
The Hunyuan Video model has been a huge hit in the open-source AI community. It can generate high-quality videos from text, direct the video using a reference image, and modify the model with LoRA.
It only missed the image-to-video function like the LTX image-to-video. The good news is that the Hunyuan Image-to-Video model is now available! Read on to learn the model details and a step-by-step guide to use it.
Table of Contents
Software
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.
Running on Google Colab
If you use my ComfyUI Colab notebook, you don’t need to install the model files. They will be downloaded automatically.
Select the HunyuanVideo models before starting the notebook.

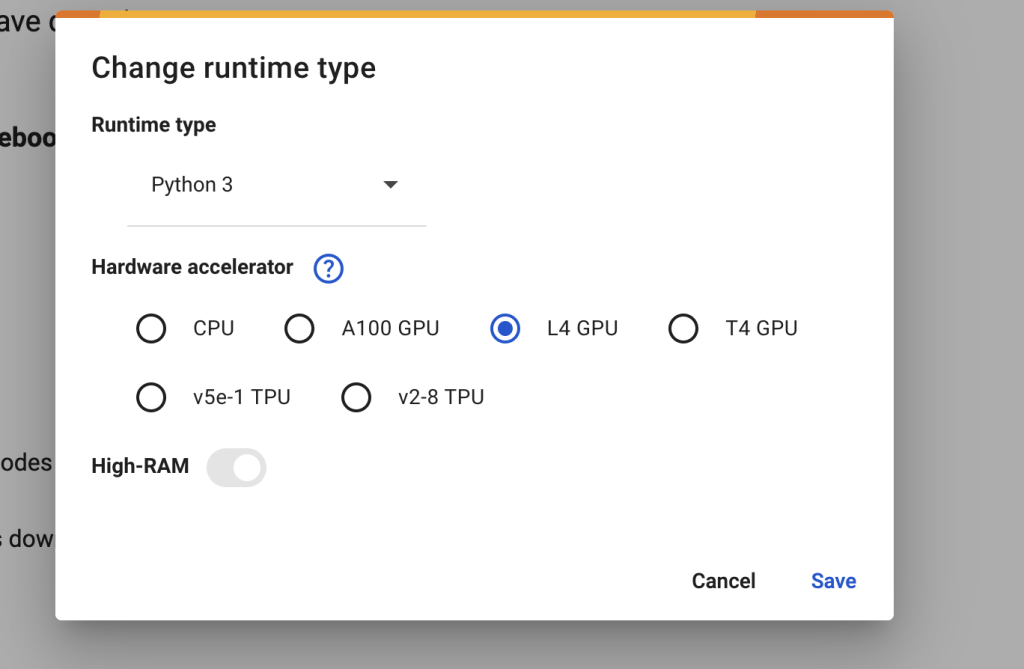
In the top menu, select Runtime > Change runtime type > L4 GPU. Save the settings.
Download the workflow JSON file from this tutorial and drop it to ComfyUI.
Model details
The Hunyuan image-to-video model has the following features.
- Latent concatenation: The Multimodal Large Language Model (MLLM) extracts the semantic tokens from the input image, which are then concatenated with the latent video latents. This ensures the model faithfully uses the information from the input image during video generation.
- Multimodal full attention: The text, image, and video tokens interact through a full-attention mechanism.
- Synergy of Modalities: The interaction of these modalities enhances visual fidelity and interprets the inputs effectively.
