This workflow generates an animated face video in a polygon art style.
You need to be a member of this site to download the ComfyUI workflow.
Table of Contents
Software
Stable Diffusion GUI
We will use ComfyUI, a node-based Stable Diffusion GUI. You can use ComfyUI on Window/Mac or Google Colab.
Check out Think Diffusion for a fully managed ComfyUI/A1111/Forge online service. They offer 20% extra credits to our readers. (and a small commission to support this site if you sign up)
See the beginner’s guide for ComfyUI if you haven’t used it.
Use the L4 runtime type to speed up the generation if you use my Google Colab notebook.
How this workflow works
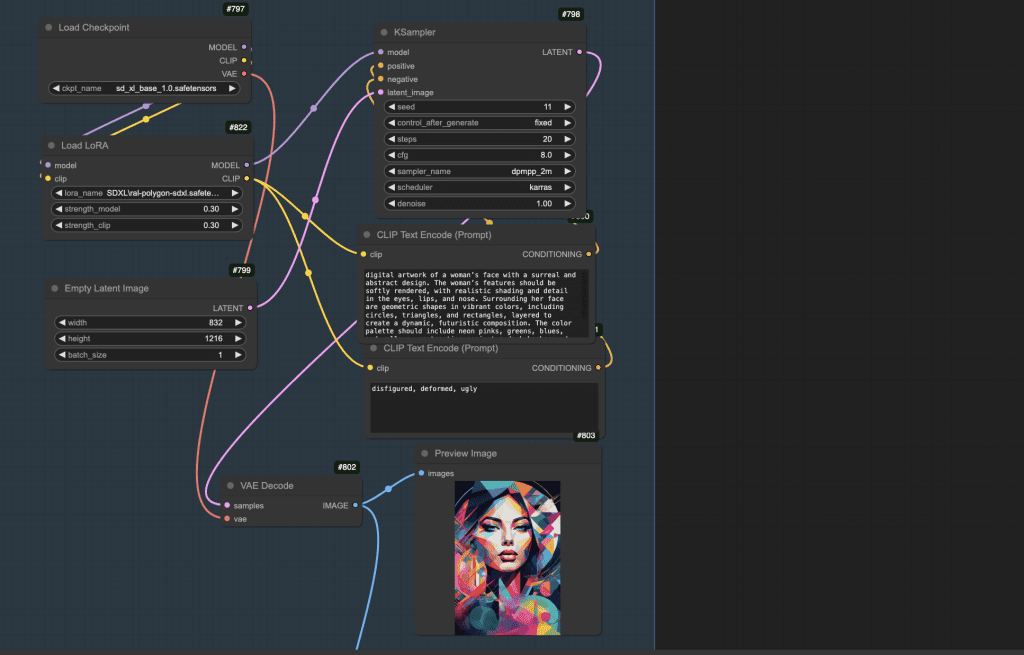
Reference image generation
This workflow first generates a reference image for the video using an SDXL model and a LoRA.
