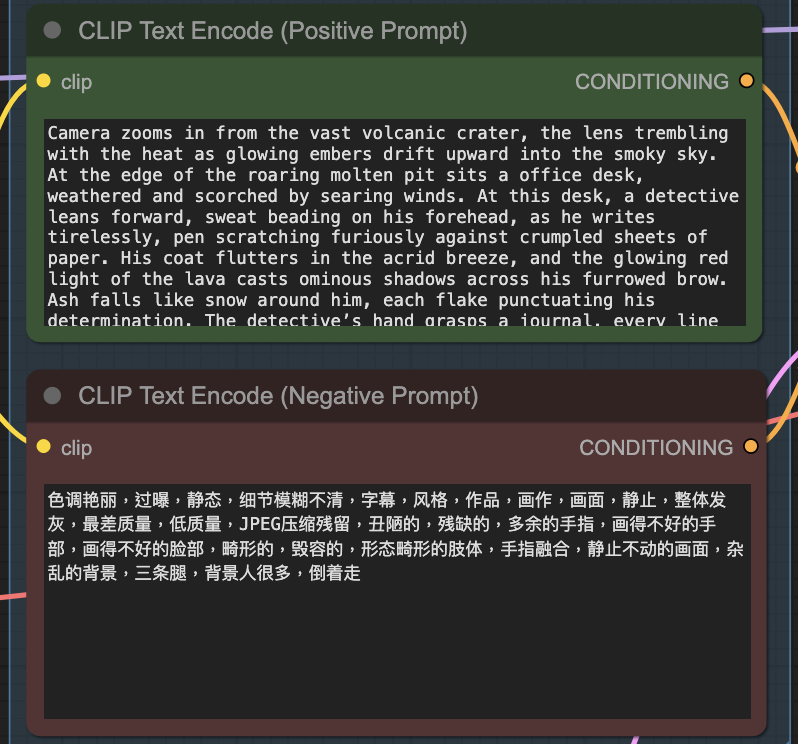
Step 3: Revise the prompt
Describe your video in the prompt. Use keywords to direct the camera.
Step 4: Generate the video
Click the Run button to run the workflow.
Prompt tips for Wan 2.2
Compared to the image-to-video workflow, it is much easier to direct Wan 2.2 videos in the text-to-video mode. Due to generation time,
Camera motion
Useful keywords are:
- Zoom in/out
- Lens trembling
- Pan left/right
- Tilt up/down
- Dolly in/out
- Orbital arc
- Crash zoom
- Track upward/downward
Zoom in
Zoom in is easier to use for adding camera movement.
Prompt:
Camera zooms in from the vast volcanic crater, the lens trembling with the heat as glowing embers drift upward into the smoky sky. At the edge of the roaring molten pit sits a office desk, weathered and scorched by searing winds. At this desk, a detective leans forward, sweat beading on his forehead, as he writes tirelessly, pen scratching furiously against crumpled sheets of paper. His coat flutters in the acrid breeze, and the glowing red light of the lava casts ominous shadows across his furrowed brow. Ash falls like snow around him, each flake punctuating his determination. The detective’s hand grasps a journal, every line and margin filled with cryptic clues and hastily drawn schematics. Occasionally, he pauses to stare into the churning fire below, lost in thought, before dipping his pen back into the inkwell, fingers smudged with charcoal dust. The camera’s focus shifts from his intense eyes to the swirling patterns of molten rock behind him, then back to the rhythmic motion of his hand, creating a dance. The scene crackles with tension: danger lurks in every thundering eruption, yet the detective remains undeterred, driven by a pursuit of truth in the heart of the smoldering inferno.
Zoom out
The model responds to zoom out better when you first describe a close-up scene. For example:
Extreme close-up on a painter’s fine brush etching vibrant color on a masterpiece. Zoom out gradually to reveal the beatuiful and trendy female artist in a dimly lit dated art studio.
Crash Zoom
Crash Zoom is a filming technique that the camera zooms in quickly.
Wide angle view of a confident young blonde woman in a sunlit urban plaza, standing atop a low wall. Crash zoom suddenly into her determined face as she flips her hair.
Track upward
Use “Track upward” to move the camera up.
close-up on the hero’s armored boot pressing into a rusted seam. Track upward along his blue-plated leg as he steadies himself, revealing his chest armor and youthful face.
Composite video
We have used this technique in a previous prompt example. The trick is to describe one scene, followed by a different one connected with a camera motion. For example:
Opening shot is a close-up on a delicate, antique music box’s spinning ballerina figure, its metal edges tarnished by time.
Zoom out Pull back to reveal an elderly woman’s trembling hands winding the key, then further to show her seated alone in a dusty attic illuminated by a single shaft of sunlight through a cobwebbed window.
