- This topic has 7 replies, 2 voices, and was last updated 1 year, 4 months ago by
jszewczyk.
-
AuthorPosts
-
-
February 10, 2025 at 2:56 pm #17162
Hey
I have a question about many ways to load models in ComphUI like Load Diffusion Model, Load Checkpoint.
What advantage gives us weight dtype?
What’s the difference between loading Clip from Load Checkpoint and DualClipLoader?
What gives us that additional parameters?
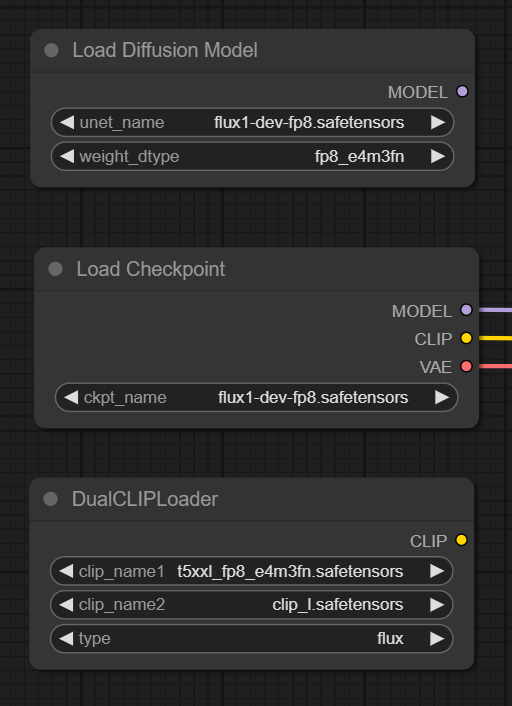
Thanks!
-
February 10, 2025 at 3:00 pm #17163
-
February 11, 2025 at 8:55 am #17195
Hi, we need three models to use a diffusion model like Stable Diffusion and Flux
Diffusion model – for denoising during sampling.
VAE – for converting the images between pixel and latent spaces.
CLIP – for encoding to text prompt for conditioning during sampling.
Some checkpoints include all three in a single checkpoint file. Even if others don’t, the Load Checkpoint node uses the default VAE and CLIP models.In addition to the original VAE, there are improved or finetuned versions, although they are rare. You can use the Load VAE node to specify the VAE you want. Typically, the difference is minimal.
Likewise, you can load the CLIP models directly using a node. Some models, like Flux, use two text encoders. Using the Dual CLIP loader allows you to put different text prompts to different encoders. Some people swear to see a difference between the two, but this remains an under-explored area.
-
February 11, 2025 at 8:59 am #17196
Hi, we need three models to use a diffusion model like Stable Diffusion and Flux
- Diffusion model – for denoising during sampling.
- VAE – for converting the images between pixel and latent spaces.
- CLIP – for encoding to text prompt for conditioning during sampling.
Some checkpoints include all three in a single checkpoint file. Even if others don’t, the Load Checkpoint node uses the default VAE and CLIP models.
In addition to the original VAE, there are improved or finetuned versions, although they are rare. You can use the Load VAE node to specify the VAE you want. Typically, the difference is minimal.
Likewise, you can load the CLIP models directly using a node. Some models, like Flux, use two text encoders. Using the Dual CLIP loader allows you to put different text prompts to different encoders. Some people swear to see a difference between the two, but this remains an under-explored area.
-
February 11, 2025 at 1:10 pm #17197
Generally, if I use FLUX better for doing modifications will be to add Lora Models than adding modifications by custom VAE and CLIP?
-
February 11, 2025 at 1:15 pm #17198
-
February 12, 2025 at 9:37 pm #17208
LoRA should be the go-to method for modifying models. A LoRA can also modify CLIP, but the main effect is in modifying the diffusion model.
I haven’t done a comparison, but sampling is a pretty standard process. I don’t think they would do anything different.
-
February 13, 2025 at 2:29 am #17221
Thanks. Great, I tested and XLabs looks like be slower, I will use a standard sampler If I don’t need controlnet.
-
-
AuthorPosts
- You must be logged in to reply to this topic.