
Lip sync is notoriously tricky to get right with AI because we naturally talk with body movement. OmniHuman-1 is a human video generation model that can generate lip sync videos from a single image and an audio clip. The motion is highly realistic and matches the voice.
OmniHuman-1 is currently only available through an online service. In this tutorial, I will show you how to access the service and generate a free lip sync video.
Table of Contents
OmniHuman-1 model
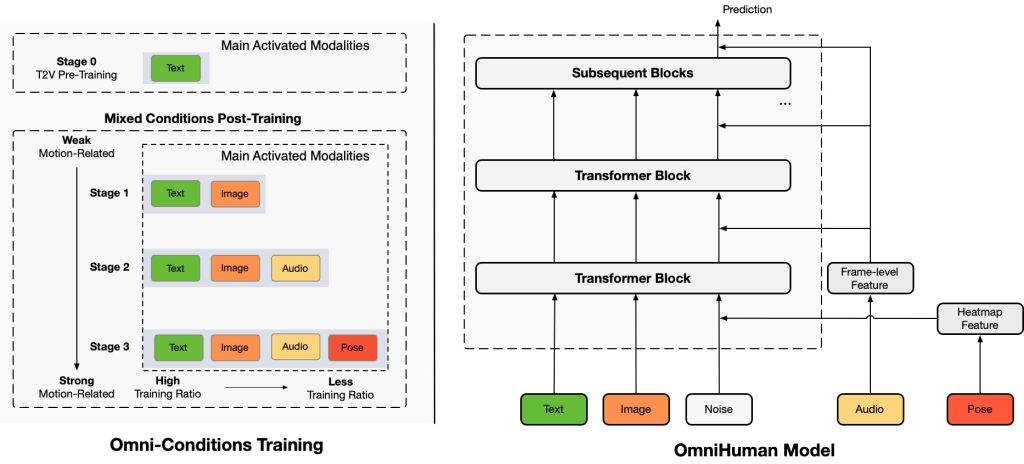
OmniHuman-1 is built around a unified Diffusion Transformer backbone that learns to turn a static reference image and motion cues (such as audio) into a realistic human video. It starts from a pre-trained text-to-video model (Seaweed/MMDiT) and simultaneously handles multiple types of conditioning signals.
OmniHuman-1 integrates appearance, lip movement, gestures, and full-body motion in a single end-to-end network.
It employs an innovative three-stage “omni-conditions” training:
- Learning general motions from text
- Refining lip sync and head movements from audio
- Mastering full-body dynamics from pose information.
This design allows the model to leverage massive datasets, resulting in lifelike videos that sync speech, gestures, and object interactions.
OmniHuman-1 lip sync videos
The advantages of the OmniHuman-1 model are:
- Realistic human motion matching the audio input – speech, singing, etc.
- Arbitrary video length.
- Animating diverse image styles – realistic photo, anime, painting, etc.
Generate OmniHuman-1 videos
The OmniHuman-1 model is currently available on CapCut’s Dreamina video generation service.
Step 1: Access the video service
Visit Dreamina from CapCut.
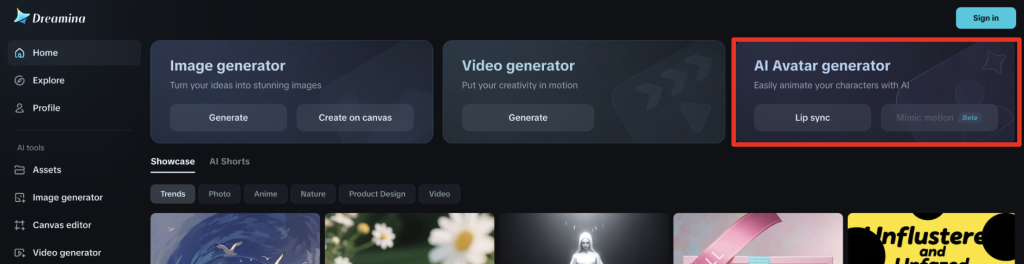
Select Lip Sync under the AI Avatar generator.