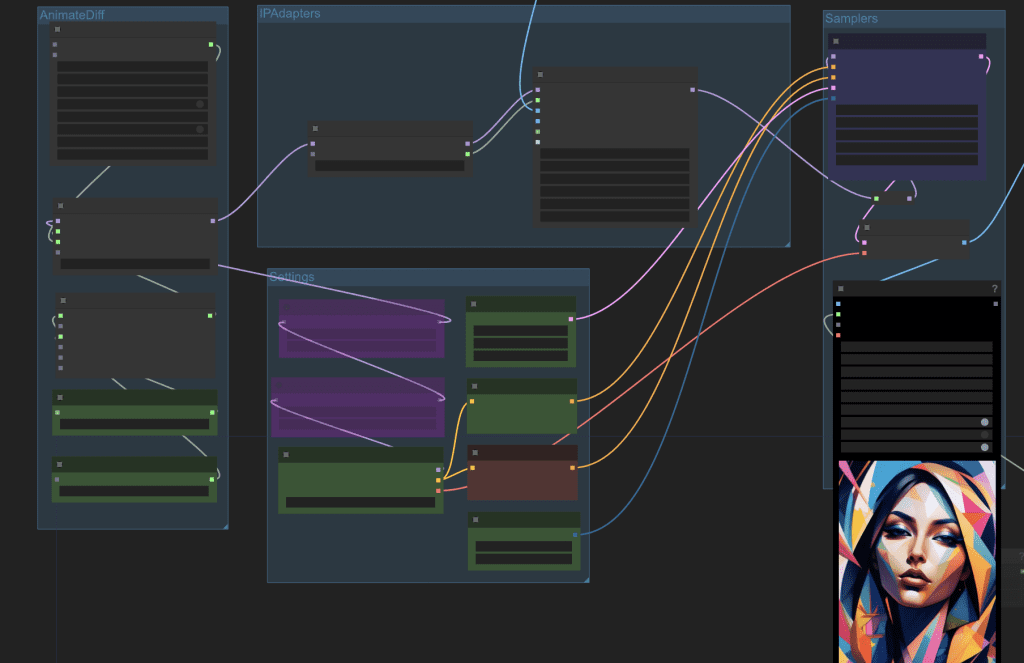
Video generation
The video is AnimateDiff with an SD 1.5 model. IP adapter injects the reference image during image generation. The prompt is left empty so that the video generation is only controlled by the image.
Post-processing
After generating the video with Stable Diffusion, you can optionally (All nodes are in the workflow)
- Upscale the video to a higher resolution.
- Make the video smoother by interpolating the frames.
- Add audio to the video.
- Correct color balance.
Step-by-step guide
Step 1: Load the ComfyUI workflow
Download the workflow JSON file below. You must be a member and log in to do so.
Drag and drop it to ComfyUI to load.
Step 2: Install Missing nodes
You may see a few red nodes in the workflow. That means you are missing some custom nodes needed for this workflow.
First, install ComfyUI manager if you haven’t already.
Click the Manager button on the top bar.

In the popup menu, click Install Missing Custom Nodes. Install the missing custom nodes on the list.
Restart ComfyUI. Refresh the ComfyUI page.
If you still see red nodes, try Update All in the ComfyUI manager’s menu.
Step 3: Download models
The following models are needed for this workflow.
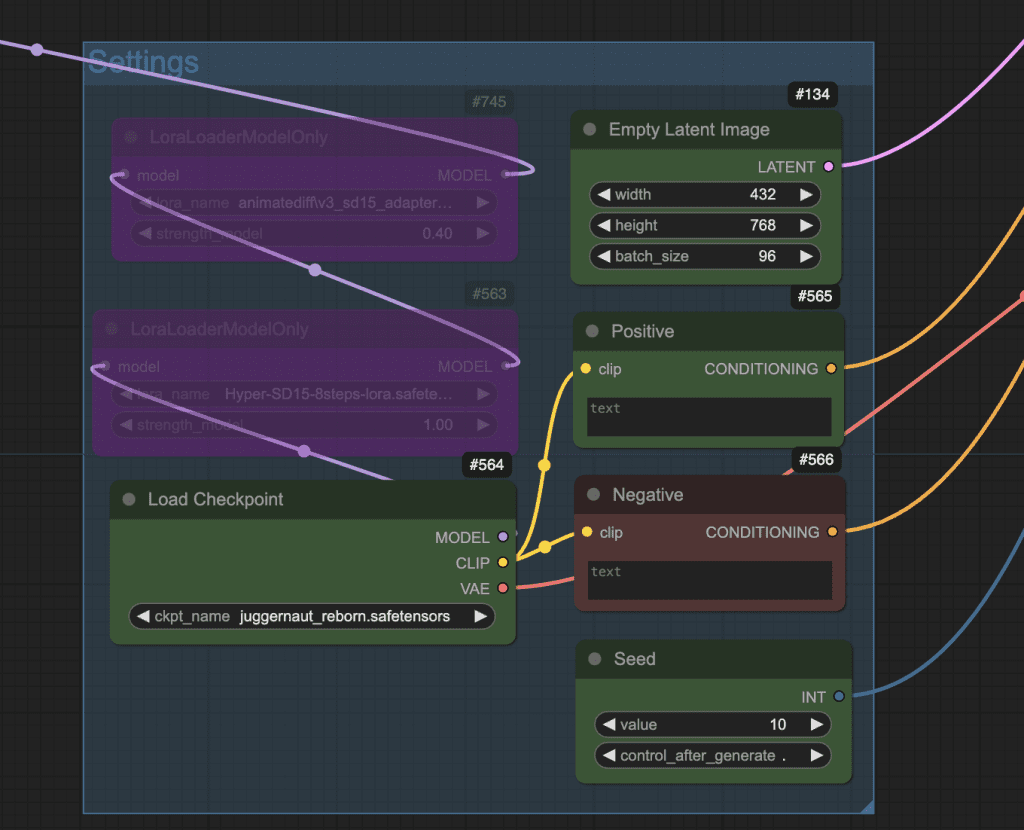
Checkpoint models
Download the Juggernaut Reborn (SD 1.5) model. Put it in ComfyUI > models > checkpoints.