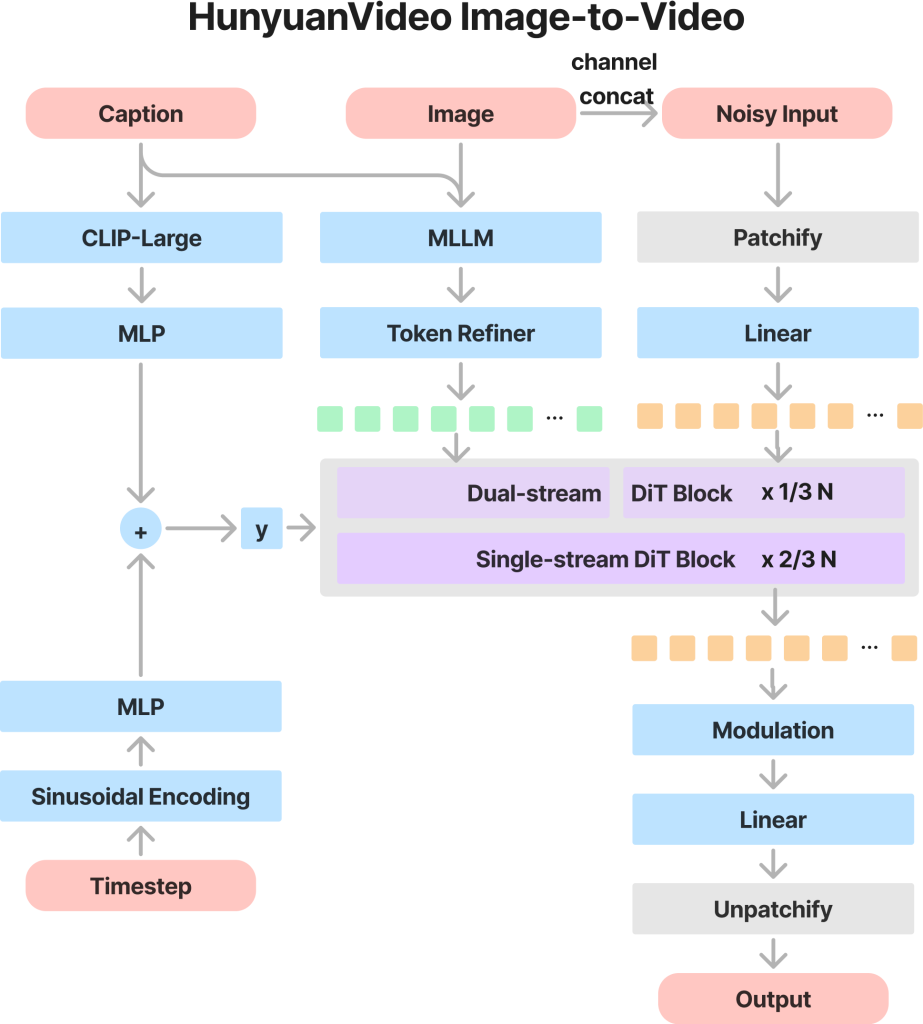
Hunyuan image-to-video workflow
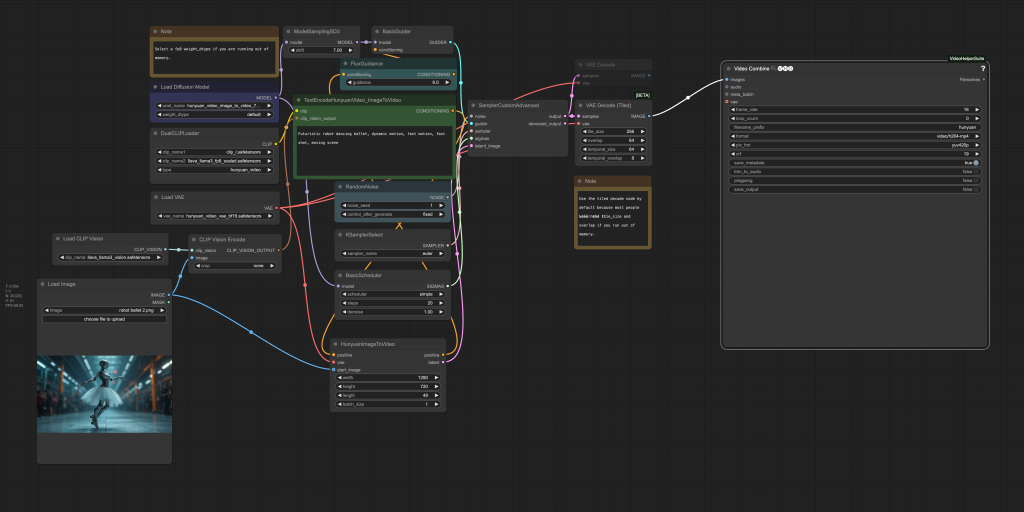
This workflow uses an input image as the initial frame and generates an MP4 video.
It takes about 8 mins to generate a 720p (1280×720 pixels) video on my RTX 4090 (24 GB VRAM).
