
WAN 2.1 VACE (Video All-in-One Creation and Editing) is a video generation and editing AI model that you can run locally on your computer. It unifies text-to-video, reference-to-video (reference-guided generation), video-to-video (pose and depth control), inpainting, and outpainting under a single framework.
VACE supports the following core functions:
- Reference-to-Video (R2V): Generate a video sequence from reference images.
- Video-to-Video (V2V): Apply style transfer to an existing video.
- Masked Video Editing (MV2V): Inpaint or outpaint specific regions within each frame.
This tutorial covers the Wan Vace Video-to-Video (V2V) workflow on ComfyUI, which:
- Copy the movement of a person in the reference video. (via OpenPose control)
- Copy the face and clothing of a person in the reference image.
Here’s the reference video and reference image.
{kind=link}
Table of Contents
Software
We will use ComfyUI, a free AI image and video generator. You can use it on Windows, Mac, or Google Colab.
Think Diffusion provides an online ComfyUI service. They offer an extra 20% credit to our readers.
Read the ComfyUI beginner’s guide if you are new to ComfyUI. See the Quick Start Guide if you are new to AI images and videos.
Take the ComfyUI course to learn how to use ComfyUI step by step.
Generation time
This workflow takes 50 minutes to generate a 3.3-second 608 x 1088 clip on my RTX4090. Reducing the resolution to 720 x 720 reduces the generation time to 23 minutes.
Google Colab notebook
My ComfyUI Google Colab notebook supports running this workflow. It comes in handy if you don’t have a fast GPU card.
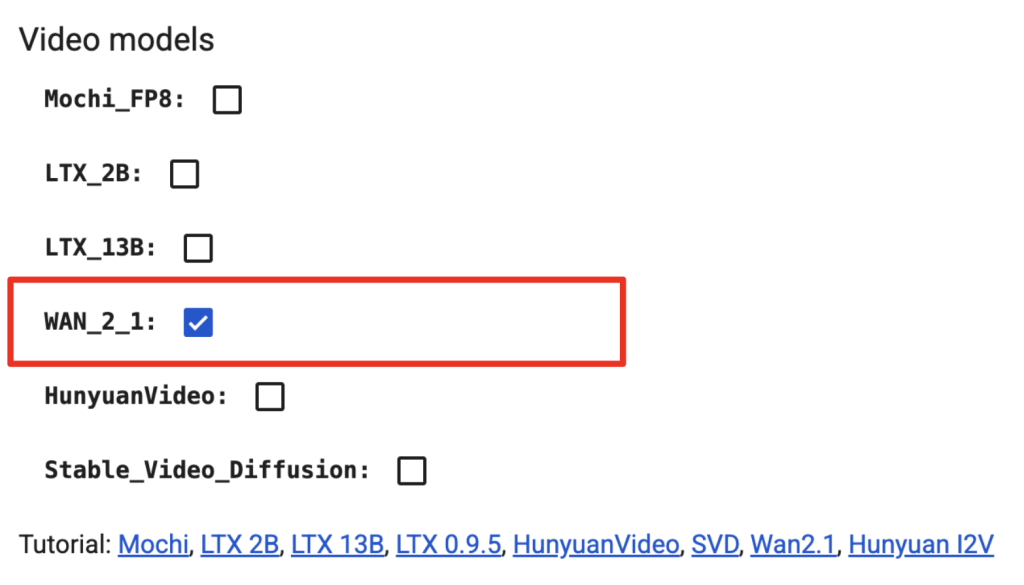
If you use it, you can select L4 or A100 (fast) GPU to run this workflow. Select Wan 2.1 under Video models and skip the model download step below.
Other Wan 2.1 workflows
- Wan VACE Reference-to-video
- Wan 2.1 Text-to-Video: Generate a video based on the text prompt.
- Wan 2.1 Image-to-Video: Generate a video with the initial frame’s image.
- Speeding up Wan 2.1 with Teacache and Sage Attention
- Flux-Wan 2.1 video workflow (ComfyUI)
- Flux-Wan 2.1 four-clip movie (ComfyUI)
Wan 2.1 VACE video-to-video
Step 1: Update ComfyUI
Before loading the workflow, make sure your ComfyUI is up-to-date. The easiest way to do this is to use ComfyUI Manager.