Refresh and select the model in the Load Checkpoint node in the Settings group.
Download the SDXL base model. Put it in ComfyUI > models > checkpoints.
Refresh and select the model in the Load Checkpoint node in the Images group.
(If you use my Colab notebook, the checkpoint models go to AI_PICS > models > Stable-Diffusion )
LoRA model
Download the Polygon Style SDXL LoRA. Put it in ComfyUI > models > loras.
IP adapter
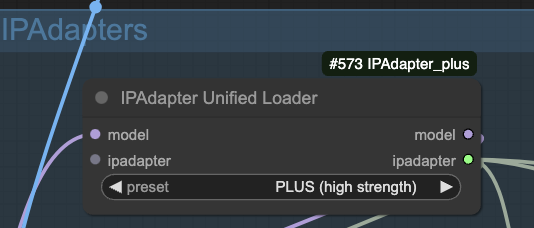
This workflow uses the IP-adapter to achieve a consistent face and clothing.
Download the SD 1.5 IP adapter Plus model. Put it in ComfyUI > models > ipadapter.
Download the SD 1.5 CLIP vision model. Put it in ComfyUI > models > clip_vision. Rename it to CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors to conform to the custom node’s naming convention.
These two models are needed for the IPAdapter Unified Loader node.
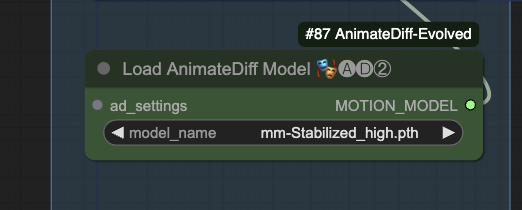
AnimateDiff
Download the AnimateDiff MM-Stabilized High model. Put it in ComfyUI > models > animatediff_models.
Refresh and select the model.
Upscaler
Download the 4x-Ultrasharp upscaler model. Put it in ComfyUI > models > upscale_models.
(If you use my Colab notebook: AI_PICS > models > ESRGAN )
Step 4: Generate video
Press Queue Prompt to start generating the video.
If you see an out-of-memory error, you can add the extra argument --disable-smart-memory to run_nvidia_gpu.bat.
.python_embededpython.exe -s ComfyUImain.py --windows-standalone-build --disable-smart-memoryCustomization
Style variation
Change the SD 1.5 checkpoint model in the Settings group to adjust the style.



Partial generation control
You can refine the partial workflow using the Fast group muter.
Disable the AnimateDiff group when you refine the prompts.