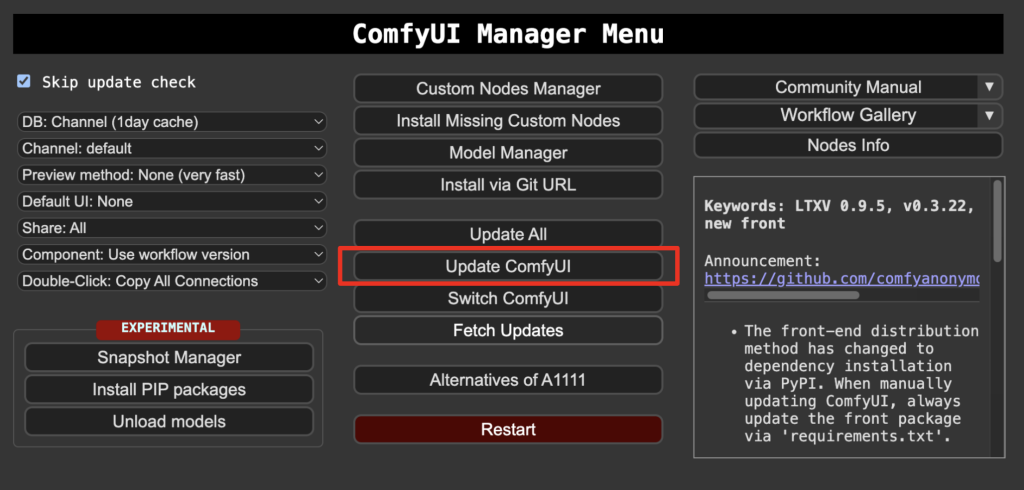
Step 0: Update ComfyUI
Before loading the workflow, make sure your ComfyUI is up-to-date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.

Select Update ComfyUI.
Restart ComfyUI.
Step 1: Download models
You have some of these models if you have installed the Hunyuan Video text-to-image model.
Download hunyuan_video_image_to_video_720p_bf16.safetensors and put it in ComfyUI > models > diffusion_models.
Download clip_l.safetensors and llava_llama3_fp8_scaled.safetensors. Put them in ComfyUI > models > text_encoders.
Download hunyuan_video_vae_bf16.safetensors and put it in ComfyUI > models > vae.
Download llava_llama3_vision.safetensors and put it in ComfyUI > models > clip_vision.
Step 2: Load workflow
Download the Hunyuan video workflow JSON file below.
Drop it to ComfyUI.
Step 3: Install missing nodes
If you see red blocks, you don’t have the custom node that this workflow needs.
Click Manager > Install missing custom nodes and install the missing nodes.
Restart ComfyUI.
Step 4: Upload the input image
Upload an image you wish to use as the video’s initial frame. You can download my test image for testing.
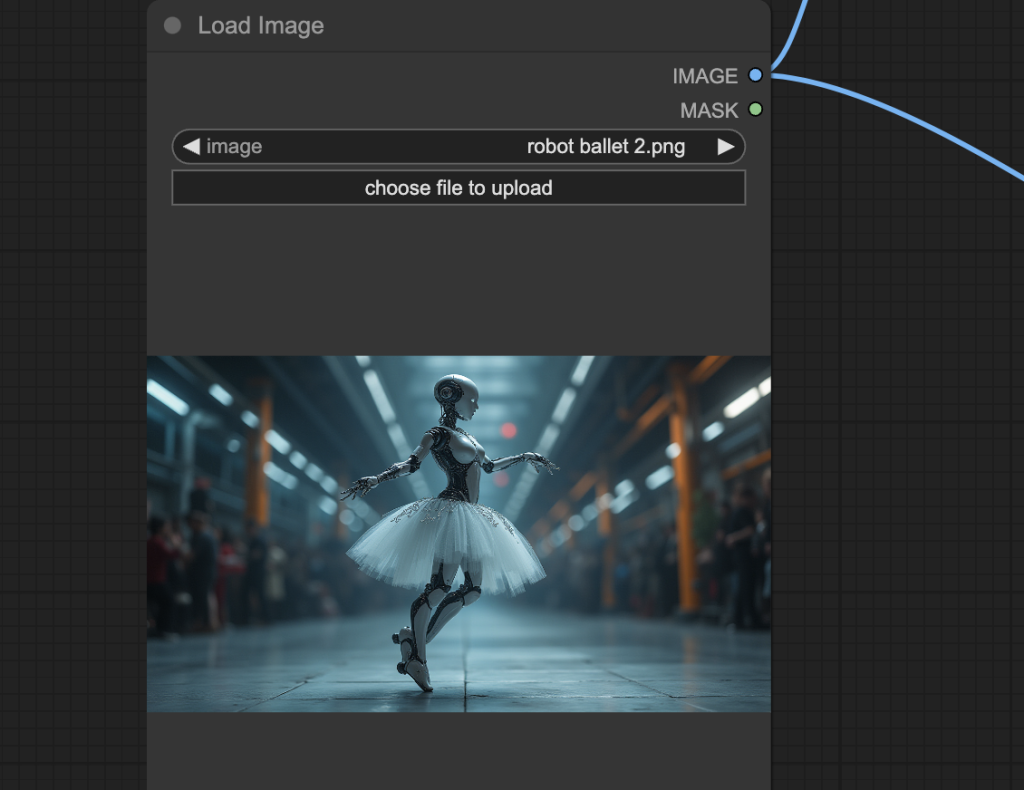
{kind=link}
Step 5: Revise prompt
Revise the prompt to what you want to generate.