Click the Manager button on the top toolbar.

Select Update ComfyUI.
Restart ComfyUI.
Step 2: Download model files
Download the diffusion model wan2.1_vace_14B_fp16.safetensors and put it in ComfyUI > models > diffusion_models.
Download the text encoder model umt5_xxl_fp8_e4m3fn_scaled.safetensors and put it in ComfyUI > models > text_encoders.
Download the Wan VAE model wan_2.1_vae.safetensors and put it in ComfyUI > models > vae.
Step 3: Load the workflow
Download the workflow JSON file below and drop it into ComfyUI to load.
Step 4: Install missing nodes
If you see red blocks, you don’t have the custom node that this workflow needs.
Click Manager > Install missing custom nodes, and install the missing nodes.
Restart ComfyUI.
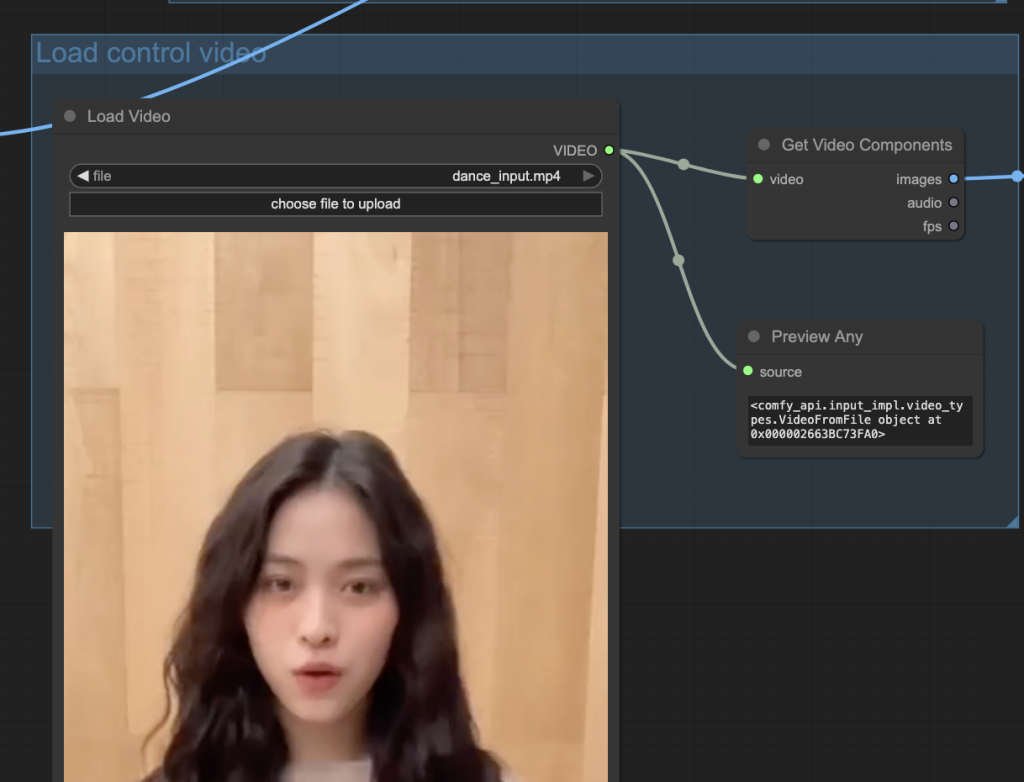
Step 5: Set the input video
Upload a reference video to the Load Video node.
I used this video on TikTok. You can download it using online tools like this one.
Step 6: Set the input reference image
This Wan VACE workflow requires an input reference image. Like the reference-to-video workflow, it copies the likeness of the image.
Upload the reference image to the Load Image node.