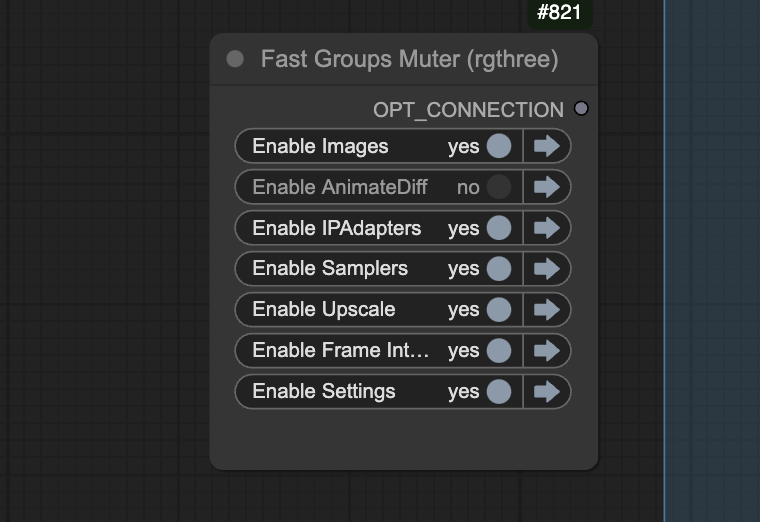
Disable the Upscale group when you work on the initial video, e.g. selecting a good seed.
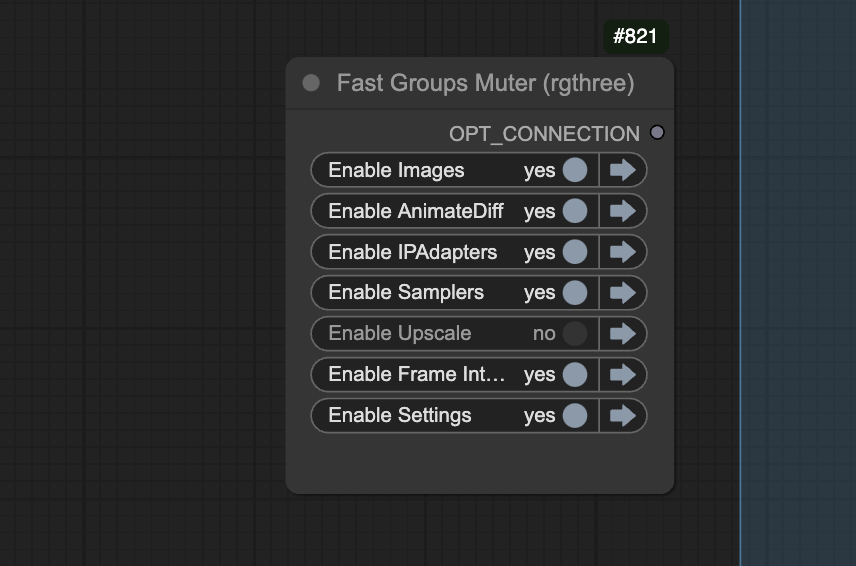
Seed
Changing the seed in the Settings group to generate a different video.
Video size
The video size is set to 432×768 for the native generation.
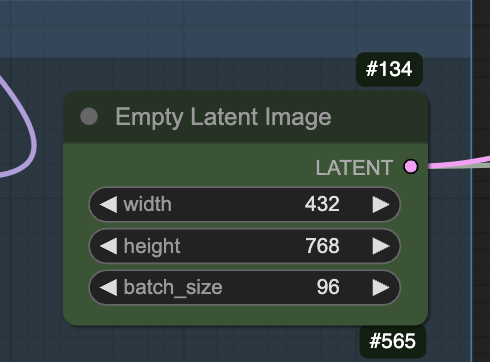
Change the aspect ratio to match what you want.
You can also reduce the width to as low as 256 px to speed up the generation. However, you will get fewer details.
Video length
The video is set to 96 frames in the following node.