Scene quality
Modify the scene quality to match what your message. The model supports concepts like
- anamorphic lens flare
- HDR high contrast
- 35mm film grain
- Soft focus
35mm film grain
Prompt:
A lone traveler walking along a misty forest path at dawn. Camera cranes down from treetops to meet the traveler’s head height, then tracking shot behind them as they move forward. Soft backlight through fog, ethereal color palette, delicate 35mm film grain for a dreamy, storybook mood.
Silhouette photography
Silhouette photography, place a lone guitarist standing knee-deep in surf, facing the ocean at dusk. Close in on the guitar’s headstock and the player’s bowed head in silhouette. Slowly zoom out to reveal crashing waves, a pastel sky, and seabirds tracing the horizon.
Animation styles
The model supports animation styles:
- 3D animation style
- Disney cute character style
- Japanese anime style
Prompt:
3D animation disney cute character style, in a theater with red drapes and golden trim, a magician in a midnight-blue tailcoat and top hat stands under a spotlight. He reaches into a silver cylinder and produces a surreal pipeapple, exhaling smoke that swirls like colorful ribbons.
Fantasy content
Like Stable Diffusion, the Wan 2.2 model is quite good at generating imaginary scenes. Let your imagination runs wild and Wan 2.2 will help you visualize it!
close up shoot, Under a vast azure sky, a red-haired woman was smiling and laughing joyfully. Her long, curly tresses dance in the breeze. A large-brimmed straw hat, slightly drooping at the edges, crowns her head. On a rural path blanketed in golden hay, expansive fields and a pristine blue horizon form the backdrop. With hands aloft, she wields a blue garden hose from which a cascade of colorful little birds erupts, scattering like fireworks in the air. The blossoms, diverse in hue and shape, gleam with a gentle luster under the sun’s rays.
You can also find some good prompts for imaginary scenes on the Wan 2.2 website.
Additional tips
- Character size: Like text-to-image models, the Wan 2.1 text-to-video model does not perform well with small details. You should try to create characters that are large enough so that their faces are covered by many pixels.
- Camera control: Compared to the image-to-video mode, the video in text-to-video mode has more freedom to create motions. Stick with text-to-video with you want to have create specific camera motion.
Useful links
Wan2.2 Day-0 Support in ComfyUI – Release press from ComfyUI
Wan-Video/Wan2.2 – Github page hosting the source code
Wan-AI/Wan2.2-T2V-A14B · Hugging Face – Model weights of the 14B T2V model
Wan-AI/Wan2.2-TI2V-5B · Hugging Face – Model weights of the 5B T2V model
Wan2.2 Video Generation – ComfyUI’s official documentation
What is the purpose of the ModelSamplingSD3 node?
It is more a technicality when using the Wan 2.2 model. It is a flow-based model so the sampling method needs to be revised. This node updates the sampling method so that it is compatible with the Wan 2.2 model.
Thanks for the clear WAN 2.2 guide! I ran your ComfyUI workflow (added a small branch to save thumbnails from the video—ImageFromBatch → SaveImage) and ended up writing two tiny helpers for anyone batch-running queues:
• reframe_queue_and_prefixes.py — changes the video frame length across the graph and fixes the UI metadata so the node shows the new length; also updates SaveVideo/SaveImage filename prefixes so “-###f” matches the new frame count.
• reseed_queue.py — batch-reseed all KSampler inputs.seed values (random with –rng-seed, or incrementing patterns; can limit to queue_pending).
Tested on Windows 11 with RTX 4070 and 3070. I used ChatGPT to help me code these, but they’re working great on my boxes.
Repo: https://github.com/HelloJessicaM/ComfyUI-Saved-Queue-Tools/tree/main
Hope this helps someone else batch and iterate faster!
— Jessica
Thanks for sharing!
Thanks, Andrew. It seems my browser – Firefox – is the problem as the videos load ok in Edge and Chrome but not in Firefox and a hard reload deosn’t help
I tried the 5B model a few days ago and wasn’t impressed with the results – although it was quick, there seemed to be lots of flashing errors and erratic movements. However, Wan2.2 14B works very well so far and I will experiment further with camera instructions. Wan2.1 14B is a lot quicker, though.
I have the problem as the videos loading in Chrome.
Thanks, Andrew. The Colab notebook only appears to load the 14B versions of the i2v and t2v models, not the 5B ones. Also, a lot of the videos on this page have error messages saying the files are corrupt. Sorry!
Sorry for the delay. The 5B model is added.
The videos are loading on my side. Perhaps they were not cached probably. You can try a hard reload.