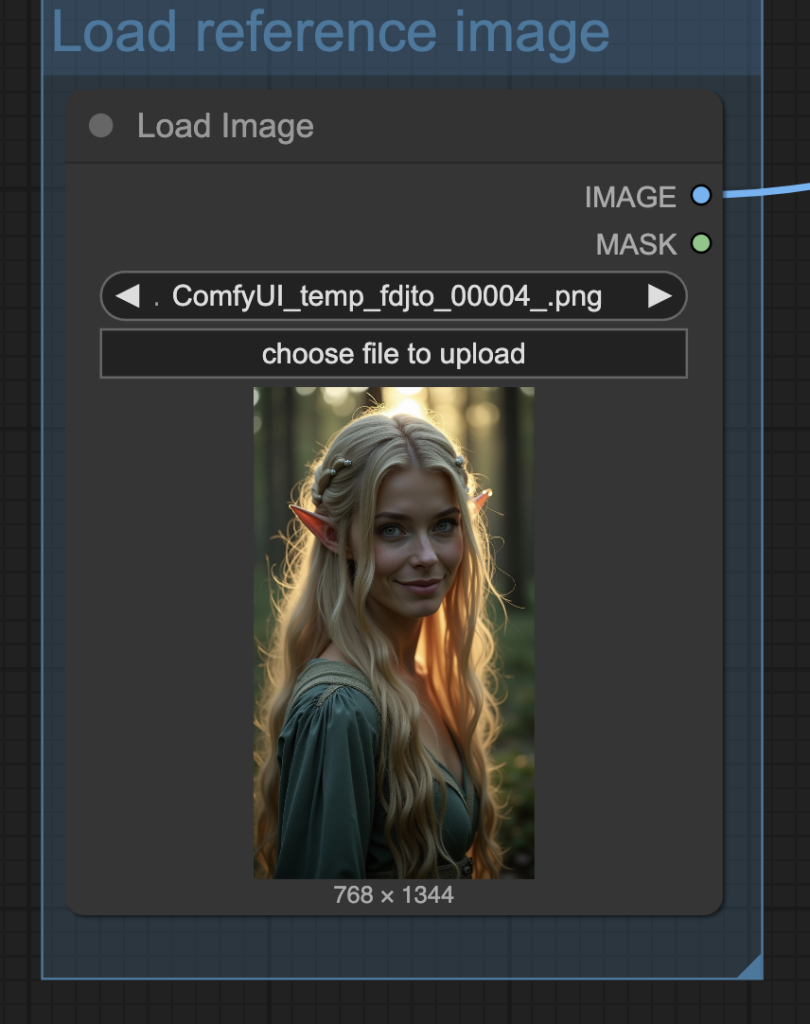
The image was generated using the Flux.1 Dev model with the following prompt.
close up portriat of a stunning, ethereal woman elf with flowing hair stands in an enchanted forest at twilight. Her beautiful eyes and face is clearly visible. Blonde, Danish. smile.
Below is the input reference image.

Step 7: Revise the prompt
Revise the prompt to describe the video you want to generate. In the workflow, I have:
a stunning, ethereal woman elf with flowing hair stands in an enchanted forest at twilight. Her beautiful eyes and face is clearly visible. Blonde, Danish. smile. dancing,
Some tips:
- Describe what the subject is doing.
- Add action words, e.g., laugh, run, fight, etc.
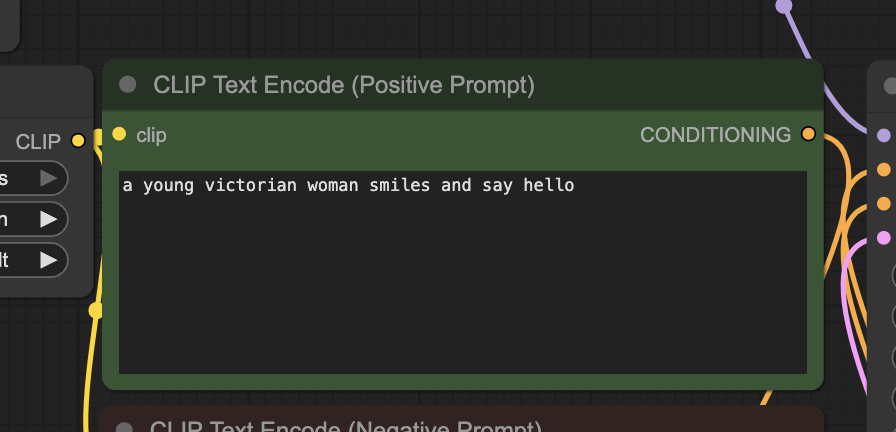
Step 8: Generate the video
Click the Run button to run the workflow.