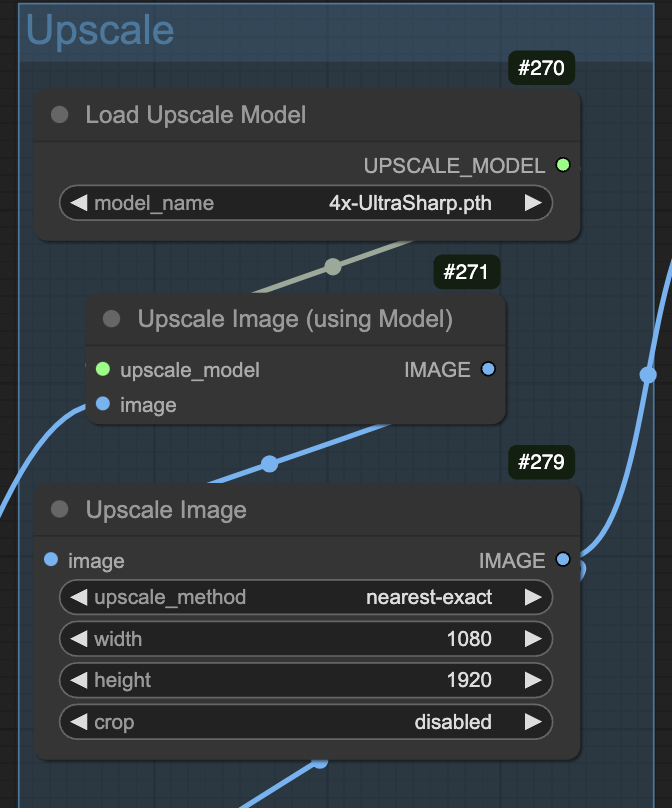
Upscaling
The size and models for upscaling are controlled by the following nodes. The upscale model has some effect on the style. You can pick one that works best for your artwork. See the upscaler tutorial for details.
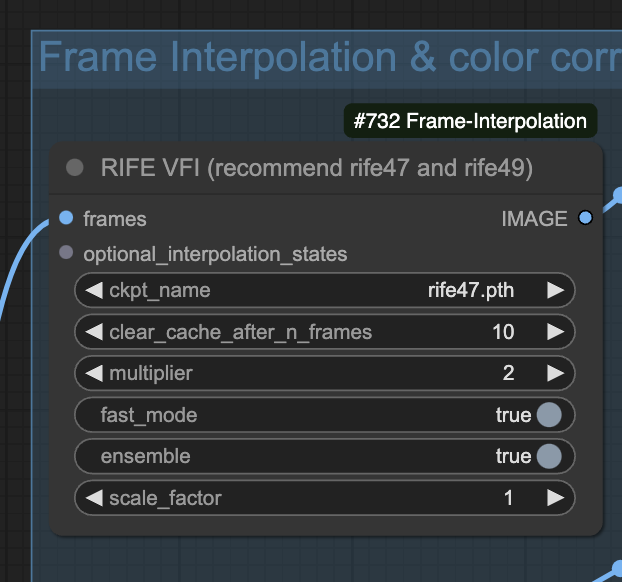
Frame interpolation
You can adjust the frame interpolation settings in the RIFE VFI node. It is set to doubling the frame rate (2) in this workflow.
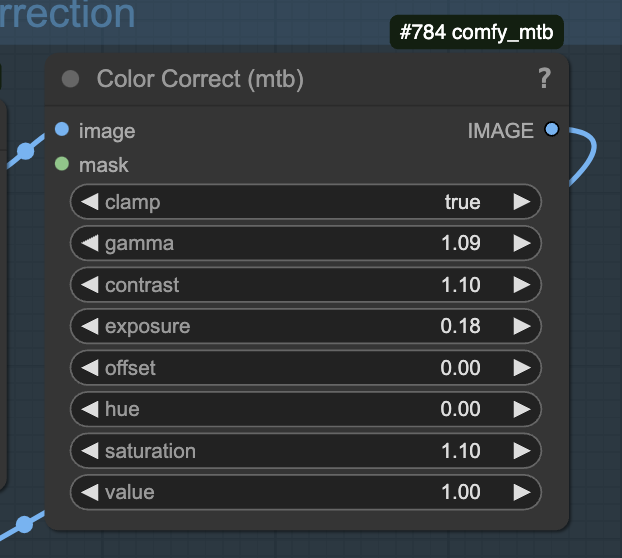
Color correction
You can use the Color Correct node to correct any color artifacts in the video.