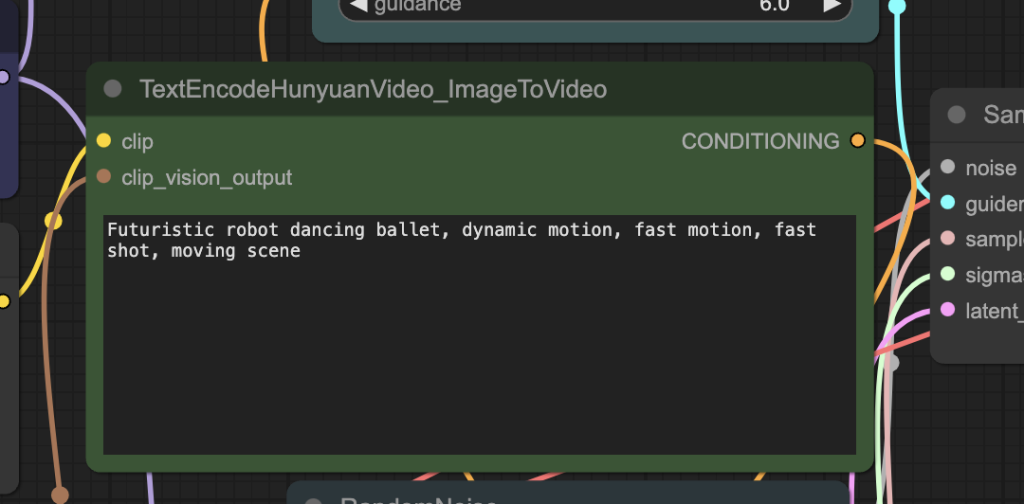
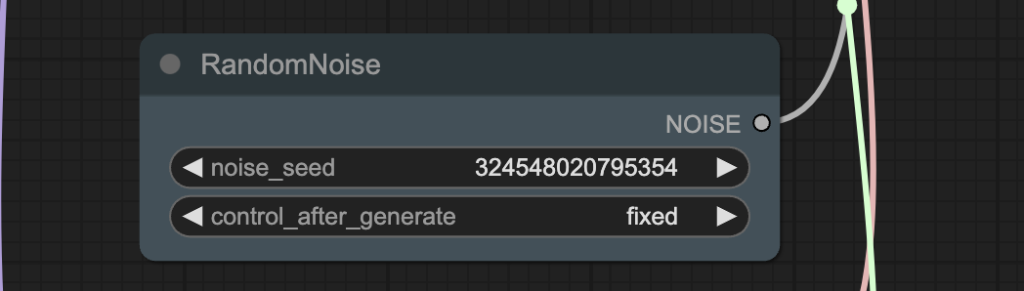
Step 6: Generate a video
Click the Queue button to generate the video.

Tips: Change the noise_seed value to generate a different video.
Reference
ComfyUI Blog: Hunyuan Image2Video: Day-1 Support in ComfyUI!
tencent/HunyuanVideo-I2V · Hugging Face
I’m on an Apple M2 Max with 96 GB of memory – and this doesn’t work. For Apple Silicon anything that utilizes bf16 does not work. You must use fp16. But the models you provide links to will not work.
correct, bf16 is not supported on Mac. However, it is super slow to run the fp16 version on Mac.
Error: Sizes of tensors must match except in dimension 0. Expected size 750 but got size 175 for tensor number 1 in the list.
Why? I set the image size to 512×512, but that shouldn’t matter should it?
Same problem here.
I narrowed it down to the llava_llama3_vision clip_vision model.
It does work with the clip_vision_h clip_vision model.