Tips for using the Wan VACE V2V model
Out-of-memory
High-resolution and long video lengths can cause an out-of-memory error during generation. If you see an “allocation on device” error, reduce the width, height, or length parameter in the WanVaceToVideo node.
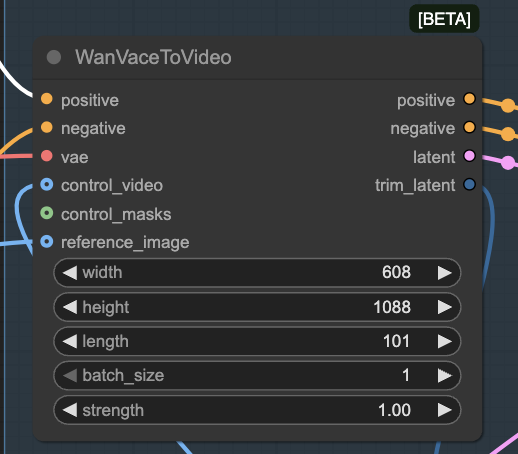
Video resolution
The Wan 2.1 VACE 14B model supports resolution from 480p to 720p.
Here are some commonly used resolutions:
- 480 p (SD)
- 640 × 480 (4:3)
- 854× 480 (16:9)
- 720p (HD)
- 960 x 720 (4:3)
- 1280 × 720 (16:9)
To set the video resolution, change the width and height of the WanVaceToVideo node.
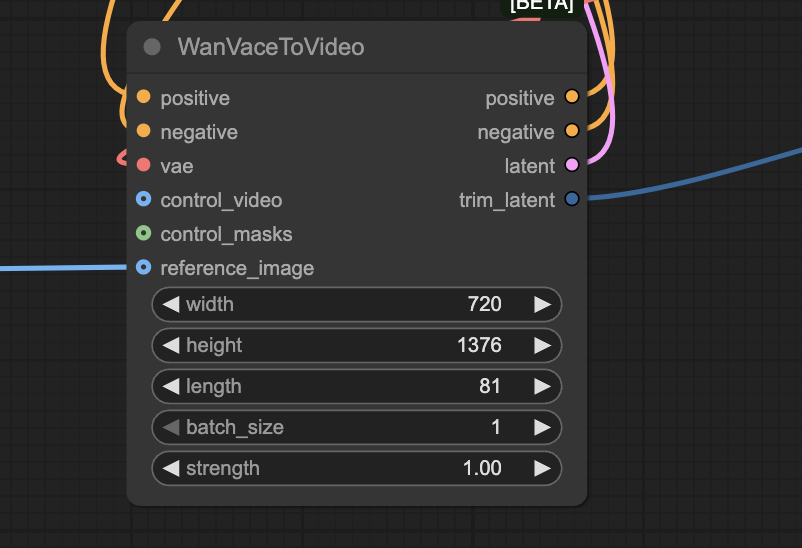
Reducing the resolution is an effective way to speed up image generation.
Seed
Change the seed value in the KSampler node to generate a new video.
Great tutorial—very clear and detailed 👍 The step-by-step breakdown makes running Wan VACE V2V in ComfyUI much easier to follow, especially the tips on resolution, memory limits, and generation time. Really helpful for anyone trying video-to-video locally.
Привет Андрей! Подскажи пожалуйста, у меня на питон 3.12 не устанавливается Тритон. Что мне делать?
that depends on your setup. Try triton-windows if you are on windows. But triton is known to be not compatible with some popular packages.
Thanks, Andrew, the Colab notebook doesn’t seem to load the vace model, only the other Wan models
It should be working now.
Thanks, Andrew.
I used Colab A100 and a 3:4 Flux image with your video as starters. Generation of a 4 sec video at 16 fps took 16 mins at 720×960 and 7 mins at 544×720 (3:4).
The video quality seems very good and there was only a slight dropoff in quality at the lower resolution.