You can create or use an existing CapCut account to log in.
You should have enough free credits to generate a lip sync video.
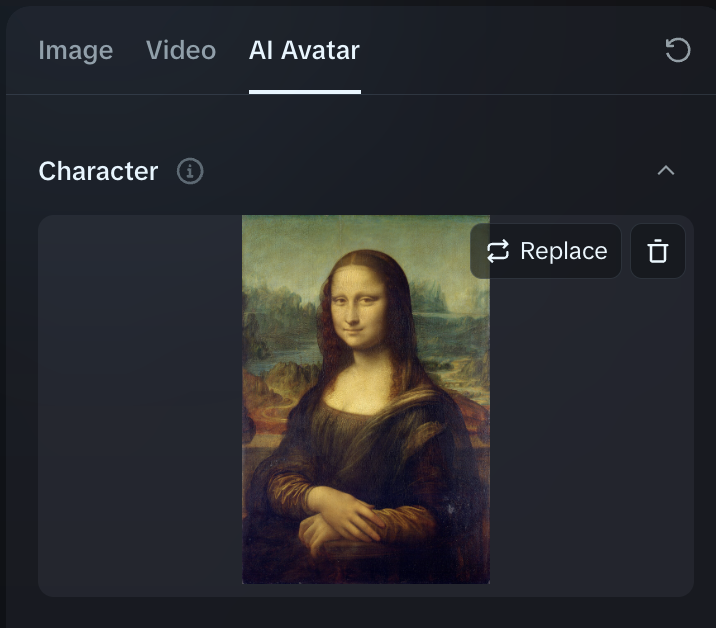
Step 2: Upload an image
Upload an image you want to animate to the Character image canvas.
{kind=link}
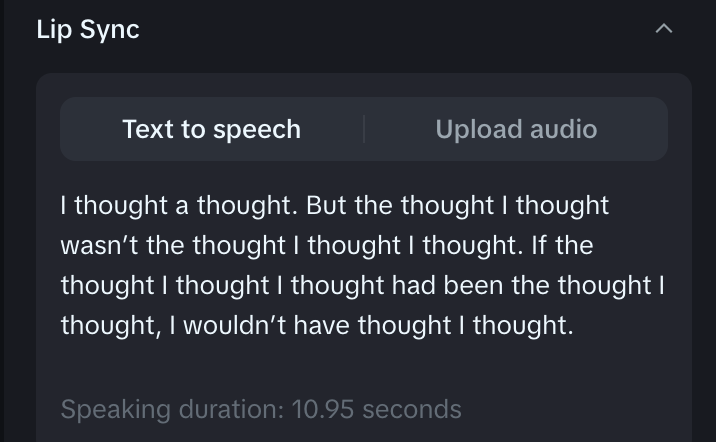
Step 3: Enter the lip sync speech
Enter a speech you want the character to say. For example:
I thought a thought. But the thought I thought wasn’t the thought I thought I thought. If the thought I thought I thought had been the thought I thought, I wouldn’t have thought I thought.
Step 4: Select a voice
Choose a voice you like under text-to-speech.

Step 5: Generate a video
Click Generate.
AI Avatar generator is disabled, do you know if there are restrictions that apply per country or region? Or is it temporarily disabled for everyone?
It doesn’t work for me either. The lipsync button is greyed out.
Interesting. Mine is still working (US).
Thanks for introducing this to us, Andrew, it’s a really interesting and high quality model. I’d say it’s better than the Kling 1.6 and 2.0 models with lip synch in terms of the naturalness of the face while speaking. On a couple of tries it doesn’t seem to do as well as those models in retaining movement of the body or other movement in the scene, though, and perhaps needs more active prompting of those elements. Queueing time is ~40 mins on the free plan – I’d hope it was much less on the paid plans and interested from anyone subscribing to hear if that’s the case.
The image generation section of the Dreamina site also seems good. They have a model called Seedream 3.0 which seems as good as flux dev on some of my prompts.