Nice results with fluid motion and quite good resolution. It takes about 17 mins to generate a length 49, 720p video on Colab L4 so rather slowww…
Thanks for making this step-by-step tutorial, but it doesn’t work for me (like literally every workflow I’ve tried other than the ones you make!) I double-checked all the required files and their locations.
I’m using the windows portable version, and I’ve updated it as well as python dependencies via the update_comfyui_and_python_dependencies.bat script, but when I run it the server disconnects somewhere between the Load Diffusion Model node and the TextEncodeHunyuanVideo_ImageToVideo node. It looks like the error is “clip missing: [‘text_projection.weight’]” but I don’t see any corresponding input in the nodes.
terminal output:
Starting server
To see the GUI go to: http://127.0.0.1:8188
FETCH ComfyRegistry Data: 5/57
FETCH ComfyRegistry Data: 10/57
FETCH ComfyRegistry Data: 15/57
FETCH ComfyRegistry Data: 20/57
FETCH ComfyRegistry Data: 25/57
got prompt
Using pytorch attention in VAE
Using pytorch attention in VAE
VAE load device: cuda:0, offload device: cpu, dtype: torch.bfloat16
FETCH ComfyRegistry Data: 30/57
missing clip vision: [‘visual_projection.weight’]
Requested to load CLIPVisionModelProjection
loaded completely 9827.8 621.916015625 True
Using scaled fp8: fp8 matrix mult: False, scale input: False
CLIP/text encoder model load device: cuda:0, offload device: cpu, current: cpu, dtype: torch.float16
clip missing: [‘text_projection.weight’]
FETCH ComfyRegistry Data: 35/57
FETCH ComfyRegistry Data: 40/57
FETCH ComfyRegistry Data: 45/57
FETCH ComfyRegistry Data: 50/57
FETCH ComfyRegistry Data: 55/57
FETCH ComfyRegistry Data [DONE]
[ComfyUI-Manager] default cache updated: https://api.comfy.org/nodes
nightly_channel: https://raw.githubusercontent.com/ltdrdata/ComfyUI-Manager/main/remote
FETCH DATA from: https://raw.githubusercontent.com/ltdrdata/ComfyUI-Manager/main/custom-node-list.json [DONE]
[ComfyUI-Manager] All startup tasks have been completed.
Requested to load HunyuanVideoClipModel_
loaded completely 9150.75703125 7894.8529052734375 True
Requested to load AutoencoderKL
loaded completely 769.123649597168 470.1210079193115 True
I:\ComfyUI_windows_portable>pause
Press any key to continue . . .
what’s your gpu card? A possibility is your card doesn’t support bf16
I’m using a 12GB RTX 3060. On closer examination I think it’s blowing up when trying to load the model hunyuan_video_image_to_video_720p_bf16.safetensors.
I notice that the other model (Txt2V) I’ve been using successfully is about 12 GB but this one is 25, so I’m guessing it’s a VRAM/RAM issue, but there’s no error message.
3060 doesn’t support models in bf16 format. You can try find a fp16 version. But yeah, the VRAM will likely be a problem.
The workflows for Hunyuan are all either missing nodes that ComfyUI no longer offers in the download manager (TextEncodeHunyuanVideo_ImagetoVideo; HunyuanImagetoVideo from the Hunyuan img2vid.json workflow from your other Hunyuan tutorial) or uses a node (Hunyuanvideo TextEncoder from the Hunyuan-Video-ipv.son workflow above & the hunyuan-video-wrapper-txt2img-fastvideo-lora.json workflow) that ignores other already downloaded models that are listed as part of this tutorial. The Text Encode models this tutorial recommends that are no longer recognized are clip_l.safetensors and llava_llama3_fp8_scaled.safetensors. Is there a way to find those old nodes from the img2vid.json workflow so I don’t have to go through the autodownloader from the workflow on this tutorial?
My Mistake. I was using the portable program. Although you can update ComfyUI from the manager, it doesn’t seem to actually update to the newest version. I downloaded the install version and everything works.
Where did you find TextEncodeHunyuanVideo_ImagetoVideo; HunyuanImagetoVideo? Can you please guide me through? In manager there are no such nodes to download :/
its an native node. You just need to update comfyui.
What do you mean the install version? For comfyui or Hunyuan? I am using colab notebook and I have all the files where they are supposed to be but it is giving me an issue in dualcliploader node and updates do not seem to work or fix it.